Comment a été ce contenu ?
- Apprendre
- Guide des GenAIOps pour les start-ups sur AWS, partie 2 : Principes essentiels
Guide des GenAIOps pour les start-ups sur AWS, partie 2 : Principes essentiels

Dans la partie 1, nous avons exploré les avantages de l’adoption des GenAIOps dès le premier jour et avons décrit notre pipeline centré sur les applications, conçu spécifiquement pour les start-ups qui développent des produits alimentés par l’IA. Dans la partie 2, nous fournissons des conseils pratiques pour la mise en œuvre des composants essentiels qui vous permettront de passer du prototype aux solutions prêtes à la production.
Pipeline GenAIOps : principes essentiels
La clé d’une mise en œuvre réussie des GenAIOps est d’établir une base de référence solide avec des capacités d’évaluation robustes dès le début, afin de créer ainsi un moteur d’amélioration continue où chaque itération s’appuie sur les enseignements de la précédente. Cela permet d’éviter une dette technique importante tout en permettant des expérimentations rapides.
Découvrons comment implémenter les composants essentiels pour chaque étape de votre pipeline GenAIOps en utilisant des techniques simples mais efficaces. Vous trouverez de plus amples informations sur les services AWS ou tiers les mieux adaptés à chaque étape dans les fiches de référence rapides jointes.
Ingénierie et gestion des données
Établissez un pipeline de données léger pour gérer les artefacts de données essentiels qui alimentent directement votre application d’IA. Concentrez-vous sur les jeux de données clés suivants en fonction de votre cas d’utilisation.
Jeux de données d’invites de sélection de modèle : des jeux de données d’invites d’évaluation standardisés sont essentiels pour une comparaison équitable des modèles.Commencez par utiliser des jeux de données d’analyse comparative conformes aux normes du secteur (MMLU, GPQA, DROP, etc.), des jeux de données d’évaluation intégrés à Amazon Bedrock, ou créez vos propres jeux de données personnalisés spécifiques à un domaine. Ils constituent votre guide d’évaluation des modèles. Revisitez-les lorsque de nouveaux modèles sont publiés ou lorsque vous reconsidérez votre choix de modèle.
Jeux de données d’ingénierie de requête : ces jeux de données incluent vos modèles d’invite et des jeux de données de vérité issue du terrain.Utilisez Amazon Bedrock Prompt Management ou une alternative open source comme Langfuse pour implémenter un catalogue d’invites centralisé permettant de versionner, de tester et de gérer les invites. En outre, créez plus de 100 paires requête-réponse sélectionnées par des humains, qui constituent votre référence absolue en matière de tests et d’optimisation des invites.
Jeux de données de génération à enrichissement contextuel (RAG) : commencez par préparer vos sources de connaissances externes : pour les données non structurées comme la documentation, le processus implique l’ingestion, le découpage et la génération d’intégrations vectorielles à l’aide de modèles Amazon Titan ou Cohere sur Bedrock. Stockez les intégrations dans des bases de données vectorielles gérées comme Amazon OpenSearch sans serveur ou Amazon S3 Vectors ; pour les données structurées, comme les données tabulaires, le processus inclut le prétraitement, l’analyse de schéma, l’enrichissement des métadonnées et le chargement dans des magasins de données structurés pris en charge. Pour les deux types de données, implémentez des mécanismes d’actualisation des données simples mais efficaces afin de maintenir vos sources de connaissances à jour. En outre, créez des jeux de données d’évaluation RAG avec des triplets requête-contexte-réponse pour tester la précision de la récupération et la qualité des réponses.
Jeux de données de personnalisation de modèle : commencez par collecter vos données propriétaires les plus précieuses.Générez des exemples d’entraînement synthétiques lorsque les données exclusives sont insuffisantes.
Fiches de référence rapides : ingénierie et gestion des données en un coup d’œil

Ressources utiles :
- Générez des données synthétiques pour évaluer les systèmes RAG à l’aide d’Amazon Bedrock
- Une introduction à la préparation de votre propre jeu de données pour l’entraînement de LLM

