How was this content?
- Learn
- Startup’s guide to GenAIOps on AWS part 3: Towards production excellence
Startup’s guide to GenAIOps on AWS part 3: Towards production excellence

In Part 1 and Part 2, we established GenAIOps foundations for MVP to initial production deployment. If you've implemented these practices, you're likely seeing results: growing adoption, paying customers, and product-market-fit signals that every founder dreams of. But success brings new challenges.
The simplicity that served your early stages now faces scaling pressures: maintaining reliability as request volumes surge, ensuring consistent performance across diverse user workloads, and managing the complexity that accompanies growth. Part 3 shows you how to handle scaling demands without sacrificing speed of innovation.
Evolving your pipeline
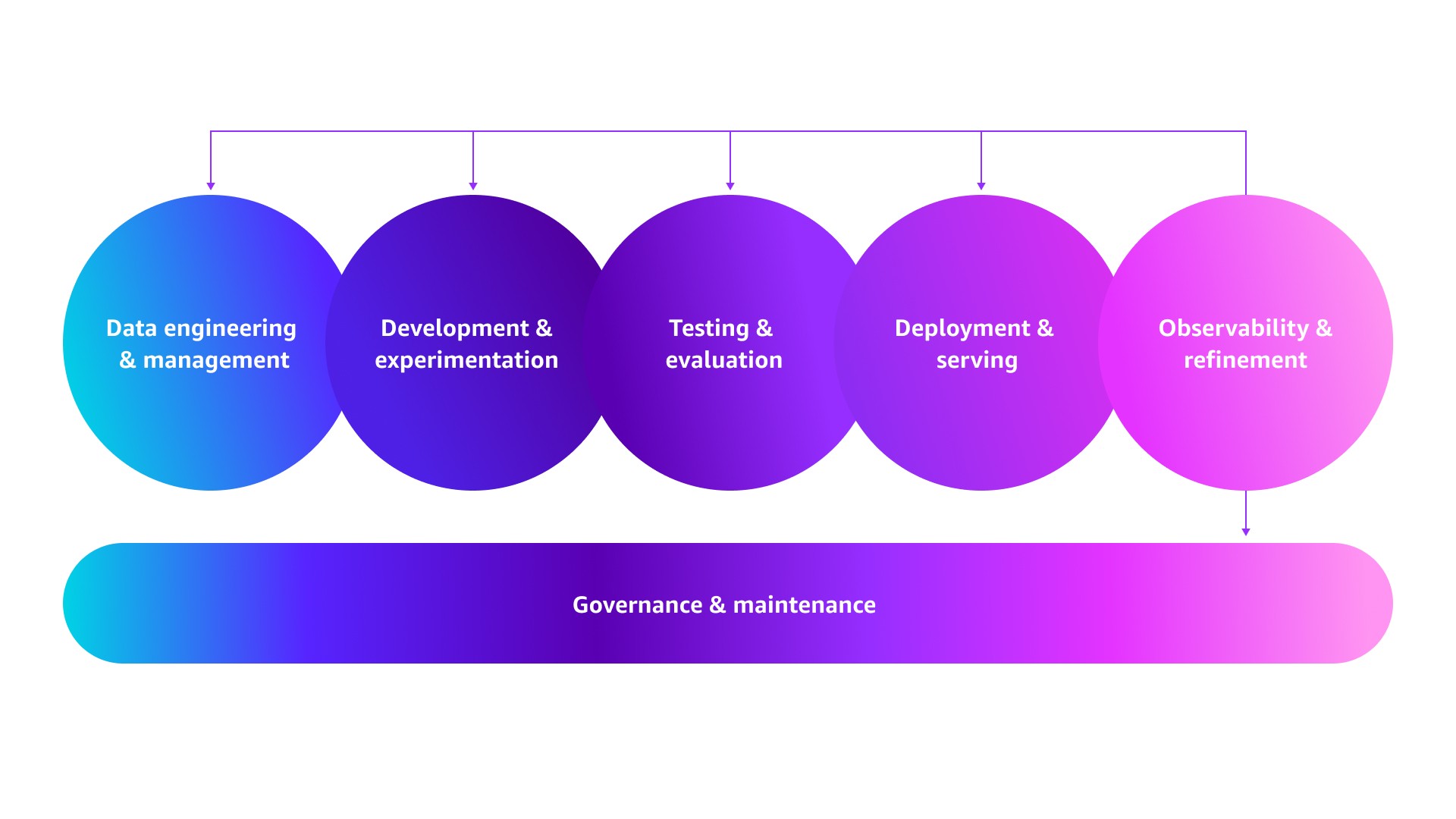
Reaching production excellence isn't just about managing more traffic. It's about building a pipeline that works reliably, efficiently, and predictably at scale. This means automating manual processes, establishing systematic experimentation and deployment, and implementing observability to understand not just what's happening, but why. As illustrated below, this evolution happens through operational shifts across six pipeline stages—from the essentials that took you from MVP to product-market fit to the automated systems that enable sustainable growth. Let's explore how to evolve each stage.
