¿Qué le pareció este contenido?
- Aprender
- Guía para startups sobre GenAIOps en AWS, parte 2: aspectos básicos
Guía para startups sobre GenAIOps en AWS, parte 2: aspectos básicos

En la parte 1, analizamos las ventajas de adoptar GenAIOps desde el primer día y describimos nuestra canalización centrada en las aplicaciones, diseñada para las startups que crean productos impulsados por IA. En esta parte 2, ofreceremos una guía práctica para aplicar los componentes fundamentales y pasar de la fase de prototipo a la de soluciones listas para la producción.
Canalización de GenAIOps: aspectos básicos
El elemento esencial para implementar GenAIOps con éxito es establecer una base sólida con capacidades de evaluación desde el principio, lo que crea un círculo virtuoso de mejora continua donde cada iteración se basa en lo aprendido de la anterior. Gracias a ello, se puede evitar la gran deuda técnica y facilitar una experimentación rápida.
Veamos cómo implementar los componentes fundamentales para cada etapa de la canalización de GenAIOps con técnicas sencillas, pero eficaces. Las tarjetas de referencia rápida de más abajo contienen información sobre qué servicios de AWS o de terceros son los más adecuados para cada paso.
Ingeniería y administración de datos
Determine una canalización de datos simplificada para administrar los artefactos de datos necesarios que impulsan de forma directa su aplicación de IA. A continuación, se muestran los conjuntos de datos clave según el caso de uso.
Conjuntos de datos de peticiones de selección de modelos: los conjuntos de datos de peticiones de evaluación estándar son fundamentales para una comparación justa. Comience con los conjuntos de datos de referencia estándar del sector (MMLU, GPQA, DROP, etc.) o con los conjuntos de datos de evaluación integrados en Amazon Bedrock, o también puede crear sus propios conjuntos de datos personalizados para un dominio específico. Estos sirven como guía para la evaluación del modelo. Pero debe revisarlos cuando se publiquen nuevos modelos o cuando desee cambiar de modelo.
Conjuntos de datos de ingeniería de peticiones: contienen las plantillas de peticiones y conjuntos de datos de referencia. Utilice la administración de peticiones de Amazon Bedrock o una alternativa de código abierto como Langfuse para implementar un catálogo de peticiones centralizado para versionarlos, probarlos y administrarlos. Por otra parte, puede crear más de 100 pares de consultas y respuestas seleccionados por personas que representen su estándar de referencia para probar y optimizar las peticiones.
Conjuntos de datos de generación aumentada por recuperación (RAG): comience preparando sus fuentes de conocimiento externas. En el caso de los datos no estructurados como la documentación, el proceso consiste en la ingestión, fragmentación y generación de incrustaciones de vectores con los modelos de Amazon Titan o Cohere en Bedrock. Almacene las incrustaciones en bases de datos vectoriales administradas, como Amazon OpenSearch sin servidor o Amazon S3 Vectors. Para el caso de los datos estructurados como los tabulares, el proceso consiste en el preprocesamiento, el análisis de esquemas, el enriquecimiento de los metadatos y la carga en los almacenes de datos estructurados. Para ambos tipos de datos, implemente mecanismos de actualización de datos simples para mantener las fuentes de conocimiento actuales. Asimismo, cree conjuntos de datos de evaluación de RAG con tripletes de consultas, contexto y respuesta para probar la precisión de la recuperación y la calidad de la respuesta.
Conjuntos de datos de personalización de modelos: recopile sus datos patentados más importantes. Cuando dichos datos no sean suficientes, hay que generar ejemplos sintéticos de formación.
Tarjetas de referencia rápida: resumen de la ingeniería y administración de datos

Recursos útiles:
- Genere datos sintéticos para evaluar los sistemas RAG con Amazon Bedrock
- Una introducción a la preparación de su propio conjunto de datos para la formación de LLM