Développement et expérimentation
Au début du développement, les start-ups doivent donner la priorité à la rapidité et à la simplicité, en mettant l’accent sur l’expérimentation rapide grâce à des services à faible code afin d’accélérer les délais de commercialisation.
Sélection des modèles : commencez par des analyses comparitives publiques comme LMArena ou Artificial Analysis pour créer une première liste restreinte, puis affinez la sélection grâce à une évaluation spécifique au cas d’utilisation. Amazon Bedrock permet d’accéder aux principales familles de modèles de fondation (FM). Pour évaluer les modèles sélectionnés, utilisez les évaluations Amazon Bedrock ou Amazon SageMaker Clarify.
Ingénierie de requête : définissez des critères de réussite clairs, alignés sur les objectifs commerciaux et créez des métriques mesurables pour chacun d’entre eux. Rédigez les invites initiales en suivant les directives de conception pour les modèles que vous avez choisis, puis évaluez-les systématiquement par rapport à votre jeu de données de vérité issue du terrain. Tirez parti de l’optimisation des invites d’Amazon Bedrock lors de la rédaction et de l’affinement pour apporter des améliorations spécifiques au modèle. Effectuez des itérations jusqu’à obtenir des résultats cohérents, puis publiez les invites fructueuses dans votre catalogue d’invites avec un contrôle de version approprié.
RAG : tirez parti des options RAG entièrement gérées sur AWS pour rationaliser la mise en œuvre des magasins de données, des récupérateurs, des FM et des orchestrateurs, réduisant ainsi considérablement le temps de développement et les frais opérationnels. Commencez par connecter votre système RAG à des sources de données prises en charge, puis intégrez-le à un FM pour créer un flux de production augmenté complet. Commencez par un domaine de connaissances ciblé pour valider l’efficacité avant de passer à d’autres sources de données. Tirez parti des techniques RAG avancées, comme la modification des requêtes et le reclassement pour améliorer la pertinence des réponses.
Personnalisation du modèle : utilisez des jeux de données d’entraînement pour personnaliser les FM pré-entraînés afin d’améliorer leurs performances dans des cas d’utilisation spécifiques. Commencez toujours par une ingénierie de requête, puis passez à RAG si un contexte supplémentaire est nécessaire. Ne personnalisez le modèle que si les approches précédentes ne répondent pas à vos exigences, en commençant par un jeu de données ciblé provenant d’un domaine pour valider les améliorations avant de l’étendre.
Agents d’IA : créez des assistants alimentés par l’IA capables d’effectuer des tâches complexes et d’interagir avec divers services et API. Les agents Amazon Bedrock gèrent automatiquement une orchestration complexe visant à comprendre les intentions des utilisateurs, à déterminer les actions, à effectuer des appels d’API et à présenter les résultats en langage naturel. Pour une implémentation personnalisée, pensez à utiliser des frameworks open source comme Strands ou LangGraph.
Création et expérimentation d’applications : choisissez votre approche de développement en fonction de l’expertise de votre équipe et des exigences en matière de délais de livraison. AWS propose plusieurs services adaptés aux start-ups (voir ci-dessous), et Amazon Q Developer sert d’assistant basé sur l’IA qui vous aide à comprendre, créer, étendre et exploiter les applications AWS. Établissez des approches d’expérimentation structurées qui permettent une amélioration systématique tout en maintenant une itération rapide. Tenez un journal des expériences contenant des hypothèses, des détails de mise en œuvre et des métriques de résultat, afin de vous assurer que les expériences comportent des critères de réussite clairs liés à des métriques commerciales plutôt qu’à de simples métriques techniques.
Fiches de référence rapide : développement et expérimentation en un coup d’œil

