O blog da AWS
Mergulhe profundamente nos armazenamentos de dados vetoriais usando as Bases de Conhecimento do Amazon Bedrock
Este post foi escrito por Vishwa Gupta, Isaac Privitera, Abhishek Madan ,Ginni Malik e Satish Sarapuri.
Clientes de todos os setores estão experimentando a IA generativa para acelerar e melhorar os resultados comerciais. A IA generativa é usada em vários casos de uso, como criação de conteúdo, personalização, assistentes inteligentes, perguntas e respostas, resumo, automação, eficiência de custos, assistentes de melhoria de produtividade, personalização, inovação e muito mais..
As soluções de IA generativa geralmente usam arquiteturas de geração aumentada de recuperação (RAG), que usam as fontes externas de conhecimento para melhorar a qualidade do conteúdo, a compreensão do contexto, a criatividade, a adaptabilidade do domínio, a personalização, a transparência e a explicabilidade..
Esta publicação se aprofunda nas Bases de Conhecimento do Amazon Bedrock, que ajudam no armazenamento e na recuperação de dados em bancos de dados vetoriais para fluxos de trabalho baseados em RAG, com o objetivo de melhorar as respostas do modelo de linguagem grande (LLM) para inferência envolvendo os conjuntos de dados de uma organização.
Benefícios dos armazenamentos de dados vetoriais
Vários desafios surgem ao lidar com cenários complexos que lidam com dados, como volumes de dados, multidimensionalidade, multimodalidade e outras complexidades de interface. Por exemplo:
- Dados como imagens, texto e áudio precisam ser representados de forma estruturada e eficiente.
- Compreender a semelhança semântica entre os pontos de dados é essencial em tarefas de IA generativa, como processamento de linguagem natural (PNL), reconhecimento de imagem e sistemas de recomendação.
- À medida que o volume de dados continua crescendo rapidamente, a escalabilidade se torna um desafio significativo.
- Os bancos de dados tradicionais podem ter dificuldades para lidar com eficiência com as demandas computacionais de tarefas de IA generativa, como treinar modelos complexos ou realizar inferências em grandes conjuntos de dados.
- Os aplicativos de IA generativa frequentemente exigem a pesquisa e a recuperação de itens ou padrões semelhantes em conjuntos de dados, como encontrar imagens semelhantes ou recomendar conteúdo relevante.
- As soluções de IA generativa geralmente envolvem a integração de vários componentes e tecnologias, como estruturas de aprendizado profundo, pipelines de processamento de dados e ambientes de implantação.
Os bancos de dados vetoriais servem como base para atender a essas necessidades de dados para soluções de IA generativa, permitindo representação eficiente, compreensão semântica, escalabilidade, interoperabilidade, pesquisa e recuperação e implantação de modelos. Eles contribuem para a eficácia e viabilidade de aplicações de IA generativa em vários domínios. Os bancos de dados vetoriais oferecem os seguintes recursos:
- Forneça um meio de representar dados de forma estruturada e eficiente, permitindo o processamento e a manipulação computacionais.
- Permita a medição da similaridade semântica codificando dados em representações vetoriais, permitindo comparação e análise.
- Gerencie conjuntos de dados em grande escala de forma eficiente, permitindo o processamento e a análise de grandes quantidades de informações de forma escalável.
- Forneça uma interface comum para armazenar e acessar representações de dados, facilitando a interoperabilidade entre diferentes componentes do sistema de IA.
- Ofereça suporte a operações eficientes de busca e recuperação, permitindo a exploração rápida e precisa de grandes conjuntos de dados
Para ajudar a implementar aplicativos generativa baseados em IA com segurança em grande escala, a AWS fornece o Amazon Bedrock, um serviço totalmente gerenciado que permite a implantação de aplicativos de IA generativa que usam LLMs de alto desempenho das principais startups de IA e da Amazon. Com a experiência sem servidor do Amazon Bedrock, você pode experimentar e avaliar os principais modelos básicos (FMs) para seus casos de uso, personalizá-los de forma privada com seus dados usando técnicas como ajuste fino e RAG e criar agentes que executem tarefas usando sistemas corporativos e fontes de dados.
Nesta postagem, vamos nos aprofundar nas opções de banco de dados vetoriais disponíveis como parte das Bases de Conhecimento do Amazon Bedrock e nos casos de uso aplicáveis, e analisamos exemplos de códigos funcionais. Bases de Conhecimento do Amazon Bedrock permite um tempo de lançamento mais rápido no mercado ao se abstrair do trabalho pesado de construir pipelines e fornecer a você uma solução RAG pronta para usar para reduzir o tempo de criação de seu aplicativo.
Sistemas de base de conhecimento com RAG
O RAG otimiza as respostas do LLM referenciandBases de conhecimento confiáveis fora de suas fontes de dados de treinamento antes de gerar uma resposta. Prontos para uso, os LLMs são treinados em grandes volumes de dados e usam bilhões de parâmetros para gerar resultados originais para tarefas como responder perguntas, traduzir idiomas e completar frases. O RAG estende os poderosos recursos existentes dos LLMs para domínios específicos ou para a base de conhecimento interna de uma organização, tudo sem a necessidade de retreinar o modelo. É uma abordagem econômica para melhorar a produção de um LLM para que permaneça relevante, precisa e útil em vários contextos.