Desarrollo y experimentación
Durante las primeras etapas del desarrollo, las startups deben priorizar la velocidad y simplicidad, enfocándose en la experimentación rápida a través de servicios de poco código para agilizar el tiempo de salida al mercado.
Selección de modelos: comience con puntos de referencia públicos como LMArena o Artificial Analysis para crear una lista corta, y luego disminuya la selección a través de una evaluación específica para cada caso de uso. Amazon Bedrock permite el acceso a las principales familias de modelos fundacionales (FM). Con las evaluaciones de Amazon Bedrock o Amazon SageMaker Clarify, evalúe los modelos preseleccionados.
Ingeniería de peticiones: defina los criterios claros de éxito que estén alineados con los objetivos empresariales y cree métricas medibles para cada uno. Redacte las peticiones iniciales conforme a las directrices de diseño para los modelos que eligió y luego evalúelas sistemáticamente con respecto al conjunto de datos de referencia. Aproveche la optimización de peticiones de Amazon Bedrock durante el proceso de elaboración y refinamiento para obtener mejoras específicas en cada modelo. Finalmente realice iteraciones hasta obtener resultados consistentes y publique las peticiones correctas en su catálogo de peticiones con la gestión adecuada del control de versiones.
RAG: aproveche las opciones de RAG totalmente administradas en AWS para optimizar la implementación de almacenes de datos, recuperadores, FM y orquestadores, lo que reduce considerablemente el tiempo de desarrollo y la sobrecarga operativa. Comience conectando el sistema RAG a los orígenes de datos compatibles y realice la integración con un FM para crear el flujo de trabajo completo de generación aumentada. Asimismo, empiece con un dominio de conocimiento específico para validar la eficacia antes de expandirse a los orígenes de datos adicionales. Aproveche las técnicas avanzadas de RAG, como la modificación de consultas y el cambio de clasificación, para mejorar la relevancia de las respuestas.
Personalización de modelos: utilice conjuntos de datos de formación para personalizar los FM previamente formados y así mejorar el rendimiento en casos de uso específicos. Comience siempre con una ingeniería de peticiones y luego pase a RAG si se necesita un contexto adicional. Sin embargo, solo personalice el modelo si los enfoques anteriores no cumplen con sus requisitos, partiendo por un conjunto de datos específico de un dominio para validar las mejoras antes de expandirlo.
Agentes de IA: cree asistentes impulsados por IA para realizar tareas complejas e interactuar con numerosas API y servicios. Los agentes de Amazon Bedrock gestionan automáticamente la compleja orquestación para la comprensión de la intención del usuario, la determinación de las acciones, la realización de llamadas a la API y la presentación de los resultados en lenguaje natural. Para realizar una implementación personalizada, tenga en cuenta la posibilidad de utilizar marcos de código abierto como Strands o LangGraph.
Creación y experimentación de aplicaciones: elija su enfoque de desarrollo según los requisitos de experiencia y cronograma de entrega de su equipo. AWS ofrece diversos servicios adecuados para startups (consultar más abajo), y Amazon Q Developer actúa como un asistente basado en IA que ayuda a comprender, crear, ampliar y operar las aplicaciones de AWS. Establezca enfoques de experimentación estructurados que permitan una mejora sistemática y que mantengan una iteración rápida. Mantenga un registro de experimentos con hipótesis, detalles de implementación y métricas de resultados, ya que esto asegura que los experimentos tengan criterios claros de éxito relacionados con las métricas empresariales y no solo con las técnicas.
Tarjetas de referencia rápida: resumen del desarrollo y experimentación

