O blog da AWS
Implantando modelos de IA para inferência com o AWS Lambda usando empacotamento zip
Por Ayush Kulkarni, Sr. Product Mgr Tech, AWS Lambda e Harold Sun, Software Developer III, AWS Lambda.
O AWS Lambda fornece um modelo de programação orientado por eventos, capacidade de escalar até zero e integrações com mais de 200 serviços da AWS. Isso pode torná-lo uma boa opção para aplicativos de inferência baseados em CPU que usam modelos leves e personalizados e são concluídos em 15 minutos.
Os usuários geralmente empacotam seu código de função como imagens de container ao usar modelos de aprendizado de máquina (ML) maiores que 250 MB, que é o limite de tamanho do pacote de implantação do Lambda para arquivos zip. Nesta publicação, demonstramos uma abordagem que baixa modelos de ML diretamente do Amazon S3 na memória da sua função para que você possa continuar empacotando seu código de função usando arquivos zip. Para otimizar a latência da inicialização sem implementar otimizações de desempenho em nível de aplicativo, usamos o Lambda SnapStart. O SnapStart é um recurso opcional disponível para funções Java, Python e .NET que otimiza a latência de inicialização — de 16,5 segundos para 1,6 segundos para a aplicação usada nesta publicação.
Arquitetura da aplicação
Nesta publicação, demonstramos como criar um chatbot usando uma versão quantizada de 4 bits do modelo DeepSeek-R1-Distill-QWEN-1.5b-gguf para inferência junto com a URL da função Lambda (FURL) e o Lambda Web Adapter (LWA) para transmitir respostas de texto. Um FURL é um endpoint HTTP (s) dedicado para sua função Lambda, e você pode usar o LWA, um projeto de código aberto disponível no AWS Labs, para estruturas de aplicativos web familiares (como FastAPI, Next.JS ou Spring Boot) com o Lambda. Para obter uma explicação detalhada de como essa arquitetura de streaming de respostas funciona, consulte esta publicação sobre computação da AWS.
Atualmente, as funções do Lambda são executadas em instâncias do Amazon Elastic Compute Cloud (Amazon EC2) baseadas em CPU que usam arquiteturas x86 e ARM64. Por esse motivo, você deve usar SDKs que permitam inferência de modelo de linguagem grande (LLM) em CPUs. Nesta publicação, também demonstramos como usar o projeto llama.cpp (por meio da biblioteca llama-cpp-python) e a estrutura web FastAPI para lidar com solicitações da web. Para usar modelos que excedam o limite de tamanho de pacote zip de 250 MB do Lambda, você pode baixá-los de um bucket do S3 durante a inicialização da função. A figura a seguir descreve essa arquitetura em detalhes.