O diagrama a seguir mostra as etapas de alto nível de um processo de RAG para acessar os repositórios de conhecimento internos ou externos de uma organização e transmitir os dados para o LLM.
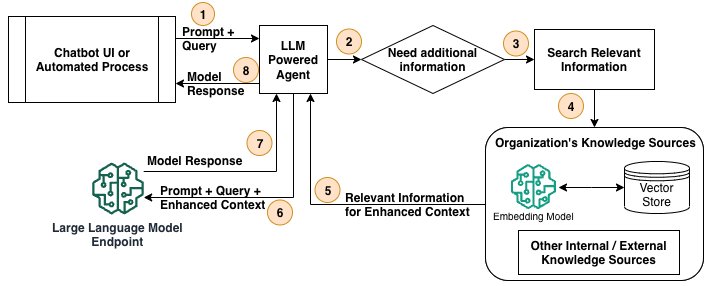
O fluxo de trabalho consiste nas seguintes etapas:
- 1. Um usuário, por meio de uma interface de usuário de chatbot ou de um processo automatizado, emite uma solicitação e solicita uma resposta do aplicativo baseado em LLM.
- 2. Um agente baseado em LLM, responsável por orquestrar as etapas para responder à solicitação, verifica se são necessárias informações adicionais das fontes de conhecimento.
- 3. O agente decide qual fonte de conhecimento usar.
- 4. O agente invoca o processo para recuperar informações da fonte de conhecimento.
- 5. As informações relevantes (contexto aprimorado) da fonte de conhecimento são devolvidas ao agente.
- 6. O agente adiciona o contexto aprimorado da fonte de conhecimento ao prompt e o passa para o endpoint do LLM para obter a resposta.
- 7. A resposta do LLM é retornada ao agente.
- 8. O agente retorna a resposta do LLM para a interface do chatbot ou para o processo automatizado.
Casos de uso para bancos de dados vetoriais para RAG
No contexto das arquiteturas RAG, o conhecimento externo pode vir de bancos de dados relacionais, repositórios de pesquisa e documentos ou outros armazenamentos de dados. No entanto, simplesmente armazenar e pesquisar esses dados externos usando métodos tradicionais (como pesquisa por palavra-chave ou índices invertidos) pode ser ineficiente e pode não capturar as verdadeiras relações semânticas entre os pontos de dados. Os bancos de dados vetoriais são recomendados para casos de uso do RAG porque permitem a pesquisa por similaridade e representações vetoriais densas.
Veja a seguir alguns cenários em que carregar dados em um banco de dados vetorial pode ser vantajoso para casos de uso do RAG:
- Grandes bases de conhecimento – Ao lidar com extensas bases de conhecimento contendo milhões ou bilhões de documentos ou passagens, os bancos de dados vetoriais podem fornecer recursos eficientes de pesquisa por similaridade.
- Dados não estruturados ou semiestruturados – Os bancos de dados vetoriais são particularmente adequados para lidar com dados não estruturados ou semiestruturados, como documentos de texto, páginas da Web ou conteúdo em linguagem natural. Ao converter os dados textuais em representações vetoriais densas, os bancos de dados vetoriais podem capturar com eficácia as relações semânticas entre documentos ou passagens, permitindo uma recuperação mais precisa.
- Bases de conhecimento multilíngues – Em sistemas RAG que precisam lidar com bases de conhecimento abrangendo vários idiomas, bancos de dados vetoriais podem ser vantajosos. Ao usar modelos de linguagem multilíngue ou incorporações multilíngues, os bancos de dados vetoriais podem facilitar a recuperação efetiva em diferentes idiomas, permitindo a transferência de conhecimento entre idiomas.
- Pesquisa semântica e classificação de relevância – Os bancos de dados vetoriais se destacam em tarefas de busca semântica e classificação de relevância. Ao representar documentos ou passagens como vetores densos, o componente de recuperação pode usar medidas de similaridade vetorial para identificar o conteúdo semanticamente mais relevante.
- Recuperação personalizada e sensível ao contexto – Os bancos de dados vetoriais podem oferecer suporte à recuperação personalizada e sensível ao contexto em sistemas RAG. Ao incorporar perfis de usuário, preferências ou informações contextuais às representações vetoriais, o componente de recuperação pode priorizar e revelar o conteúdo mais relevante para um usuário ou contexto específico.
Embora os bancos de dados vetoriais ofereçam vantagens nesses cenários, sua implementação e eficácia podem depender de fatores como as técnicas específicas de incorporação vetorial usadas, a qualidade e representação dos dados e os recursos computacionais disponíveis para operações de indexação e recuperação. Com as bases de conhecimento Amazon Bedrock, você pode fornecer aos FMs e agentes informações contextuais das fontes de dados privadas da sua empresa para que o RAG forneça respostas mais relevantes, precisas e personalizadas.