.jpg)

Data engineering and management: shift to continuously evolving data assets
With production traffic now flowing, it’s time to transform static datasets into continuously enriched resources powered by real user interaction.
Systematic production log mining: Expand model selection and prompt evaluation datasets from hundreds of curated examples to thousands of real test cases. Harvest high-value fine-tuning examples, e.g., conversations requiring human intervention and queries demonstrating desired behaviors. Use Amazon SageMaker Ground Truth Plus to curate production examples for supervised fine-tuning.
Automated RAG data pipeline: Replace manual data source updates for knowledge bases with event-driven workflows using Amazon EventBridge. Workflows involving documents, images, audio, and videos can be automated at scale using Amazon Bedrock Data Automation. When queries fail to retrieve relevant context or show low confidence scores, automatically capture failures as RAG evaluation test cases.
Helpful resources:
- High-quality human feedback for your generative AI applications from Amazon SageMaker Ground Truth Plus
- Build a multimodal RAG based application using Amazon Bedrock Data Automation and Amazon Bedrock Knowledge Bases
Development and experimentation: champion systematic iteration
As your operation scales, you need to progress from manual prototyping to systematic experimentation. This involves running parallel tests across your AI stack to continuously discover improvements.
Continuous model and prompt optimization: Make model right-sizing an ongoing practice, re-evaluating choices as new models emerge or requirements change. Choose multi-model systems that automatically match task complexity to model capability. Extend this efficiency to prompts through dynamic routing with specialized templates based on query classification, user context, and performance history. Track multi-dimensional performance metrics—accuracy, latency, and cost—for data-driven decisions about right-sizing models or switching prompt variants.
Context refinement workflows: Establish repeatable optimization processes for retrieving external knowledge and customizing models. For RAG optimization, implement structured experimentation by testing advanced chunking strategies and retrieval approaches (hybrid search, metadata filtering, query reformulation, re-ranking), then iterating based on retrieval accuracy and latency. Optimize embedding size by testing e.g., 768 or 512 vs. 1536 dimensions to cut storage costs and retrieval latency while maintaining accuracy. For model customization, leverage Amazon Bedrock to streamline workflows—use continued pre-training to adapt models to domain-specific vocabulary, or supervised fine-tuning to improve task-specific performance. Amazon SageMaker AI provides greater control over training as needs grow.
Establish regular optimization cycles to evolve context systems with your application, from monthly RAG performance reviews to quarterly model customization assessments.
Agent orchestration for complex workflows: As your agents handle diverse production workloads, single-agent architectures hit complexity limits. Agents attempting both billing inquiries and technical troubleshooting struggle with conflicting context and tool sets. Monitor completion rates by task complexity: if your agent succeeds on 85 percent of tasks requiring 2-3 tool calls but drops to 45 percent with 5+ calls, you've found the threshold for decomposition. Deploy specialized multi-agent systems where a routing agent delegates billing questions to payment agents and technical issues flow to support agents.
Amazon Bedrock AgentCore addresses production scaling challenges by providing session isolation for concurrent users, extended runtimes for complex reasoning, and unified observability across your agents. To protect against runaway costs, implement timeout mechanisms to reduce the likelihood of blocking failures on agentic workflows and executions.
Systematic experimentation without production chaos: Running multiple experiments simultaneously relies on isolating tests and protecting production traffic. To control AI component rollouts, deploy feature flags via AWS AppConfig where you can test new RAG retrieval strategies or evaluate prompt variants simultaneously across user segments.
To ensure reliable experiment results, start by creating isolated testing environments that mirror production data and traffic patterns. Then establish standardized metrics across both technical aspects like accuracy and latency, as well as user behavior metrics such as satisfaction and engagement. When comparing experiments, take a holistic approach to evaluation. For example, when comparing two RAG retrieval strategies, consider that a small accuracy improvement with better latency might drive higher overall user satisfaction than a larger accuracy gain with increased latency. This ensures that your experimental outcomes reflect real-world impact rather than just isolated metrics.