Ressources utiles :
- Évaluation des invites à grande échelle avec la gestion des invites et les flux d’invite pour Amazon Bedrock
- Du concept à la réalité : le parcours de RAG de la validation de concept à la production
- Meilleures pratiques pour créer des applications d’IA générative robustes avec les agents Amazon Bedrock
Tests et évaluation
Établissez des processus simples mais rigoureux pour vérifier que votre application fonctionne de manière fiable et performante, en utilisant les jeux de données d’évaluation créés à l’étape 1. Équilibrez minutie et rapidité pour votre start-up en vous concentrant d’abord sur vos flux de travail utilisateurs les plus critiques.
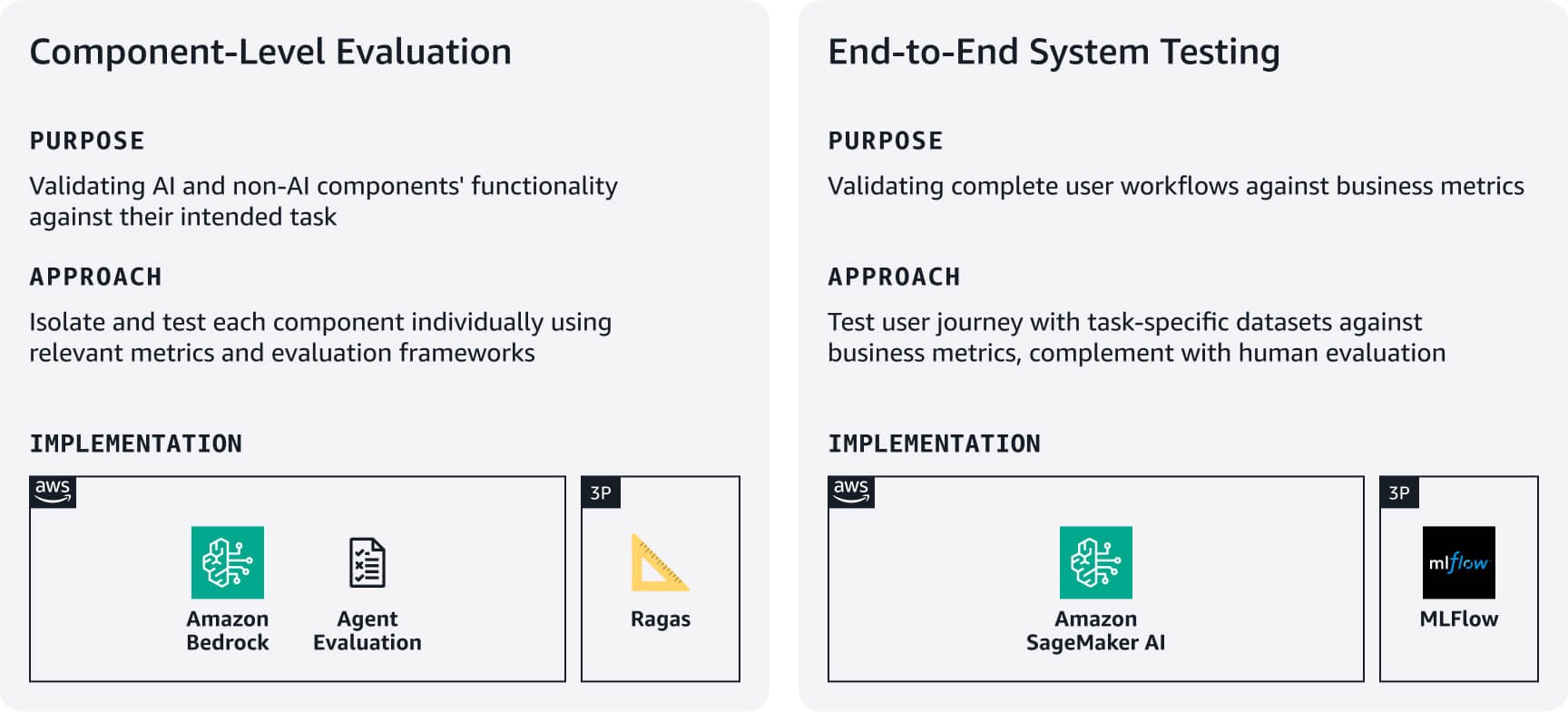
Évaluation au niveau des composants : déterminez dans quelle mesure vos composants IA et non IA exécutent les tâches prévues. Par exemple, pour les systèmes RAG, utilisez les évaluations Amazon Bedrock ou des frameworks comme RAGAS pour évaluer la précision de la récupération et la qualité de la génération de réponses. Pour les agents, tirez parti de frameworks comme l’évaluation des agents ou l’approche LLM-juge pour évaluer des métriques comme les taux d’achèvement des tâches et la précision de l’utilisation des décisions/outils en fonction des exigences de votre cas d’utilisation.
Tests du système de bout en bout : testez les flux de travail complets des utilisateurs à l’aide de jeux de données d’évaluation spécifiques aux tâches. Définissez des métriques de réussite adaptées à l’entreprise pour chaque tâche principale, puis validez que les composants fonctionnent parfaitement tout au long du parcours utilisateur. Complétez les tests automatisés par une évaluation humaine de la qualité des réponses, de la pertinence et de l’alignement de la marque, des aspects que les métriques automatisées ne capturent souvent pas. Utilisez ces résultats d’évaluation pour établir des bases de référence, puis améliorez de manière itérative en fonction des commentaires des utilisateurs et de l’impact commercial. Envisagez d’utiliser MLflow géré sur SageMaker AI pour suivre les expériences sur toutes les versions du système.
Fiches de référence rapide : tests et évaluations en un coup d’œil
Ressources utiles :
- Évaluer les réponses RAG avec Amazon Bedrock, LlamaIndex et RAGAS
- Évaluation de la charge de travail de l’IA générative
Déploiement et mise en service
Commencez par l’option de déploiement la plus simple en fonction de vos exigences techniques et des capacités de votre équipe, puis faites évoluer votre architecture à mesure de votre croissance. L’écosystème AWS fournit des voies de mise à niveau naturelles entre ces modèles de déploiement sans nécessiter de réécritures architecturales complètes.
Déploiement du modèle : commencez par Amazon Bedrock pour accéder immédiatement aux FM via une API unifiée. Si vous avez besoin de modèles spécialisés qui ne sont pas disponibles dans Bedrock, explorez Amazon Bedrock Marketplace ou Amazon SageMaker JumpStart pour découvrir et déployer votre modèle directement sur SageMaker AI.
Hébergement et exploitation des applications : déployez des applications Web modernes à l’aide d’AWS Amplify Hosting. Créez des microservices légers en intégrant les fonctions AWS Lambda avec Amazon API Gateway. Utilisez AWS App Runner comme point d’entrée pour déployer des applications conteneurisées. Pour garantir la fiabilité, implémentez des mécanismes de repli simples : revenez aux réponses du modèle de fondation lorsque la récupération du RAG échoue, passez aux modèles de secours lorsque les modèles principaux ne sont pas disponibles et mettez en cache les requêtes courantes à l’aide d’Amazon MemoryDB. Établissez des disjoncteurs pour les services dépendants afin d’éviter les pannes en cascade. Ces modèles constituent la base de stratégies de résilience plus sophistiquées à mesure que votre base d’utilisateurs augmente.
Orchestration des flux de travail : pour les opérations d’IA complexes qui nécessitent un découplage requête/réponse, combinez Amazon SQS pour la mise en file d’attente des tâches avec AWS Step Functions pour orchestrer les flux de travail en plusieurs étapes. Ce modèle est particulièrement utile pour les opérations chronophages, comme le traitement par lots ou les flux de travail impliquant plusieurs appels de modèle.
Fiches de référence rapide : déploiement et mise en service en un coup d’œil