Bases de Conhecimento do Amazon Bedrock com RAG
Bases de Conhecimento do Amazon Bedrock é um recurso totalmente gerenciado que ajuda na implementação de todo o fluxo de trabalho do RAG, desde a ingestão até a recuperação e o aumento imediato, sem precisar criar integrações personalizadas com fontes de dados e gerenciar fluxos de dados. As bases de conhecimento são essenciais para vários casos de uso, como suporte ao cliente, documentação do produto, compartilhamento interno de conhecimento e sistemas de tomada de decisão. Um fluxo de trabalho RAG com bases de conhecimento tem duas etapas principais: pré-processamento de dados e execução em tempo de execução.
O diagrama a seguir ilustra o fluxo de trabalho de pré-processamento de dados.
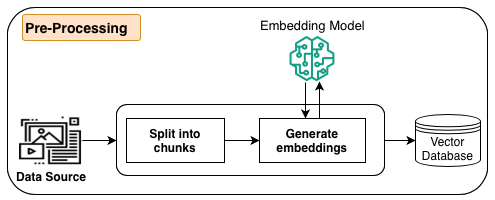
Como parte do pré-processamento, as informações (dados estruturados, dados não estruturados ou documentos) das fontes de dados são primeiro divididas em partes gerenciáveis. Os fragmentos são convertidos em incorporações usando modelos de incorporação disponíveis no Amazon Bedrock. Por fim, as incorporações são gravadas em um índice de banco de dados vetorial, mantendo um mapeamento para o documento original. Essas incorporações são usadas para determinar a semelhança semântica entre consultas e texto das fontes de dados. Todas essas etapas são gerenciadas pelo Amazon Bedrock.
O diagrama a seguir ilustra o fluxo de trabalho para a execução do tempo de execução.
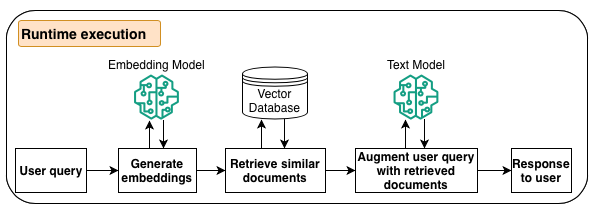
Durante a fase de inferência do LLM, quando o agente determina que precisa de informações adicionais, ele entra em contato com as bases de conhecimento. O processo converte a consulta do usuário em incorporações vetoriais usando um modelo de incorporação do Amazon Bedrock, consulta o índice do banco de dados vetoriais para encontrar partes semanticamente semelhantes à consulta do usuário, converte as partes recuperadas em texto e aumenta a consulta do usuário e, em seguida, responde ao agente.
Modelos de incorporação são necessários na fase de pré-processamento para armazenar dados em bancos de dados vetoriais e durante a fase de execução em tempo de execução para gerar incorporações para a consulta do usuário pesquisar o índice do banco de dados vetoriais. Os modelos de incorporação mapeiam dados dispersos e de alta dimensão, como texto, em representações vetoriais densas para serem armazenados e processados com eficiência por bancos de dados vetoriais e codificam o significado semântico e as relações dos dados no espaço vetorial para permitir pesquisas de similaridade significativas. Esses modelos oferecem suporte ao mapeamento de diferentes tipos de dados, como texto, imagens, áudio e vídeo, no mesmo espaço vetorial para permitir consultas e análises multimodais. Bases de Conhecimento do Amazon Bedrock fornece modelos de incorporação (embedding models) líderes do setor para permitir casos de uso como pesquisa semântica, RAG, classificação e agrupamento, para citar alguns, além de oferecer suporte multilíngue.
Opções de banco de dados vetoriais com Bases de Conhecimento do Amazon Bedrock
No momento em que escrevo esta postagem, Bases de Conhecimento do Amazon Bedrock fornece cinco opções de integração: o Vector Engine para Amazon OpenSearch Serverless, Amazon Aurora, MongoDB Atlas, Pinecone e Redis Enterprise Cloud, com mais opções de banco de dados vetoriais por vir. Neste post, discutimos casos de uso, recursos e etapas para configurar e recuperar informações usando esses bancos de dados vetoriais. O Amazon Bedrock facilita a adoção de qualquer uma dessas opções, fornecendo um conjunto comum de APIs, modelos de incorporação líderes do setor, segurança, governança e observabilidade.
Papel dos metadados na indexação de dados em bancos de dados vetoriais
Os metadados desempenham um papel crucial ao carregar documentos em um armazenamento de dados vetoriais no Amazon Bedrock. Ele fornece contexto e informações adicionais sobre os documentos, que podem ser usados para várias finalidades, como filtragem, classificação e aprimoramento dos recursos de pesquisa.
A seguir estão alguns dos principais usos dos metadados ao carregar documentos em um armazenamento de dados vetoriais:
- Identificação do documento – Os metadados podem incluir identificadores exclusivos para cada documento, como IDs de documentos, URLs ou nomes de arquivos. Esses identificadores podem ser usados para referenciar e recuperar de forma exclusiva documentos específicos do armazenamento de dados vetoriais.