Helpful resources:
- Building scalable, secure, and reliable RAG applications using Amazon Bedrock Knowledge Bases
- Amazon Bedrock Knowledge Bases now supports advanced parsing, chunking, and query reformulation giving greater control of accuracy in RAG based applications
- Multi agent collaboration with strands
Testing and evaluation: create continuous quality loops
Manual testing can quickly become unmanageable, especially when shipping multiple times weekly. Moving from a pre-release gate to a continuous feedback loop will drive faster iteration and prevent bad deployments from damaging customer trust.
Automated evaluation pipeline: Transform the evaluation approaches from Part 2 into automated test suites integrated with your CI/CD pipeline. Every code deployment automatically triggers component and end-to-end evaluations—measuring accuracy, task completion, and response quality. Catch issues from knowledge base updates or data refreshes outside deployment cycles by scheduling nightly regression tests. Don’t forget to set quality thresholds to block deployments that increase latency or reduce accuracy. Feeding test failures back into your data pipeline will also enrich your evaluation coverage.
Responsible AI evaluation strategies: Functional correctness isn't enough—production systems must be safe and trustworthy. Extend automated testing to include hallucination detection with factual grounding checks, prompt injection resistance via adversarial test cases, and harmful content assessment. Other strategies for supporting performance and safety at scale include running regular red teaming exercises to identify unsafe behaviors and spot-checking production outputs for responsible AI metrics.
Helpful resources:
- Build an automated generative AI solution evaluation pipeline with Amazon Nova
- Considerations for addressing the core dimensions of responsible AI for Amazon Bedrock applications
Deployment and serving: scale with resilience
As your production traffic scales, deployment should progress from simply getting the applications online to implementing strategies that maintain reliability and performance.
Scalable deployment strategies: Start by defining performance requirements, including target throughput, latency percentiles, and degradation thresholds. Next, perform load tests simulating sustained traffic, burst patterns, and multi-step workflows. This will identify performance gaps, inform architectural decisions, and validate infrastructure requirements.
Optimize inference efficiency through intelligent caching and serving patterns. Leveraging Bedrock prompt caching will help you reuse large context blocks, in turn reducing latency and costs. Matching inference patterns to requirements, e.g., using real-time inference for interactive applications or batch inference for offline analysis, will also significantly lower cost.
To architect for scale across your stack, Amazon Bedrock cross-region inference automatically routes requests across optimal AWS Regions for increased throughput and availability. Meanwhile, SageMaker AI endpoint auto-scaling dynamically adjusts capacity, Bedrock AgentCore Runtime offers secure agent deployment at scale, and OpenSearch Serverless automatically scales compute capacity for vector databases.
Deployment patterns can also de-risk releases, such as canary deployments to expose 5-10 percent of traffic to new models while monitoring metrics before full rollout and blue-green deployments that enable instant rollback from regressions.
Resilient serving strategies: Beyond scalability, production systems must handle quota limits, transient failures, and unexpected load without degrading user experience. Review Amazon Bedrock quotas proactively, requesting increases before hitting limits. Implement rate limiting using Amazon API Gateway to control incoming requests and ensure fair usage. Use Amazon SQS between your application and models to absorb demand variability and prevent request rejection.
By configuring model cascade hierarchies—primary model to backup model to cached responses to gracefully degraded responses—you can ensure users always receive a response even when optimal serving paths fail. Beyond this, implement circuit breakers to halt requests to failing dependencies.
Helpful resources:
- Optimizing AI responsiveness: A practical guide to Amazon Bedrock latency-optimized inference
- Designing generative AI workloads for resilience
Observability and refinement: power continuous improvement
Make observability your primary competitive advantage with a closed-loop system where insights automatically trigger refinements, creating a self-improving application.
Unified observability across technical and business metrics: Correlation analysis is key to understanding system behavior as a whole. To do so, build unified dashboards combining technical and business metrics—not just "Model A vs Model B" but rather "Model A at $0.02/request with 92 percent accuracy vs Model B at $0.08/request with 94 percent accuracy”—then track how each impacts 30-day user retention. Design role-specific views from shared telemetry: engineering sees error rate alerts and latency trends; product teams see completion rates and user interaction patterns; executives see cost-per-interaction and ROI correlations. So, when your customer service bot shows 40 percent longer queries during feature launches or seasonal patterns shift cost structure by 60 percent, cross-metric correlation analysis reveals the root cause.