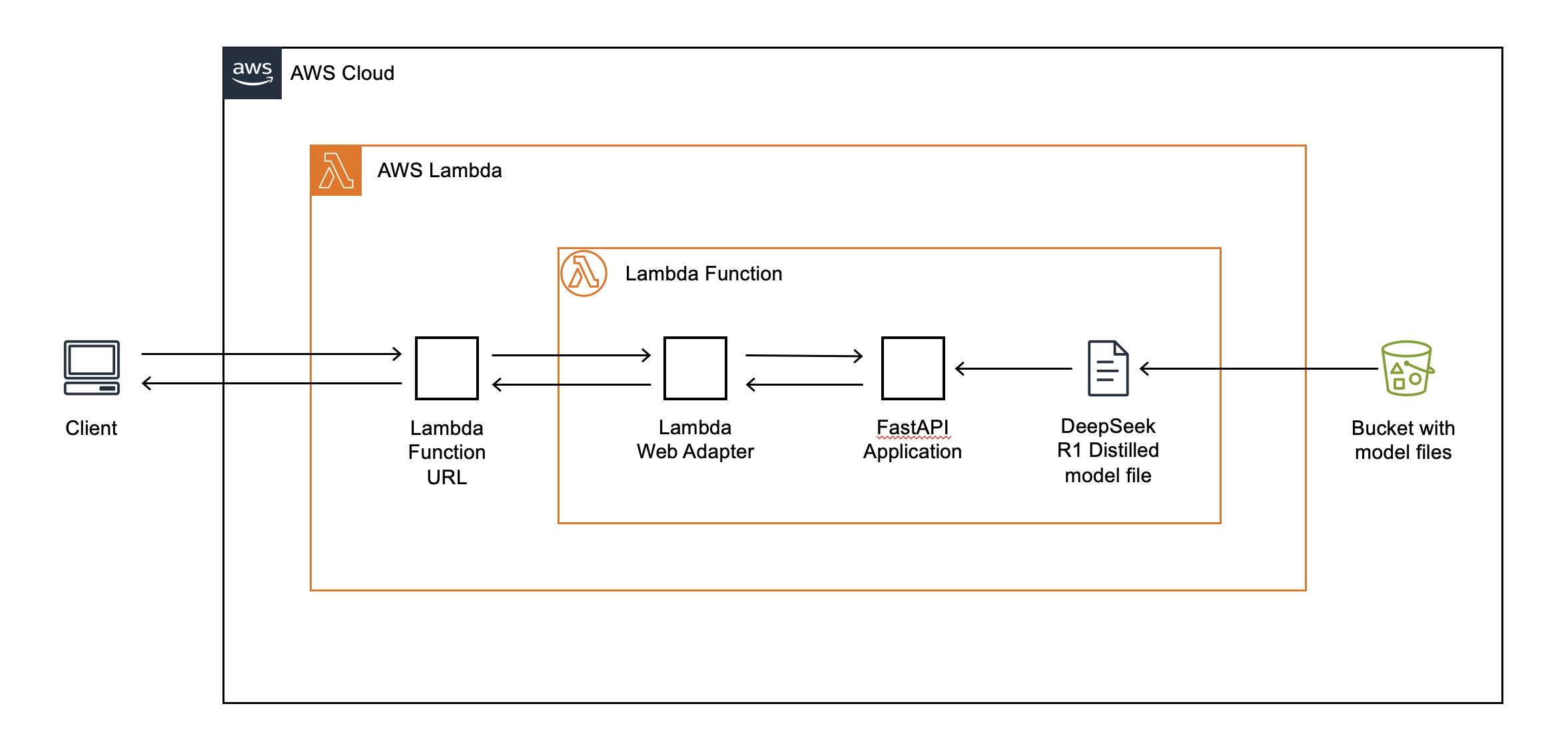
Figura 1: Arquitetura da aplicação
Você pode consultar esse repositório do GitHub para ver o código da aplicação usada neste exemplo.
Baixando modelos de ML durante a inicialização da função
Como alternativa ao empacotamento de modelos de ML usando imagens de container OCI, você pode baixá-los de um armazenamento durável, como o Amazon S3, durante a inicialização. Inicialização (ou INIT) se refere à fase em que o Lambda baixa o código da função, inicia o tempo de execução da linguagem e executa o código de inicialização da função, que é um código fora do handler. Carregar arquivos grandes diretamente na memória pode ser mais rápido do que primeiro baixá-los para o disco e depois carregá-los na memória. Para fazer isso, você pode usar um recurso Linux chamado memfd, para baixar diretamente o modelo de ML do Amazon S3 diretamente na memória, fazendo referência a ele usando um descritor de arquivo padrão. É necessário referenciar o modelo usando um descritor de arquivo para que o llama.cpp importe o modelo com sucesso. Isso é composto por duas etapas.
Primeiro, crie um descritor de arquivo somente para memória:
Em seguida, baixe o modelo no arquivo mapeado na memória referenciado pelo descritor de arquivo criado anteriormente.
Consultando o chatbot
Depois de implantar nosso aplicativo de chatbot de exemplo, começamos a interagir com ele.
A primeira consulta ao chatbot resulta na inicialização de um novo ambiente de execução. Quando o Lambda executa o código de inicialização descrito na seção anterior, seu modelo de ML é baixado diretamente do Amazon S3 para a memória da função. Depois disso, o Lambda executa o método handler da função. Observando o segmento de rastreamento do X-Ray na figura a seguir, observamos que o primeiro Init expira após 10 segundos. O segundo Init é concluído em 16,68 segundos. Além disso, o primeiro Init expira porque o Lambda limita a duração dessa fase a 10 segundos. Se o Init demorar mais do que isso, o Lambda o tentará novamente durante a invocação da função, aplicando o tempo limite de duração de execução configurado da função.