- Categorização de conteúdo – Os metadados podem fornecer informações sobre o conteúdo ou a categoria de um documento, como assunto, domínio ou tópico. Essas informações podem ser usadas para organizar e filtrar documentos com base em categorias ou domínios específicos.
- Atributos do documento – Os metadados podem armazenar atributos adicionais relacionados ao documento, como autor, data de publicação, idioma ou outras informações relevantes. Esses atributos podem ser usados para filtragem, classificação ou pesquisa facetada no armazenamento de dados vetoriais.
- Controle de acesso l – Os metadados podem incluir informações sobre permissões de acesso ou níveis de segurança associados a um documento. Essas informações podem ser usadas para controlar o acesso a documentos confidenciais ou restritos no armazenamento de dados vetoriais.
- Pontuação de relevância – Os metadados podem ser usados para aprimorar a pontuação de relevância dos resultados da pesquisa. Por exemplo, se um usuário pesquisar documentos dentro de um intervalo de datas específico ou de autoria de uma pessoa específica, os metadados podem ser usados para priorizar e classificar os documentos mais relevantes.
- Enriquecimento de dados – Os metadados podem ser usados para enriquecer as representações vetoriais de documentos incorporando informações contextuais adicionais. Isso pode melhorar potencialmente a precisão e a qualidade dos resultados da pesquisa.
- Linhagem e auditoria de dados – Os metadados podem fornecer informações sobre a proveniência e a linhagem dos documentos, como o sistema de origem, o pipeline de ingestão de dados ou outras transformações aplicadas aos dados. Essas informações podem ser valiosas para fins de governança de dados, auditoria e conformidade.
Pré-requisitos
Conclua as etapas desta seção para definir os recursos e configurações pré-requisitos.
Configurar o Amazon SageMaker Studio
A primeira etapa é configurar um notebook do Amazon SageMaker Studio para executar o código desta publicação. Você pode configurar o notebook em qualquer região da AWS em que Bases de Conhecimento do Amazon Bedrock esteja disponível.
- Preencha os pré-requisitos para configurar o Amazon SageMaker.
- Conclua a configuração rápida ou configuração personalizada para ativar seu domínio e perfil de usuário do SageMaker Studio.
Você também precisa de uma função do AWS Identity and Access Management (IAM) atribuída ao domínio do SageMaker Studio. Você pode identificar a função no console do SageMaker. Na página Domínios, abra seu domínio. O ARN da função do IAM está listado na guia Configurações do domínio.
A função precisa de permissões para IAM, Amazon Relational Database Service (Amazon RDS), Amazon Bedrock, AWS Secrets Manager, Amazon Simple Storage Service (Amazon S3), e Amazon OpenSearch Serverless. - Modifique as permissões da função para adicionar as seguintes políticas:
IAMFullAccessAmazonRDSFullAccessAmazonBedrockFullAccessSecretsManagerReadWriteAmazonRDSDataFullAccessAmazonS3FullAccess- A seguinte política em linha:
- No console do SageMaker, escolha Studio no painel de navegação.
- Escolha seu perfil de usuário e escolha Open Studio.

Isso abrirá uma nova guia do navegador para o SageMaker Studio Classic.

- Execute o aplicativo SageMaker Studio.

- Quando o aplicativo estiver em execução, escolha Abrir.

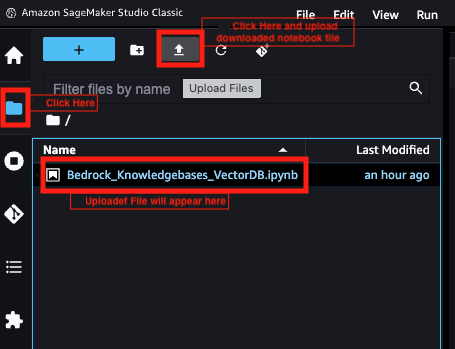
O JupyterLab abrirá em uma nova guia - Faça o download do notebook para usar nesta publicação.
- Escolha o ícone do arquivo no painel de navegação, depois escolha o ícone de upload e carregue o arquivo do notebook
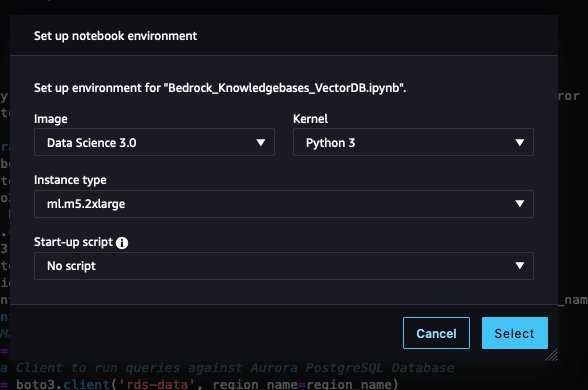
- Deixe a imagem, o kernel e o tipo de instância como padrão e escolha Selecionar.