Closed-loop improvement cycles: Real production excellence comes from creating closed-loop systems where observability triggers refinement across the entire GenAIOps pipeline as shown in the figure below.
For example, your customer service bot's observability can trigger the following improvements:
- Data engineering and management: When the failed response rate rises by 15 percent for product launch queries, EventBridge triggers knowledge base sync to ingest latest documentation from source systems.
- Development and experimentation: If bot resolution rates drop by 20 percent for billing queries, the system queues A/B tests for billing-specialized prompt variants.
- Testing and evaluation: When order tracking conversation failures increase by 25 percent, test cases are automatically generated from failed interactions and added to regression suites.
- Deployment and serving: When trace analysis shows 8 percent of agent workflows timing out at 30 seconds but completing successfully at 45 seconds, timeout configurations are adjusted.
- Governance and maintenance: When deployment logs show 40 percent of releases fail due to missing IAM permissions or infrastructure prerequisites, pre-flight validation checks are added to the deployment pipeline—catching configuration issues before they block releases.
Helpful resources:
- Empower your generative AI application with a comprehensive custom observability solution
- Build trustworthy AI agents with Amazon Bedrock AgentCore Observability
Governance and maintenance: enable safe innovation
Your governance framework should feel like a trusted advisor who accelerates smart risk-taking while stopping costly mistakes. Transform those Part 2 guardrails into your competitive advantage through responsible AI practices that build customer trust.
Automated governance workflows: Replace manual reviews with intelligent automation, using AWS Step Functions to build approval workflows where low-risk updates like prompt template refinements deploy automatically and high-risk updates like model changes trigger human reviews. You can also automate compliance documentation, from capturing approval chains to maintaining audit trails. When deployments violate policies, workflows automatically block release and escalate to stakeholders.
Infrastructure as code and lineage tracking: Codify your entire AI infrastructure—capturing deployment knowledge in version-controlled code. Track model lineage using Amazon SageMaker Model Registry and data lineage using Amazon SageMaker Catalog capabilities. Documenting how data flows from source documents through processing steps to model outputs also creates audit trails to support debugging and compliance, making everything from training data to inference result traceable.
Operational visibility and accountability: Create role-specific dashboards in Amazon QuickSight that surface governance metrics. Establish clear ownership across teams, with product owning performance targets, engineering owning reliability, compliance owning safety, and governance coordinating across teams.
Helpful resources:
- Effectively manage foundation models for generative AI applications with Amazon SageMaker Model Registry
- Streamline the path from data to insights with new Amazon SageMaker Catalog capabilities
Conclusion
Achieving production excellence isn't a one-time effort, it's an ongoing process of building a pipeline that learns from every deployment, failure, and user interaction. These systematic improvements compound over time, creating competitive advantages beyond what’s possible from just shipping features faster.
To take your next step, prioritize your most challenging pipeline stage—whether that's experiments taking too long to validate, difficult deployments, or unpredictable costs. Once you’ve automated that area, move onto the next and keep going. Ultimately, what sets leading AI startups apart isn't access to better models, it's a robust GenAIOps pipeline that continuously improves the user experience.

Nima Seifi
Nima Seifi is a Senior Solutions Architect at AWS, based in Southern California, where he specializes in SaaS and GenAIOps. He serves as a technical advisor to startups building on AWS. Prior to AWS, he worked as a DevOps architect in the ecommerce industry for over 5 years, following a decade of R&D work in mobile internet technologies. Nima has 20+ publications in prominent technical journals and conferences and holds 7 US patents. Outside of work, he enjoys reading, watching documentaries, and taking beach walks.
.jpg)
Pat Santora
Pat Santora is a GenAI Labs Cloud Architect and Technologist with over 25 years of experience implementing solutions across the cloud for both enterprises and startups. He has successfully launched numerous products from inception, led analytical re-architecture projects, and managed remote teams with a philosophy centered on transparency and trust. His technical expertise spans strategic planning, systems management, and architectural redesign, complemented by interests in GenAI, Analytics, and Big Data.
.jpg)
Clement Perrot
Clement Perrot helps top-tier startups accelerate their AI initiatives by providing strategic guidance on model selection, responsible AI implementation, and optimized machine learning operations. A serial entrepreneur and Inc 30 Under 30 honoree, he brings deep expertise in building and scaling AI companies, having founded and successfully exited multiple ventures in consumer technology and enterprise AI.
How was this content?