How was this content?
- Learn
- Startup’s guide to GenAIOps on AWS part 2: Essentials
Startup’s guide to GenAIOps on AWS part 2: Essentials

In Part 1, we explored the advantages of adopting GenAIOps from day one and outlined our application-centric pipeline designed specifically for startups building AI-powered products. Now in Part 2, we provide actionable guidance for implementing the essential components that will take you from prototype to production-ready solutions.
GenAIOps pipeline: the essentials
The key to successful GenAIOps implementation is establishing a solid baseline with robust evaluation capabilities early—creating a continuous improvement flywheel where each iteration builds on learnings from the previous one. This prevents significant technical debt while enabling rapid experimentation.
Let's explore how to implement essential components for each stage of your GenAIOps pipeline using lean but effective techniques. More information on which AWS or third party services are best suited for each step can be found in the accompanying quick reference cards.
Data engineering and management
Establish a lightweight data pipeline to manage essential data artifacts that directly power your AI application. Focus on the following key datasets based on your use case.
Model selection prompt datasets: Standardized evaluation prompt datasets are critical for fair model comparison. Start with industry-standard benchmarking datasets (MMLU, GPQA, DROP, etc.), Amazon Bedrock built-in evaluation datasets, or build your own custom domain-specific datasets. These serve as your model evaluation playbook—revisit them when new models are released or when reconsidering your model choice.
Prompt engineering datasets: These datasets include your prompt templates and ground truth datasets. Use Amazon Bedrock Prompt Management or an open-source alternative such as Langfuse to implement a centralized prompt catalog to version, test, and manage prompts. Additionally, create 100+ human curated query-response pairs representing your gold standard for prompt testing and optimization.
Retrieval Augmented Generation (RAG) datasets: Start by preparing your external knowledge sources: for unstructured data like documentation, the process involves ingestion, chunking, and generating vector embeddings using models from Amazon Titan or Cohere on Bedrock. Store embeddings in managed vector databases like Amazon OpenSearch Serverless or Amazon S3 Vectors; for structured data such as tabular data, the process includes pre-processing, schema analysis, metadata enrichment, and loading into supported structured data stores. For both data types, implement simple but effective data refresh mechanisms to keep your knowledge sources current. Additionally, create RAG evaluation datasets with query-context-answer triplets to test retrieval accuracy and response quality.
Model customization datasets: Start by collecting your most valuable proprietary data. Generate synthetic training examples when proprietary data is insufficient.
Quick reference cards: data engineering and management at a glance

Helpful resources:
- Generate synthetic data for evaluating RAG systems using Amazon Bedrock
- An introduction to preparing your own dataset for LLM training

Development and experimentation
During early development, startups should prioritize speed and simplicity, focusing on rapid experimentation through low code services to accelerate time-to-market.
Model selection: Start with public benchmarks like LMArena or Artificial Analysis to create an initial shortlist, then narrow selection through use-case specific evaluation. Amazon Bedrock provides access to leading foundation model (FM) families. To evaluate your shortlisted models, leverage Amazon Bedrock Evaluations or Amazon SageMaker Clarify.
Prompt engineering: Define clear success criteria aligned with business goals and create measurable metrics for each. Draft initial prompts following design guidelines for your chosen models, then systematically evaluate against your ground truth dataset. Leverage Amazon Bedrock's prompt optimization during drafting and refinement for model-specific improvements. Iterate until achieving consistent results, then publish successful prompts to your prompt catalog with proper versioning.
RAG: Leverage fully managed RAG options on AWS to streamline implementation of data stores, retrievers, FMs, and orchestrators—significantly reducing development time and operational overhead. Start by connecting your RAG system to supported data sources, and then integrate with an FM to create the complete augmented generation workflow. Begin with one focused knowledge domain to validate effectiveness before expanding to additional data sources. Leverage advanced RAG techniques like query modification and re-ranking to improve the relevancy of responses.
Model customization: Use training datasets to customize pre-trained FMs for improved performance on specific use cases. Always start with prompt engineering, then move to RAG if additional context is needed. Only pursue model customization if previous approaches don't meet your requirements, beginning with a focused dataset from one domain to validate improvements before expanding.
AI agents: Create AI-powered assistants that can perform complex tasks and interact with various APIs and services. Amazon Bedrock Agents automatically handle complex orchestration of understanding user intent, determining actions, making API calls, and presenting results in natural language. For customized implementation, consider using open source frameworks such as Strands or LangGraph.
Application building and experimentation: Choose your development approach based on your team's expertise and delivery timeline requirements. AWS offers several services well-suited for startups (see below), and Amazon Q Developer serves as an AI-powered assistant that helps you understand, build, extend, and operate AWS applications. Establish structured experimentation approaches that enable systematic improvement while maintaining rapid iteration. Maintain an experiment log with hypotheses, implementation details, and outcome metrics, ensuring experiments have clear success criteria tied to business metrics rather than just technical metrics.
Quick reference cards: development and experimentation at a glance