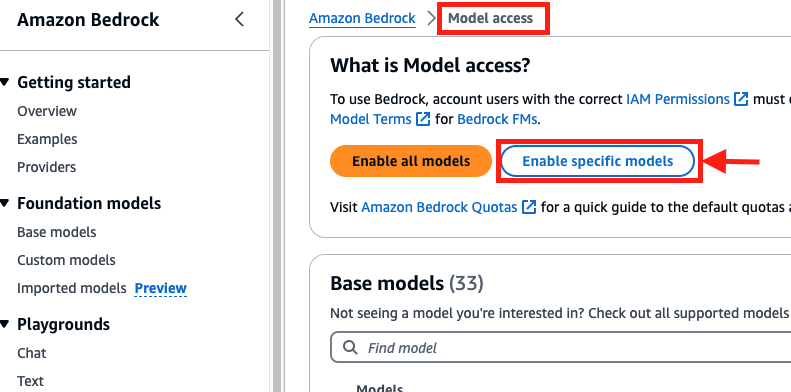
Solicite acesso ao modelo Amazon Bedrock
Conclua as etapas a seguir para solicitar acesso ao modelo de incorporação no Amazon Bedrock:
- No console Amazon Bedrock, escolha Acesso ao modelo no painel de navegação
- Escolha Ativar modelos específicos.
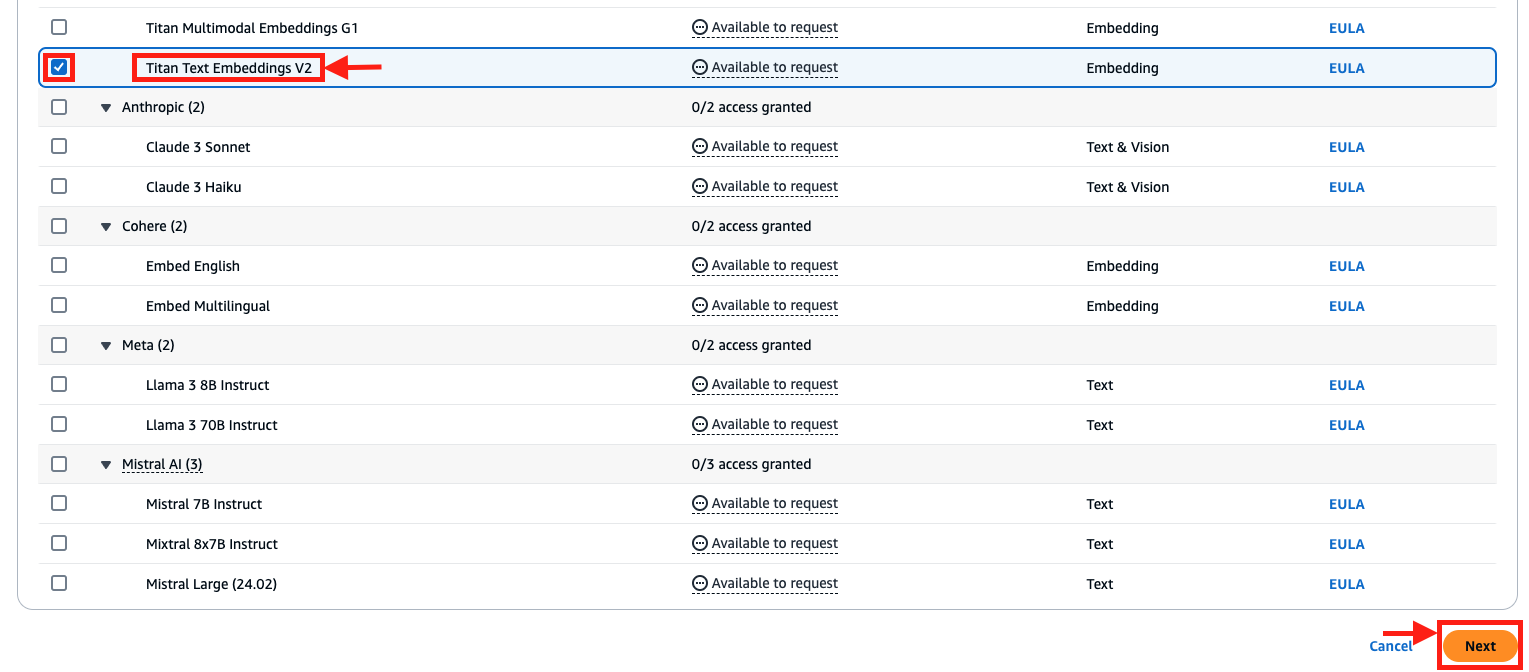
- Selecione o modelo Titan Text Embeddings V2.
- Escolha Avançar e conclua a solicitação de acessobr/>
Importar dependências
Abra o arquivo do notebook Bedrock_Knowledgebases_VectorDB.ipynb e execute a Etapa 1 para importar dependências para esta postagem e criar clientes Boto3:
Crie um bucket S3
Você pode usar o código a seguir para criar um bucket do S3 para armazenar os dados de origem do seu banco de dados vetorial ou usar um bucket existente. Se você criar um novo bucket, siga as melhores práticas e diretrizes da sua organização.