Ressources utiles :
Observabilité et affinement
Concentrez-vous sur l’observabilité essentielle qui a un impact commercial immédiat tout en minimisant la complexité.
Surveillance des métriques clés : concentrez-vous sur les métriques de performance techniques applicables à votre cas d’utilisation et configurez des alarmes CloudWatch pour les seuils critiques. Suivez l’expérience utilisateur grâce à des mécanismes de rétroacation simples (pouces haut/bas), aux taux d’achèvement des conversations et aux modèles d’utilisation des fonctionnalités. Ils révèlent souvent des problèmes qui échappent aux métriques techniques et ont un impact direct sur la réussite de l’entreprise.
Configuration de l’observabilité essentielle : utilisez l’intégration native d’Amazon CloudWatch avec des services tels que Bedrock et SageMaker AI pour la surveillance fondamentale. Pour les modèles RAG complexes, envisagez de créer des tableaux de bord CloudWatch personnalisés . Pour capturer l’interaction entre les différents composants de l’application, implémentez le traçage distribué à l’aide d’Amazon X-Ray ou de plateformes d’observabilité de LLM spécialisées comme Langfuse ou LangSmith.
Suivi des coûts : utilisez les balises de répartition des coûts AWS pour suivre les dépenses par fonctionnalité, environnement ou segment de clientèle. Configurez AWS Budgets avec des filtres basés sur des balises pour recevoir des alertes en cas d’anomalie ou de dépassement de seuil.
Flux de travail d’affinement : établissez des passages en revue hebdomadaires des tableaux de bord opérationnels et des ventilations des coûts afin d’identifier les opportunités d’optimisation. Utilisez les informations pour apporter des améliorations immédiates, comme l’ajustement de la durée des invites, le changement de modèle pour les charges de travail sensibles aux coûts ou à la latence, ou l’optimisation des stratégies de récupération en fonction des modèles d’utilisation. Mettez en œuvre un système de suivi des problèmes qui relie les observations de production aux étapes spécifiques du pipeline nécessitant un ajustement. Automatisez la collecte des requêtes et réponses problématiques pour éclairer les futurs scénarios de test.
Fiches de référence rapide : observabilité et affinement en un coup d’œil