Helpful resources:
- Evaluating prompts at scale with Prompt Management and Prompt Flows for Amazon Bedrock
- From concept to reality: Navigating the Journey of RAG from proof of concept to production
- Best practices for building robust generative AI applications with Amazon Bedrock Agents
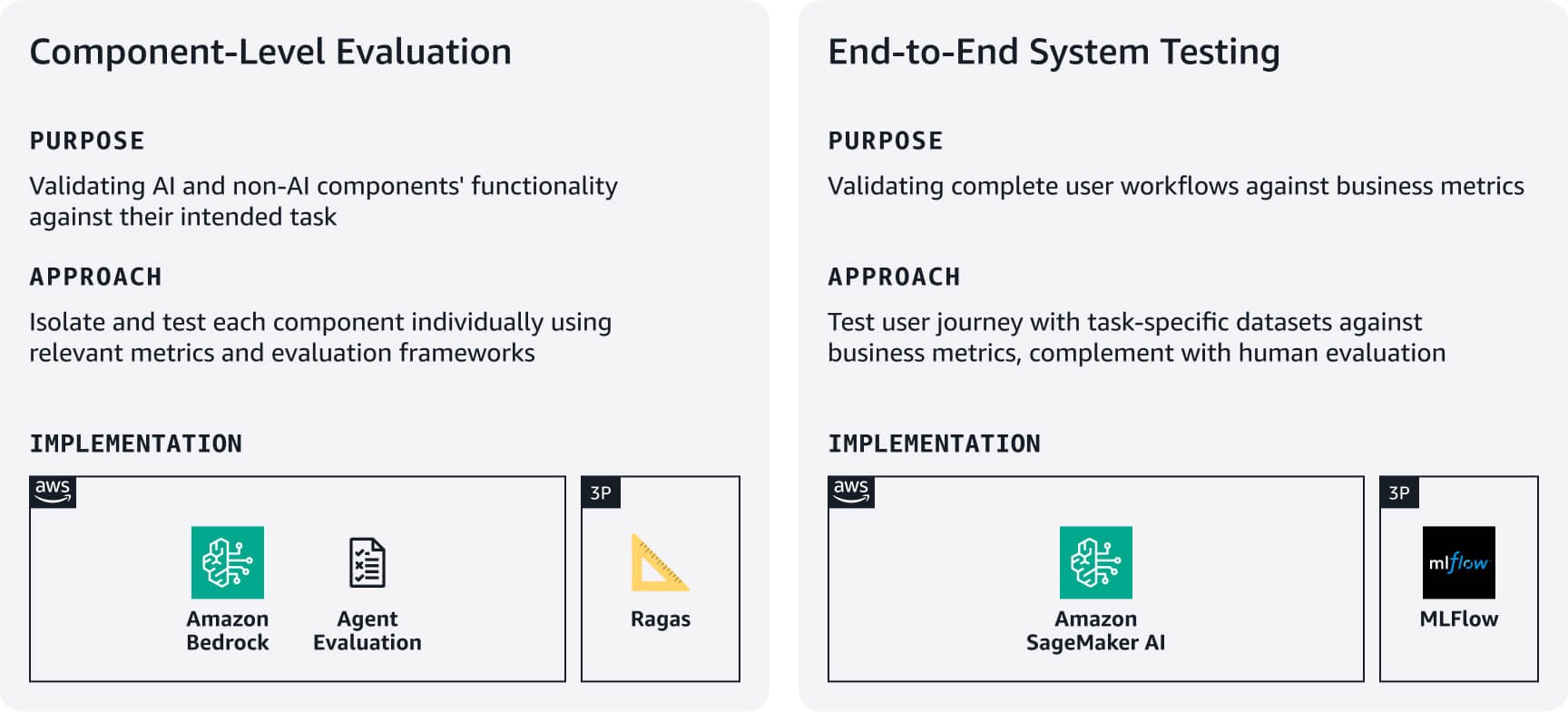
Testing and evaluation
Establish lean yet rigorous processes to verify your application works reliably and performs well, using the evaluation datasets created in stage 1. Balance thoroughness with startup velocity by focusing on your most critical user workflows first.
Component-level evaluation: Measure how well your AI and non-AI components perform their intended tasks. For example, for RAG systems, use Amazon Bedrock Evaluations or frameworks like RAGAS to assess retrieval accuracy and response generation quality. For agents, leverage frameworks such as Agent Evaluation or LLM-as-a-judge approach to evaluate metrics like task completion rates and decision/tool use accuracy based on your use case requirements.
End-to-end system testing: Test complete user workflows using task-specific evaluation datasets. Define business-aligned success metrics for each core task, then validate that components work seamlessly across user journeys. Complement automated testing with human assessment of response quality, relevance, and brand alignment—aspects automated metrics often miss. Use these evaluation results to establish baselines, then improve iteratively based on user feedback and business impact. Consider using managed MLFlow on SageMaker AI to track experiments across system versions.
Quick reference cards: testing and evaluation at a glance
Helpful resources:
Deployment and serving
Start with the simplest deployment option based on your technical requirements and team capabilities, then evolve your architecture as you grow. The AWS ecosystem provides natural upgrade paths between these deployment patterns without requiring complete architectural rewrites.
Model deployment: Start with Amazon Bedrock for immediate access to FMs through a unified API. If you need specialized models not available in Bedrock, explore Amazon Bedrock Marketplace or Amazon SageMaker JumpStart to discover and deploy your model directly on SageMaker AI.
Application hosting and operation: Deploy modern web applications using AWS Amplify Hosting. Create lightweight microservices by integrating AWS Lambda functions with Amazon API Gateway. Use AWS App Runner as your entry point for deploying containerized applications. To ensure reliability, implement simple fallback mechanisms—fall back to base model responses when RAG retrieval fails, switch to backup models when primary models are unavailable, and cache common queries using Amazon MemoryDB. Establish circuit breakers for dependent services to prevent cascading failures. These patterns form the foundation for more sophisticated resilience strategies as your user base grows.
Workflow orchestration: For complex AI operations that require request/response decoupling, combine Amazon SQS for task queuing with AWS Step Functions for orchestrating multi-step workflows. This pattern is especially valuable for time-consuming operations like batch processing or workflows involving multiple model calls.
Quick reference cards: deployment & serving at a glance