Recursos útiles:
- Evaluación de las solicitudes a escala con la administración de peticiones y de flujos para Amazon Bedrock
- Del concepto a la realidad: recorrer el camino de RAG desde la prueba de concepto hasta la producción
- Prácticas recomendadas para crear aplicaciones de IA generativa sólidas con agentes de Amazon Bedrock
Entrenamiento y evaluación
Establezca procesos ágiles y rigurosos para verificar que su aplicación funcione bien y de manera confiable a través de los conjuntos de datos de evaluación creados en la etapa 1. Equilibre la minuciosidad con la velocidad inicial al centrarse primero en los flujos de trabajo de los usuarios más cruciales.
Evaluación a nivel de componentes: mida la funcionalidad de sus componentes de IA, y no relacionados con la IA, con las tareas previstas. Por ejemplo, en los sistemas RAG utilice las evaluaciones de Amazon Bedrock o marcos como RAGAS para evaluar la precisión de la recuperación y la calidad de la generación de respuestas. En el caso de los agentes, aproveche marcos como la evaluación de agentes o el enfoque de LLM como juez para evaluar métricas como las tasas de finalización de las tareas y la precisión en el uso de las decisiones y herramientas según los requisitos de cada caso de uso.
Pruebas del sistema de extremo a extremo: pruebe los flujos de trabajo completos de los usuarios con los conjuntos de datos de evaluación específicos de tareas. Defina métricas de éxito alineadas con la empresa para cada tarea principal y verifique que los componentes funcionen sin problemas en todos los recorridos de usuarios. Asimismo, complemente las pruebas automatizadas con una evaluación humana con respecto a la calidad de la respuesta, relevancia y alineación de la marca, los cuales son aspectos que las métricas automatizadas suelen pasar por alto. Con los resultados de estas evaluaciones, podrá establecer puntos de referencia y mejorar de forma iterativa según los comentarios de los usuarios y el impacto empresarial. Tenga en cuenta la posibilidad de utilizar MLFlow administrado en SageMaker AI para realizar un seguimiento de los experimentos en todas las versiones del sistema.
Tarjetas de referencia rápida: resumen del entrenamiento y evaluación
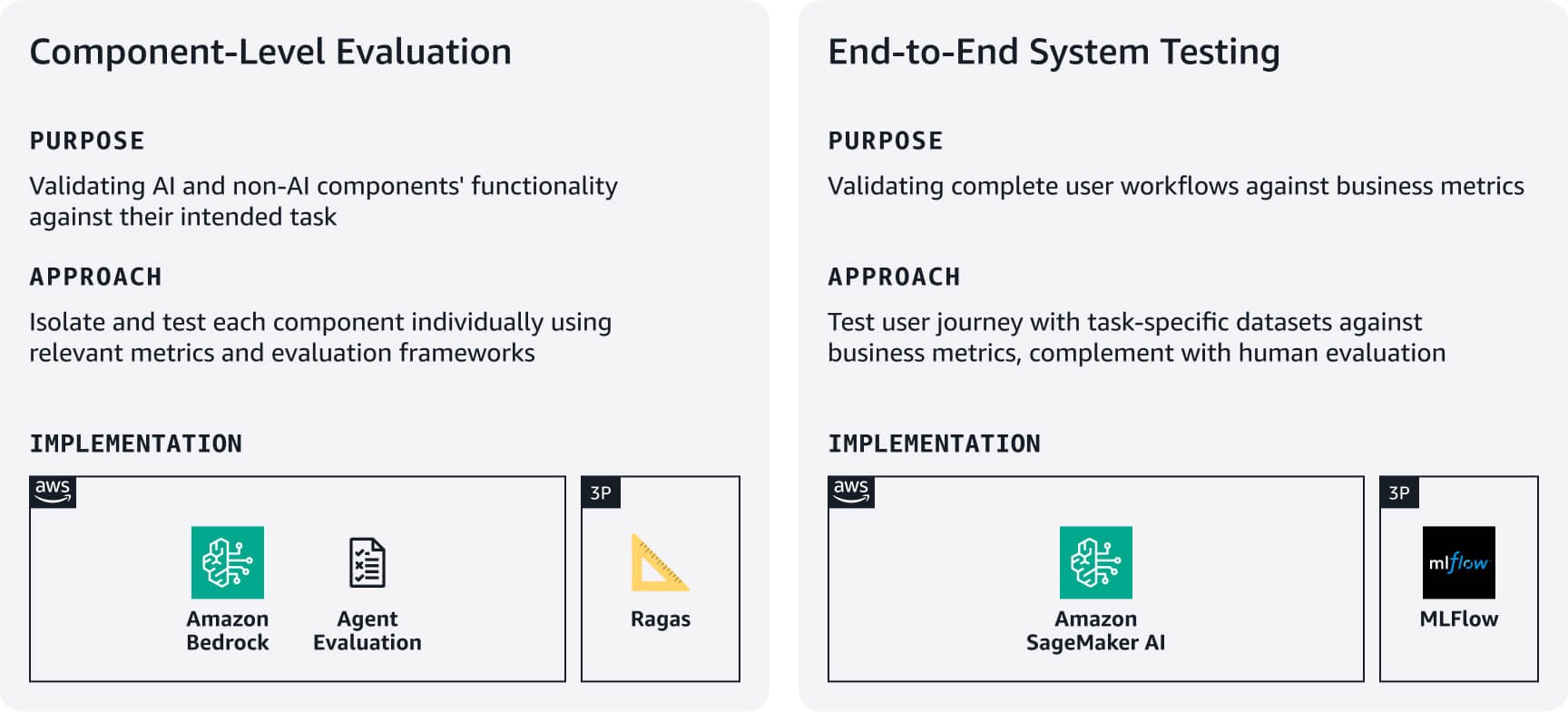
Recursos útiles:
- Evalúe las respuestas de RAG con Amazon Bedrock, LlamaIndex y RAGAS
- Evaluación de la carga de trabajo de la IA generativa
Implementación y servicio
Comience con la opción de implementación más sencilla dependiendo de los requisitos técnicos y las capacidades de su equipo. Finalmente, evolucione su arquitectura a medida que vaya creciendo. El ecosistema de AWS ofrece rutas de actualización naturales entre estos patrones de implementación sin necesidad de realizar reescrituras arquitectónicas completas.
Despliegue de modelos: comience con Amazon Bedrock para obtener acceso inmediato a las máquinas virtuales con una API unificada. Si necesita modelos especializados que no están disponibles en Bedrock, pruebe con Amazon Bedrock Marketplace o Amazon SageMaker JumpStart para descubrir e implementar su modelo directamente en SageMaker AI.
Operación y alojamiento de aplicaciones: implemente aplicaciones web modernas con AWS Amplify Hosting. Cree microservicios simplificados al integrar funciones de AWS Lambda con Amazon API Gateway. Utilice AWS App Runner como punto de partida para implementar aplicaciones en contenedores. Asimismo, implemente mecanismos de respaldo sencillos para garantizar la fiabilidad: recurra a las respuestas del modelo base cuando el RAG no se recupere, cambie a modelos de respaldo cuando los modelos principales no estén disponibles y almacene en caché las preguntas comunes con Amazon MemoryDB. También puede establecer interruptores para los servicios dependientes a fin de evitar fallos en cascada. Estos patrones forman la base de estrategias de resiliencia más sofisticadas a medida que crece su base de usuarios.
Orquestación del flujo de trabajo: en el caso de las operaciones de IA complejas que necesitan desvincular la solicitud y respuesta, combine Amazon SQS para la cola de tareas con AWS Step Functions con el fin de orquestar los flujos de trabajo que contienen numerosos pasos. Este patrón es esencial para las operaciones que consumen mucho tiempo, como, por ejemplo, el procesamiento por lotes o los flujos de trabajo con múltiples llamadas a modelos.
Tarjetas de referencia rápida: resumen de la implementación y servicio