Configurar dados de amostra
Use o código a seguir para configurar os dados de amostra desta postagem, que serão a entrada para o banco de dados vetoriais:
Configurar a função do IAM para o Amazon Bedrock
Use o código a seguir para definir a função para criar a função do IAM para o Amazon Bedrock e as funções para anexar políticas relacionadas ao Amazon OpenSearch Service e ao Aurora:
Use o código a seguir para criar a função do IAM para o Amazon Bedrock, que você usará ao criar a base de conhecimento:
Integre com o OpenSearch Serverless
O Motor vetorial do Amazon OpenSearch Serverless é uma configuração sem servidor sob demanda para o OpenSearch Service. Por ser sem servidor, ele remove as complexidades operacionais de provisionamento, configuração e ajuste de seus clusters do OpenSearch. Com o OpenSearch Serverless, você pode pesquisar e analisar um grande volume de dados sem precisar se preocupar com a infraestrutura subjacente e o gerenciamento de dados.
O diagrama a seguir ilustra a arquitetura OpenSearch Serverless. A capacidade computacional do OpenSearch Serverless para ingestão, pesquisa e consulta de dados é medida em Unidades de Computação OpenSearch (OCUs).
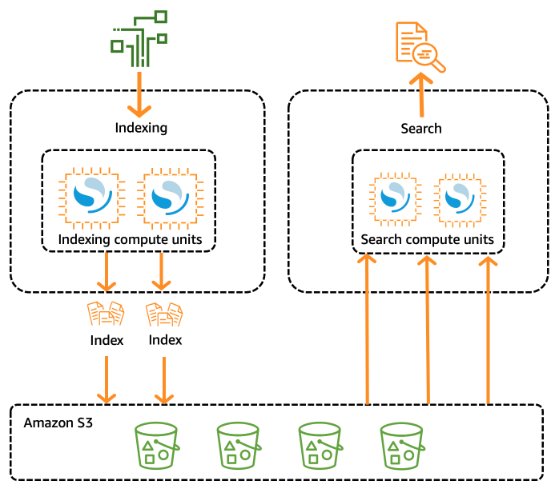
O tipo de coleta de pesquisa vetorial no OpenSearch Serverless fornece um recurso de pesquisa por similaridade que é escalável e de alto desempenho. Isso o torna uma opção popular para um banco de dados vetorial ao usar Bases de Conhecimento do Amazon Bedrock , pois facilita a criação de experiências modernas de pesquisa aumentada de aprendizado de máquina (ML) e aplicativos de IA generativa sem precisar gerenciar a infraestrutura subjacente do banco de dados vetorial. Os casos de uso das coleções de pesquisa vetorial do OpenSearch Serverless incluem pesquisas de imagens, pesquisas de documentos, recuperação de músicas, recomendações de produtos, pesquisas de vídeo, pesquisas baseadas em localização, detecção de fraudes e detecção de anomalias. O mecanismo vetorial fornece métricas de distância, como distância euclidiana, similaridade de cosseno e similaridade de produtos escalares. Você pode armazenar campos com vários tipos de dados para metadados, como números, booleanos, datas, palavras-chave e pontos geográficos. Você também pode armazenar campos com texto para obter informações descritivas para adicionar mais contexto aos vetores armazenados. A colocação dos tipos de dados reduz a complexidade, aumenta a capacidade de manutenção e evita a duplicação de dados, desafios de compatibilidade de versões e problemas de licenciamento.
Os trechos de código a seguir configuram um banco de dados vetorial OpenSearch Serverless e o integram a uma base de conhecimento no Amazon Bedrock:
- Crie uma coleção de vetores OpenSearch Serverless.
- Crie um índice na coleção; esse índice será gerenciado pelas bases de conhecimento Amazon Bedrock:
- Crie uma base de conhecimento no Amazon Bedrock apontando para a coleção e o índice de vetores do OpenSearch Serverless:
- Crie uma fonte de dados para a base de conhecimento
- Inicie um trabalho de ingestão para a base de conhecimento apontando para o OpenSearch Serverless para gerar incorporações vetoriais para dados no Amazon S3:
Integre com o Aurora pgvector
O Aurora fornece integração pgvector, que é uma extensão de código aberto para o PostgreSQL que adiciona a capacidade de armazenar e pesquisar em incorporações vetoriais geradas por ML. Isso permite que você use o Aurora para casos de uso de IA generativa com RAG, armazenando vetores com o restante dos dados. O diagrama a seguir ilustra a arquitetura de exemplo.