Helpful resources:
Observability and refinement
Focus on essential observability that drives immediate business impact while minimizing complexity.
Key metrics monitoring: Focus on technical performance metrics as applicable to your use case and set up CloudWatch alarms for critical thresholds. Track user experience through simple feedback mechanisms (thumbs up/down), conversation completion rates, and feature usage patterns. These often reveal issues technical metrics miss and directly impact business success.
Essential observability setup: Use Amazon CloudWatch's native integration with services such as Bedrock and SageMaker AI for foundational monitoring. For complex RAG patterns, consider building custom CloudWatch dashboards. To capture interaction between various application components, implement distributed tracing using Amazon X-Ray or specialized LLM observability platforms like Langfuse or LangSmith.
Cost tracking: Use AWS cost allocation tags to track spending by feature, environment, or customer segment. Set up AWS Budgets with tag-based filters to receive alerts for anomalies or threshold breaches.
Refinement workflow: Establish weekly reviews of operational dashboards and cost breakdowns to identify optimization opportunities. Use insights to drive immediate improvements like adjusting prompt lengths, switching models for cost- or latency-sensitive workloads, or optimizing retrieval strategies based on usage patterns. Implement an issue tracking system that links production observations to specific pipeline stages requiring adjustment. Automate the collection of problematic queries and responses to inform future testing scenarios.
Quick reference cards: observability & refinement at a glance