Recursos útiles:
Observabilidad y refinamiento
Priorice la observabilidad clave que ofrece un impacto inmediato en el negocio y reduce la complejidad.
Monitoreo de métricas clave: concéntrese en las métricas de rendimiento técnico, según corresponda al caso de uso, y configure las alarmas de CloudWatch para los umbrales críticos. Realice un seguimiento de la experiencia de usuario con mecanismos de comentarios sencillos (aprobación o rechazo), con tasas de finalización de las conversaciones y con los patrones de uso de las características. Estos suelen revelar problemas que las métricas técnicas pasan por alto y repercuten directamente en el éxito empresarial.
Configuración de observabilidad primordial: utilice la integración nativa de Amazon CloudWatch con servicios como Bedrock y SageMaker AI como monitoreo fundamental. En el caso de los patrones RAG complejos, tenga en cuenta la posibilidad de crear paneles de CloudWatch personalizados. Si desea capturar la interacción entre múltiples componentes de la aplicación, implemente el seguimiento distribuido con Amazon X-Ray o plataformas de observabilidad de LLM especializadas, como Langfuse o LangSmith.
Seguimiento de costos: utilice las etiquetas de asignación de costos de AWS para realizar un seguimiento de los gastos por característica, entorno o segmento de clientes. Además, configure AWS Budgets con filtros basados en etiquetas para recibir alertas en caso de anomalías o infracciones de los umbrales.
Refinamiento del flujo de trabajo: determine revisiones semanales de los paneles operativos y los desgloses de costos para identificar las oportunidades de optimización. También utilice la información para impulsar mejoras inmediatas, como, por ejemplo, ajustar la duración de las solicitudes, cambiar de modelo para cargas de trabajo sensibles a los costos o a la latencia, u optimizar las estrategias de recuperación según los patrones de uso. Asimismo, implemente un sistema de seguimiento de problemas que vincule las observaciones de la producción con las etapas específicas del proceso que necesitan ajustes. Finalmente, automatice la recopilación de consultas y respuestas problemáticas para informar sobre futuros escenarios de prueba.
Tarjetas de referencia rápida: resumen de la observabilidad y refinamiento