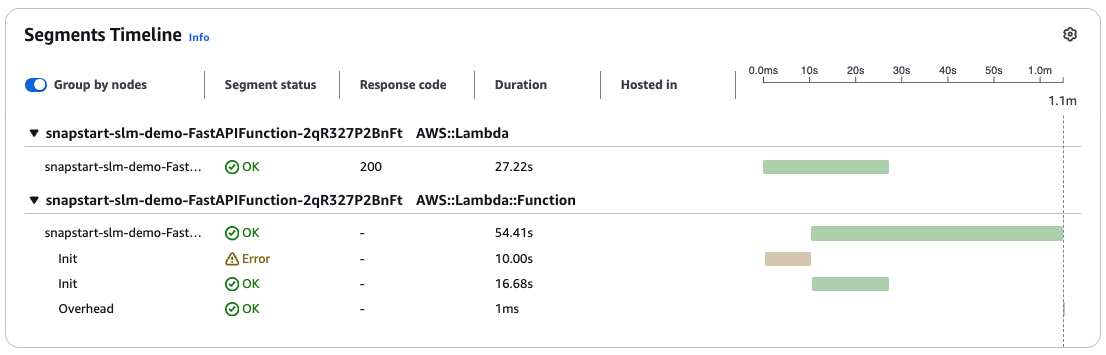
Figura 2: Duração inicial, indicada pelo segmento de rastreamento do AWS X-Ray
Otimizando o desempenho da inicialização com o SnapStart
Para otimizar a latência de inicialização da função, você pode usar o Lambda SnapStart. O SnapStart foi projetado para otimizar a latência de inicialização decorrente do código de inicialização de funções de longa execução. O Lambda usa o SnapStart para inicializar sua função quando você publica uma versão da função, conforme mostrado na figura a seguir. Em seguida, o Lambda tira um snapshot do Firecracker microVM da memória e do estado do disco do ambiente de execução inicializado, criptografa o snapshot e o armazena em cache de forma inteligente para otimizar a latência de recuperação.
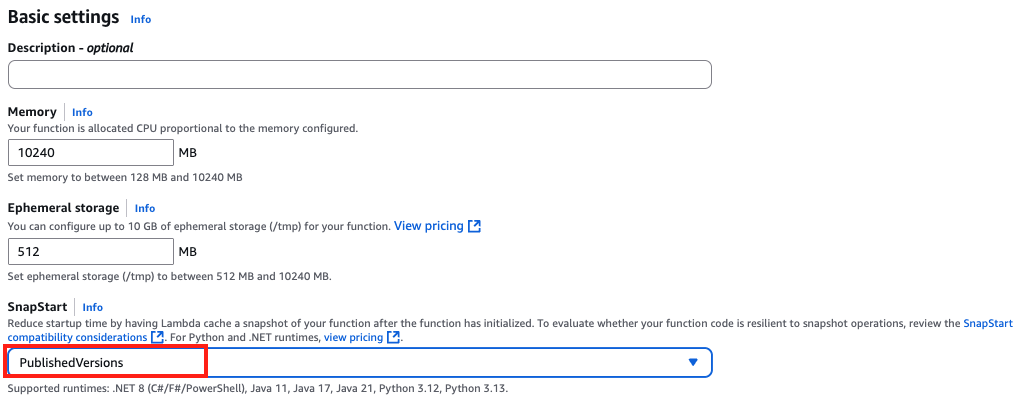

Figura 3: Habilitando o SnapStart
Consultar o chatbot novamente mostra uma aceleração significativa na latência de inicialização. Você pode verificar isso visualizando o Amazon CloudWatch Logs da sua função e pesquisando a linha de log “RESTORE_REPORT”, conforme mostrado na figura a seguir. Para o aplicativo de exemplo usado, a duração da restauração é de 1,39 segundos. Essa é uma melhoria considerável em relação à duração inicial de 16,68 segundos. Os resultados de desempenho podem variar. Mas o melhor de tudo é que você não precisa alterar uma única linha de código para obter essa melhoria!