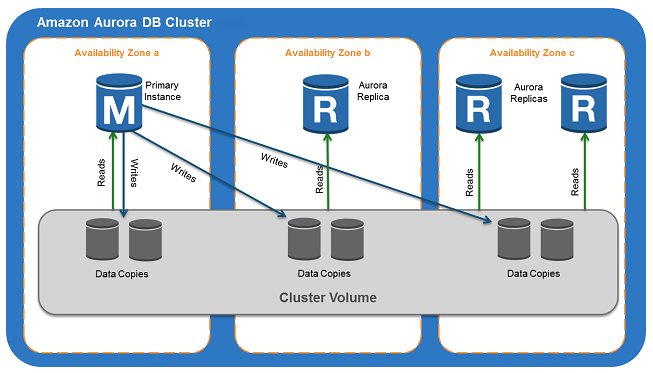
Os casos de uso do Aurora pgvector incluem aplicativos que têm requisitos de conformidade com ACID, recuperação pontual, uniões e muito mais. Veja a seguir um exemplo de trecho de código para configurar o Aurora com sua base de conhecimento no Amazon Bedrock:
- 1. Crie uma instância de banco de dados Aurora (esse código cria uma instância de banco de dados gerenciada, mas você também pode criar uma instância sem servidor). Identifique o ID do grupo de segurança e os IDs de sub-rede da sua VPC antes de executar a etapa a seguir e forneça os valores apropriados nas variáveis
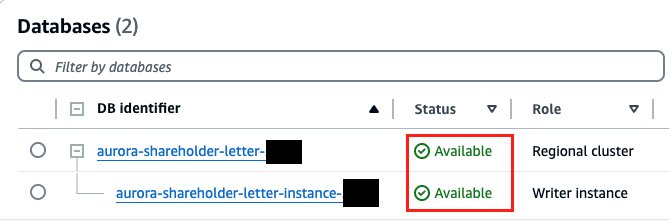
vpc_security_group_idse subnetIds: - No console do Amazon RDS, confirme se o status do banco de dados Aurora aparece como Disponível
- Crie a extensão vetorial, o esquema e a tabela vetorial no banco de dados do Aurora:
- Crie uma base de conhecimento no Amazon Bedrock apontando para o banco de dados e a tabela do Aurora:
- Crie uma fonte de dados para a base de conhecimento:
- Inicie um trabalho de ingestão para sua base de conhecimento apontando para a tabela pgvector do Aurora para gerar incorporações vetoriais para dados no Amazon S3:
Integre com o MongoDB Atlas
O MongoDB Atlas Vector Search, quando integrado ao Amazon Bedrock, pode servir como uma base de conhecimento robusta e escalável para criar aplicativos de IA generativa e implementar fluxos de trabalho RAG. Ao usar o modelo flexível de dados de documentos do MongoDB Atlas, as organizações podem representar e consultar entidades de conhecimento complexas e seus relacionamentos no Amazon Bedrock. A combinação do MongoDB Atlas e do Amazon Bedrock fornece uma solução poderosa para criar e manter um repositório de conhecimento centralizado.
Para usar o MongoDB, você pode criar um cluster e um índice de pesquisa vetorial. Os recursos de pesquisa vetorial nativa incorporados em um banco de dados operacional simplificam a criação de implementações sofisticadas de RAG. O MongoDB permite que você armazene, indexe e consulte incorporações vetoriais de seus dados sem a necessidade de um banco de dados vetorial separado.
Há três opções de preços disponíveis para o MongoDB Atlas por meio do AWS Marketplace: MongoDB Atlas (pague conforme o uso), MongoDB Atlas Enterprise, e MongoDB Atlas for Government. Consulte a documentação do MongoDB Atlas Vector Search para configurar um banco de dados vetoriais MongoDB e adicioná-lo à sua base de conhecimento
Integre com o Pinecone
Pinecone é um tipo de banco de dados vetorial da Pinecone Systems Inc. Com as bases de conhecimento do Amazon Bedrock, você pode integrar seus dados corporativos ao Amazon Bedrock usando o Pinecone como banco de dados vetorial totalmente gerenciado para criar aplicativos de IA generativa. O Pinecone tem alto desempenho; ele pode acelerar os dados em milissegundos. Você pode usar seus filtros de metadados e o suporte a índices esparsos e densos para obter relevância de alto nível, obtendo resultados rápidos, precisos e fundamentados em diversas tarefas de pesquisa. O Pinecone está pronto para uso corporativo; você pode lançar e escalar sua solução de IA sem precisar manter a infraestrutura, monitorar serviços ou solucionar problemas com algoritmos. O Pinecone atende aos requisitos operacionais e de segurança das empresas.
Há duas opções de preços disponíveis para o Pinecone no AWS Marketplace: Pinecone Vector Database – Pay As You Go Pricing (sem servidor) e Pinecone Vector Database – Annual Commit (gerenciado). Consulte a documentação para configurar um banco de dados vetoriais do Pinecone e adicioná-lo à sua base de conhecimento
Integre-se com o Redis Enterprise Cloud
O Redis Enterprise Cloud permite que você configure, gerencie e escale um armazenamento de dados distribuído na memória ou um ambiente de cache na nuvem para ajudar os aplicativos a atender aos requisitos de baixa latência. A pesquisa vetorial é uma das opções de solução disponíveis no Redis Enterprise Cloud, que resolve casos de uso de baixa latência relacionados a RAG, cache semântico, pesquisa de documentos e muito mais. O Amazon Bedrock se integra de forma nativa à pesquisa vetorial do Redis Enterprise Cloud.