Recursos útiles:
- Realice el seguimiento, la asignación y la administración de los costos y el uso de la IA generativa con Amazon Bedrock
- Uso de la Información de registros de CloudWatch para identificar oportunidades de mejora
Gobernanza y mantenimiento
Establezca prácticas de gobernanza simplificadas que protejan su startup y que permitan una iteración rápida. Esto ayuda a aumentar la confianza de las partes interesadas sin reducir la velocidad de desarrollo.
IA responsable y seguridad: implemente Amazon Bedrock Guardrails como primera barrera de protección. Configure filtros de contenido para casos como la incitación al odio, la violencia y otro contenido inadecuado o no relacionado específico del caso de uso. Estas barreras funcionan en los modelos externos y en los de Bedrock, y entregan protección en tiempo real sin afectar a la velocidad de desarrollo.
Control de versiones y documentación: realice un seguimiento sistemático de los artefactos de IA con Amazon S3 gracias al control de versiones, e implemente convenciones de identificación para los modelos, las solicitudes y los conjuntos de datos. Cree fichas del modelo simplificadas que documenten el objetivo, los orígenes de datos, las limitaciones y las métricas de rendimiento de cada modelo de IA (primordial para la transparencia y los futuros requisitos de cumplimiento).
Seguridad y cumplimiento: configure los roles de AWS IAM conforme a los principios del privilegio mínimo a través de funciones independientes para el desarrollo, las pruebas y la producción. Utilice AWS Secrets Manager para las claves de API y las configuraciones confidenciales. Habilite AWS CloudTrail para el registro automático de auditorías que crea importantes bases de cumplimiento.
Respuesta ante incidentes: desarrolle sencillos programas de ejecución para las fallas más comunes, como, por ejemplo, los errores de modelo, la degradación del rendimiento o el alza de costos. Además, defina rutas de escalamiento e implemente estrategias básicas de respaldo para los artefactos críticos.
Tarjetas de referencia rápida: resumen de la gobernanza y mantenimiento

Conclusión
La implementación de GenAIOps en las primeras etapas no necesita de una inversión masiva ni de una infraestructura compleja. Al centrarse en los elementos fundamentales de cada fase del proceso y aprovechar los servicios administrados por AWS, puede crear una base que permita una iteración rápida y establecer las prácticas operativas que permitirán el crecimiento futuro.
No olvide que el objetivo en esta etapa no es la perfección sino la intencionalidad. Se trata de crear sistemas que reconozcan los desafíos únicos de las aplicaciones de IA sin dejar de ser apropiados para su escala actual. Comience con estos elementos fundamentales, observe lo que es importante para sus usuarios y documente lo que ha aprendido.
En la parte 3, mostraremos cómo evolucionar estas prácticas a medida que comience a escalar sus operaciones para satisfacer la creciente demanda de los clientes.

Nima Seifi
Nima Seifi es arquitecto de soluciones sénior en AWS, vive en el sur de California y está especializado en SaaS y GenAIOps. Trabaja como asesor técnico para startups que utilizan AWS. Antes de incorporarse a AWS, trabajó como arquitecto de DevOps en el sector del comercio electrónico durante más de 5 años, tras una década de trabajo de I+D en tecnologías de Internet móvil. Nima tiene más de 20 publicaciones en importantes revistas técnicas y conferencias y posee 7 patentes registradas en EE. UU. En su tiempo libre, le gusta leer, ver documentales y pasear por la playa.

Anu Jayanthi
Anu Jayanthi trabaja con startups a las que brinda apoyo y asesoramiento técnico estratégico para que puedan planificar y crear soluciones según las prácticas recomendadas de AWS.
.jpg)
Pat Santora
Pat Santora es un arquitecto de nube de laboratorios de IA generativa y tecnólogo, y cuenta con más de 25 años de experiencia en la implementación de soluciones en la nube, tanto para empresas como para startups. Ha lanzado con éxito numerosos productos en los que ha participado desde su creación, ha dirigido proyectos de rearquitectura analítica y ha administrado equipos remotos con una filosofía centrada en la transparencia y la confianza. Su experiencia y conocimientos técnicos abarcan la planificación estratégica, la administración de sistemas y el rediseño arquitectónico, y se complementan con su interés en IA generativa, análisis y macrodatos.
.jpg)
Clement Perrot
Clement Perrot ayuda a startups de primer nivel a acelerar sus iniciativas de IA mediante orientación estratégica sobre la selección de modelos, la implementación de la IA responsable y la optimización de las operaciones de machine learning. Emprendedor en serie y parte de la lista Inc 30 Under 30, aporta una amplia experiencia en la creación y el crecimiento de empresas de IA, y ha fundado y vendido con éxito múltiples empresas en el campo de la tecnología de consumo y la IA empresarial.
¿Qué le pareció este contenido?