Helpful resources:
- Track, allocate, and manage your generative AI cost and usage with Amazon Bedrock
- Using CloudWatch Logs Insights to identify improvement opportunities
Governance and maintenance
Establish lightweight governance practices that protect your startup while enabling rapid iteration. This helps build stakeholder trust without slowing development velocity.
Responsible AI and safety: Implement Amazon Bedrock Guardrails as your first line of defense. Configure content filters for hate speech, violence, and other inappropriate or off-topic content specific to your use case. These guardrails work across Bedrock models and external models, providing real-time protection without impacting development speed.
Version control and documentation: Track AI artifacts systematically using Amazon S3 with versioning enabled, and implement clear naming conventions for models, prompts, and datasets. Create lightweight model cards documenting each AI model's purpose, data sources, limitations, and performance metrics—essential for transparency and future compliance requirements.
Security and compliance: Configure AWS IAM roles following least privilege principles with separate roles for development, testing, and production. Use AWS Secrets Manager for API keys and sensitive configurations. Enable AWS CloudTrail for automatic audit logging, creating essential compliance foundations.
Incident response: Develop simple run-books for common failures: model errors, performance degradation, or cost spikes. Establish clear escalation paths and implement basic backup strategies for critical artifacts.
Quick reference cards: governance and maintenance at a glance

Conclusion
Implementing GenAIOps at earlier startup stages doesn't require massive investment or complex infrastructure. By focusing on the essential elements of each pipeline stage and leveraging AWS managed services, you can build a foundation that supports rapid iteration while establishing the operational practices that will enable future growth.
Remember that the goal at this stage is not perfection but intentionality—creating systems that acknowledge the unique challenges of AI applications while remaining appropriate for your current scale. Start with these essentials, measure what matters to your users, and document your learnings.
In Part 3, we'll show you how to evolve these practices as you begin scaling your operations to meet growing customer demand.

Nima Seifi
Nima Seifi is a Senior Solutions Architect at AWS, based in Southern California, where he specializes in SaaS and GenAIOps. He serves as a technical advisor to startups building on AWS. Prior to AWS, he worked as a DevOps architect in the ecommerce industry for over 5 years, following a decade of R&D work in mobile internet technologies. Nima has 20+ publications in prominent technical journals and conferences and holds 7 US patents. Outside of work, he enjoys reading, watching documentaries, and taking beach walks.

Anu Jayanthi
Anu Jayanthi works with Startup customers, providing advocacy and strategic technical guidance to help plan and build solutions using AWS best practices.
.jpg)
Pat Santora
Pat Santora is a GenAI Labs Cloud Architect and Technologist with over 25 years of experience implementing solutions across the cloud for both enterprises and startups. He has successfully launched numerous products from inception, led analytical re-architecture projects, and managed remote teams with a philosophy centered on transparency and trust. His technical expertise spans strategic planning, systems management, and architectural redesign, complemented by interests in GenAI, Analytics, and Big Data.
.jpg)
Clement Perrot
Clement Perrot helps top-tier startups accelerate their AI initiatives by providing strategic guidance on model selection, responsible AI implementation, and optimized machine learning operations. A serial entrepreneur and Inc 30 Under 30 honoree, he brings deep expertise in building and scaling AI companies, having founded and successfully exited multiple ventures in consumer technology and enterprise AI.
How was this content?