Há duas opções de preços disponíveis para o Redis Enterprise Cloud por meio do AWS Marketplace: Redis Cloud Pay As You Go Pricing e Redis Cloud – Annual Commits. Consulte a Redis Enterprise Cloud documentation para configurar a pesquisa vetorial e adicioná-la à sua base de conhecimento.
Interaja com as bases de conhecimento do Amazon Bedrock
O Amazon Bedrock fornece um conjunto comum de APIs para interagir com bases de conhecimento:
- API de recuperação – consulta a base de conhecimento e recupera informações dela. Essa é uma API específica da Base de Conhecimento do Bedrock, que ajuda em casos de uso em que somente a pesquisa de documentos baseada em vetores é necessária sem inferências de modelos.
- API de recuperação e geração – consulta a base de conhecimento e usa um LLM para gerar respostas com base nos resultados recuperados.
Os trechos de código a seguir mostram como usar a API Retrieve do índice do banco de dados vetorial OpenSearch Serverless e da tabela pgvector do Aurora:
- Recupere dados do índice do banco de dados vetoriais OpenSearch Serverless:
- Recupere dados da tabela pgvector do Aurora:
Limpe
Quando você terminar com essa solução, limpe os recursos que você criou:
- Bases de conhecimento do Amazon Bedrock para OpenSearch Serverless e Aurora
- Coleção OpenSearch Serverless
- Instância de banco de dados Aurora
- S3 bucket
- Domínio do SageMaker Studio
- Função do serviço Amazon Bedrock
- Função de domínio do SageMaker Studio
Conclusão
Nesta postagem, fornecemos uma introdução de alto nível aos casos de uso de IA generativa e ao uso de fluxos de trabalho do RAG para aumentar os estoques de conhecimento internos ou externos da sua organização. Discutimos a importância dos bancos de dados vetoriais e das arquiteturas RAG para permitir a pesquisa por similaridade e por que representações vetoriais densas são benéficas. Também examinamos as bases de conhecimento do Amazon Bedrock, que fornecem APIs comuns, governança, observabilidade e segurança líderes do setor para habilitar bancos de dados vetoriais usando diferentes opções, como produtos nativos e parceiros da AWS, por meio do AWS Marketplace. Também nos aprofundamos em algumas das opções de banco de dados vetoriais com exemplos de código para explicar as etapas de implementação.
Experimente os exemplos de código nesta postagem para implementar sua própria solução RAG usando as Bases de Conhecimento do Amazon Bedrock e compartilhe seus comentários e perguntas na seção de comentários.
Sobre os autores
 |
Vishwa Gupta é arquiteto de dados sênior com serviços profissionais da AWS. Ele ajuda os clientes a implementar soluções de IA generativa, aprendizado de máquina e análise. Fora do trabalho, ele gosta de passar tempo com a família, viajar e experimentar novas comidas. |
 |
Isaac Privitera é cientista de dados principal do AWS Generative AI Innovation Center, onde desenvolve soluções personalizadas baseadas em IA generativa para resolver os problemas comerciais dos clientes. Seu foco principal está na construção de sistemas de IA responsáveis, usando técnicas como RAG, sistemas multiagentes e ajuste fino de modelos. Quando não está imerso no mundo da IA, Isaac pode ser encontrado no campo de golfe, curtindo um jogo de futebol ou fazendo trilhas com seu fiel companheiro canino, Barry. |
 |
Abhishek Madan é estrategista sênior de GenAI no AWS Generative AI Innovation Center. Ele ajuda equipes internas e clientes a escalar soluções de IA generativa, aprendizado de máquina e análise. Fora do trabalho, ele gosta de praticar esportes de aventura e passar tempo com a família.
|
 |
Ginni Malik é engenheira sênior de dados e ML da AWS Professional Services. Ela auxilia os clientes arquitetando soluções corporativas de data lake e ML para escalar suas análises de dados na nuvem. |
 |
Satish Sarapuri é arquiteto sênior de dados do Data Lake na AWS. Ele ajuda clientes de nível corporativo a criar soluções de IA generativa, malha de dados, data lake e plataformas de análise de alto desempenho, alta disponibilidade, economia de custos, resilientes e seguras na AWS, por meio das quais os clientes podem tomar decisões baseadas em dados para obter resultados impactantes para seus negócios e ajudá-los em sua jornada de transformação digital e de dados. Em seu tempo livre, ele gosta de passar tempo com sua família e jogar tênis. |
Sobre os tradutores
 |
Guilherme Ricci é Arquiteto de Soluções Sênior para startups na Amazon Web Services, ajudando startups a modernizar e otimizar os custos de suas aplicações. Com mais de 10 anos de experiência em empresas do setor financeiro, atualmente trabalha com uma equipe de especialistas em AI/ML. |