Figura 4: Alcançando uma latência de inicialização mais rápida com o SnapStart
Ajustando o desempenho da inferência
O desempenho da inferência depende dos recursos de CPU alocados para sua função. O Lambda aloca a potência da CPU proporcionalmente à quantidade de memória configurada para sua função. Alocar mais memória resulta em resultados de inferência mais rápidos, medidos pela taxa na qual os tokens de prompt são avaliados (tokens avaliados por segundo) e pela taxa na qual os tokens de saída são produzidos (tokens gerados por segundo). Neste exemplo, alocamos o máximo — em outras palavras, 10 GB de memória — para maximizar o desempenho. Os resultados de desempenho obtidos em outras configurações de tamanho de memória estão incluídos na tabela a seguir. Como mostra a tabela, dobrar a memória alocada de 5 GB para 10 GB resulta em uma melhoria de 83% nos tokens avaliados e gerados (por segundo), com um aumento de apenas 24% nos GB-segundos cobrados. Os resultados de desempenho podem variar. Consulte o código de exemplo para ver o desempenho do instrumento em diferentes tamanhos de memória.
| Tamanho da memória (MB) | Tokens avaliados por segundo |
Tokens gerados por segundo |
Duração cobrada (ms) |
Faturado GB-segundos |
| 10240 | 44,68 | 29,53 | 36.660 | 36,60 |
| 9216 | 41,67 | 26,77 | 37.690 | 339,21 |
| 8192 | 37,17 | 22.05 | 44.298 | 354,38 |
| 7168 | 33,67 | 21,78 | 44.818 | 313,73 |
| 614 | 28,89 | 18,43 | 52.579 | 315,47 |
| 5120 | 24,41 | 16.07 | 59.036 | 295,18 |
| 4096 | 19.07 | 12,94 | 72.648 | 290,59 |
| 3072 | 13,39 | 9,20 | 101.468 | 304,40 |
| 2048 | 10.01 | 6,7 | 135.862 | 271,72 |
Tabela 1: Desempenho de inferência em diferentes tamanhos de memória
Entendendo como os custos das aplicações aumentam com o uso
Para estimar o custo de execução dessa carga de trabalho, começamos fazendo algumas suposições sobre nossos padrões de tráfego. Estimamos cerca de 30.000 chamadas de inferência por mês para nossa função Lambda, com cada chamada de inferência com duração média de 10 segundos. Definimos a memória funcional para 10 GB, porque ela representa a relação preço-desempenho ideal para nosso caso de uso. Implantamos nosso aplicativo na região da AWS US-West-2 (Oregon). Inicialmente, como nosso número de invocações é baixo, assumimos uma taxa de inicialização a frio de 5%. Em outras palavras, 5% das invocações resultam em uma inicialização a frio quando um novo ambiente de execução é criado. Ao usar o SnapStart com o tempo de execução do Python gerenciado pelo Lambda, você é cobrado pelo armazenamento em cache do instantâneo da função e pela restauração da execução do instantâneo da função.
Com esses parâmetros, a fatura mensal do Lambda é de $91,1, calculada conforme mostrado na tabela a seguir. Os custos mensais mostrados na tabela são apenas ilustrativos.
| Cobrar | Cálculo | Custo mensal |
| Computar | 30.000 inferências * 10 segundos por inferência * 10 GB (memória configurada) * 0,00001667 USD por GB-segundo | $50,01 |
| Solicitações | 0,2 USD por milhão de solicitações* 30.000 inferências | $0,006 |
| SnapStart — Cache | Memória funcional de 10 GB * 2,59 milhões de GB-segundos por mês * 0,0000015046 USD por GB-segundo | $38,99 |
| SnapStart — restauração | Memória funcional de 10 GB* 0,0001397998 USD por GB de restauração* 1500 arranques a frio | $2,09 |
| Total | Computação + Solicitações + Cache do SnapStart + Restauração do SnapStart | $91,1 |
Com um baixo volume de invocações, as cobranças adicionais do SnapStart representam aproximadamente 50% do custo mensal total. Por esse custo adicional, a latência de inicialização a frio é reduzida de 16,68 segundos para 1,39 segundos, sem a necessidade de implementar otimizações complexas por conta própria. Podemos demonstrar como esses custos aumentam com o uso. Presumimos que nosso chatbot cresce em popularidade com o aumento do tráfego 10 vezes para 300.000 chamadas de inferência mensais. Embora as taxas de inicialização a frio para funções individuais do Lambda possam variar devido a vários fatores, a reutilização de ambientes de execução pelo Lambda geralmente resulta na diminuição das taxas de inicialização a frio com o maior volume de tráfego. Para fins deste exemplo, presumimos que nossa taxa de inicialização a frio caia para 1% de todas as invocações com o crescimento de 10 vezes no tráfego. Com essas suposições, nossa fatura mensal do Lambda com um volume de tráfego 10 vezes maior é de $543,3. As cobranças adicionais do SnapStart agora constituem menos de 10% de nossa fatura total, conforme mostrado na tabela a seguir. Os custos mensais mostrados nesta tabela são apenas ilustrativos.