Ressources utiles :
- Suivez, répartissez et gérez vos coûts et votre utilisation de l’IA générative avec Amazon Bedrock
- Utiliser CloudWatch Logs Insights pour identifier les opportunités d’amélioration
Gouvernance et maintenance
Établissez des pratiques de gouvernance légères qui protègent votre start-up tout en permettant une itération rapide. Cela permet de renforcer la confiance des parties prenantes sans ralentir la vitesse de développement.
IA responsable et sécurité : mettez en œuvre des barrières de protection Amazon Bedrock comme première ligne de défense. Configurez des filtres de contenu pour les discours de haine, la violence et les sujets liés à votre cas d’utilisation. Ces barrières de protection fonctionnent sur tous les modèles Bedrock et les modèles externes, offrant une protection en temps réel sans affecter la vitesse de développement.
Contrôle des versions et documentation : suivez systématiquement les artefacts d’IA à l’aide d’Amazon S3 avec la gestion des versions activée, et mettez en œuvre des conventions de dénomination claires pour les modèles, les invites et les jeux de données. Créez des cartes de modèle légères documentant l’objectif, les sources de données, les limites et les métriques de performance de chaque modèle d’IA, ce qui est essentiel pour la transparence et les futures exigences de conformité.
Sécurité et conformité : configurez les rôles AWS IAM selon le principe du moindre privilège avec des rôles distincts pour le développement, les tests et la production. Utilisez AWS Secrets Manager pour les clés d’API et les configurations sensibles. Activez AWS CloudTrail pour la journalisation automatique des audits, créant ainsi des bases de conformité essentielles.
Réponse aux incidents : élaborez des dossiers d’exploitation simples pour les défaillances courantes : erreurs de modèle, dégradation des performances ou pics de coûts. Établissez des voies d’escalade claires et mettez en œuvre des stratégies de sauvegarde de base pour les artefacts critiques.
Fiches de référence rapides : gouvernance et maintenance en un coup d’œil

Conclusion
La mise en œuvre des GenAIOps dès les premières phases de votre start-up ne nécessite pas d’investissements massifs ni d’infrastructure complexe. En vous concentrant sur les éléments essentiels de chaque étape du pipeline et en tirant parti des services gérés AWS, vous pouvez créer une base qui permet une itération rapide tout en établissant les pratiques opérationnelles qui favoriseront votre croissance future.
N’oubliez pas qu’à ce stade, l’objectif n’est pas la perfection mais l’intentionnalité : créer des systèmes qui reconnaissent les défis uniques des applications d’IA tout en restant adaptés à votre échelle actuelle. Commencez par ces éléments essentiels, mesurez ce qui est important pour vos utilisateurs et documentez vos résultats.
Dans la partie 3, nous vous montrerons comment faire évoluer ces pratiques à mesure que vous commencerez à développer vos opérations pour répondre à la demande croissante de vos clients.

Nima Seifi
Nima Seifi est architecte de solutions senior chez AWS, dans le sud de la Californie, où il est spécialisé dans le SaaS et les GenAIOps. Il sert de conseiller technique pour les start-ups qui s’appuient sur AWS. Avant de rejoindre AWS, il a travaillé comme architecte DevOps dans le secteur de l’e-commerce pendant plus de 5 ans, après une décennie de travail de R&D dans les technologies de l’Internet mobile. Nima est l’auteur de plus de 20 publications dans des revues techniques et des conférences de premier plan, et détient 7 brevets américains. En dehors du travail, il aime lire, regarder des documentaires et se promener sur la plage.

Anu Jayanthi
Anu Jayanthi travaille avec des start-up clientes, fournissant des conseils techniques stratégiques pour les aider à planifier et développer des solutions en utilisant les meilleures pratiques d’AWS.
.jpg)
Pat Santora
Pat Santora est un architecte et technologue cloud pour les laboratoires d’IA générative avec plus de 25 ans d’expérience dans la mise en œuvre de solutions dans le cloud pour les entreprises et les start-ups. Il a lancé avec succès de nombreux produits dès leurs débuts, dirigé des projets de refonte analytique et géré des équipes à distance avec une philosophie axée sur la transparence et la confiance. Son expertise technique couvre la planification stratégique, la gestion des systèmes et la refonte architecturale, complétée par son intérêt pour l’IA générative, l’analytique et le big data.
.jpg)
Clement Perrot
Clément Perrot aide les start-ups de premier plan à accélérer leurs initiatives d’IA en fournissant des conseils stratégiques sur la sélection de modèles, la mise en œuvre de l’IA responsable et l’exécution d’opérations de machine learning optimisées. Entrepreneur en série et lauréat du prix Inc 30 Under 30, il possède une expertise approfondie dans la création et le développement d’entreprises d’IA, ayant fondé et quitté avec succès de nombreuses entreprises dans les domaines des technologies grand public et de l’IA d’entreprise.
Comment a été ce contenu ?