| Cobrar | Cálculo | Custo mensal |
| Computar | 300.000 inferências * 10 segundos por inferência * 10 GB (memória configurada) * 0,00001667 USD por GB-segundo | $500,01 |
| Solicitações | 0,2 USD por milhão de solicitações* 300.000 inferências | $0,06 |
| SnapStart — Cache | Memória funcional de 10 GB * 2,59 milhões de GB-segundos por mês * 0,0000015046 USD por GB-segundo | $38,99 |
| SnapStart — restauração | Memória funcional de 10 GB* 0,0001397998 USD por GB de restauração* 3000 arranques a frio | $4,18 |
| Total | Computação + Solicitações + Cache do SnapStart + Restauração do SnapStart | $543,24 |
Considerações
As funções lambda são executadas em instâncias EC2 baseadas em CPU. Se seus modelos de ML precisarem de inferência baseada em GPU, LLMs fundamentais ou excederem os limites do Lambda na duração da execução (15 minutos) e na memória funcional (10 GB), você poderá usar o AWS Machine Learning, a AWS Generative AI ou os serviços de computação da AWS.
Além disso, você deve saber o seguinte sobre o Lambda SnapStart:
Tratamento de unicidade: Se seu código de inicialização gera conteúdo único que é incluído no snapshot, então este conteúdo não será único quando for reutilizado em diferentes ambientes de execução. Para manter a unicidade ao usar o SnapStart, você deve gerar conteúdo único após a inicialização, como nos casos em que seu código usa geração personalizada de números aleatórios que não depende de bibliotecas nativas, ou armazena em cache qualquer informação como entradas DNS que possam expirar durante a inicialização. Para saber como restaurar a unicidade, consulte Tratamento de unicidade com Lambda SnapStart no Guia do Desenvolvedor do Lambda.
Ajuste de desempenho: para maximizar o desempenho, recomendamos que você pré-carregue dependências e inicialize recursos que contribuam para a latência de inicialização em seu código de inicialização em vez de no manipulador (handler) de funções. Isso move a latência associada a essas operações durante a publicação da versão, em vez de durante a invocação da função, e pode gerar um desempenho de inicialização mais rápido. Para saber mais, acesse Ajuste de desempenho do Lambda SnapStart no Guia do desenvolvedor do Lambda.
Melhores práticas de rede: o estado das conexões que sua função estabelece durante a fase de inicialização não é garantido quando o Lambda retoma sua função a partir de um snapshot. Na maioria dos casos, as conexões de rede estabelecidas por um SDK da AWS são retomadas automaticamente. Para outras conexões, consulte as melhores práticas de rede para o Lambda SnapStart no Lambda Developer Guide.
Conclusão
Nesta publicação, demonstramos como você pode baixar modelos de ML diretamente do Amazon S3 na memória da sua função, permitindo que você implante suas funções do AWS Lambda usando pacotes zip. Para otimizar a latência da inicialização sem implementar otimizações de desempenho em nível de aplicativo, também demonstramos o uso do Lambda SnapStart, um recurso opcional disponível para Java, Python e .NET. Para o aplicativo usado nesta publicação, o SnapStart reduziu a latência de inicialização de 16,68 s para 1,39 s.
Para saber mais sobre o Lambda, consulte nossa documentação. Para obter detalhes sobre o Lambda SnapStart, consulte nossas postagens de lançamento para Java, Python e .Net e a documentação.
Você pode consultar esse repositório do GitHub para ver o código do aplicativo usado neste exemplo.
Este conteúdo foi traduzido da publicação original do blog, que pode ser encontrada aqui.
Autores
 |
Ayush Kulkarni, Sr. Product Mgr Tech, AWS Lambda |
 |
Harold Sun, Software Developer III, AWS Lambda |
Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Revisor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |