이 콘텐츠는 어떠셨나요?
- 학습
- 스타트업을 위한 AWS 기반 GenAIOps 가이드 2부: 기본 사항
스타트업을 위한 AWS 기반 GenAIOps 가이드 2부: 기본 사항

1부에서는 첫날부터 GenAIOps 도입의 이점을 살펴보고 AI 기반 제품을 개발하는 스타트업을 위해 특별히 설계된 애플리케이션 중심 파이프라인을 설명했습니다. 이제 2부에서는 프로토타입에서 프로덕션 수준의 솔루션으로 전환할 수 있도록 필수 구성 요소를 구현하기 위한 실질적인 가이드를 제공합니다.
GenAIOps 파이프라인: 기본 사항
성공적인 GenAIOps 구현의 핵심은 강력한 평가 기능을 갖춘 견고한 기준을 조기에 수립하여, 각 반복이 이전 반복에서 배운 내용을 기반으로 하는 지속적인 개선 플라이휠을 만드는 것입니다. 이를 통해 상당한 기술적 부채를 방지하는 동시에 신속한 실험이 가능합니다.
간결하지만 효과적인 기술을 사용하여 GenAIOps 파이프라인의 각 단계에 필수 구성 요소를 구현하는 방법을 살펴보겠습니다. 각 단계에 가장 적합한 AWS 또는 타사 서비스에 대한 자세한 내용은 함께 제공되는 간편 참조 카드에서 확인할 수 있습니다.
데이터 엔지니어링 및 관리
경량 데이터 파이프라인을 구축하여 AI 애플리케이션을 직접 구동하는 필수 데이터 아티팩트를 관리하세요. 사용 사례에 따라 다음과 같은 주요 데이터세트에 집중하세요.
모델 선택 프롬프트 데이터세트: 공정한 모델 비교를 위해서는 표준화된 평가용 프롬프트 데이터세트가 매우 중요합니다. 산업 표준 벤치마크 데이터세트(MMLU, GPQA, DROP 등)로 시작하거나, Amazon Bedrock 내장 평가 데이터세트를 활용하거나, 자체 맞춤형 도메인별 데이터세트를 구축하세요. 이러한 데이터세트는 모델 평가 플레이북 역할을 합니다. 새 모델이 출시되거나 모델 선택을 재검토할 때 다시 참고하세요.
프롬프트 엔지니어링 데이터세트: 이 데이터세트에는 프롬프트 템플릿과 정답 데이터세트가 포함됩니다. Amazon Bedrock Prompt Management 또는 Langfuse와 같은 오픈소스 대안을 활용하여 프롬프트를 버전 관리하고 테스트하며 중앙에서 관리할 수 있는 프롬프트 카탈로그를 구현하세요. 또한, 프롬프트 테스트와 최적화를 위한 기준으로서 사람이 검증한 100개 이상의 쿼리-응답 쌍을 생성하세요.
검색 증강 생성(RAG) 데이터세트: 외부 지식 소스를 준비하는 것으로 시작하세요. 문서와 같은 비정형 데이터의 경우, Bedrock에 있는 Amazon Titan 또는 Cohere의 모델을 사용한 데이터 수집, 청킹 및 벡터 임베딩 등의 과정을 거칩니다. 생성된 임베딩은 Amazon OpenSearch Serverless 또는 Amazon S3 Vectors와 같은 관리형 벡터 데이터베이스에 저장합니다. 테이블형 데이터와 같은 정형 데이터의 경우, 전처리, 스키마 분석, 메타데이터 보강, 지원되는 정형 데이터 저장소로 로딩 등의 과정을 거칩니다. 두 데이터 유형 모두 지식 소스를 최신 상태로 유지하기 위해 간단하지만 효과적인 데이터 갱신 메커니즘을 구현해야 합니다. 또한, 검색 정확도와 응답 품질을 테스트하기 위해 쿼리-컨텍스트-응답 삼중 구조의 RAG 평가 데이터세트를 생성합니다.
모델 사용자 지정 데이터세트: 가장 중요한 자체 보유 데이터를 수집하는 것부터 시작하세요. 자체 보유 데이터가 부족한 경우 합성 학습 예제를 생성하세요.
간편 참조 카드: 데이터 엔지니어링 및 관리 개요

유용한 리소스:

개발 및 실험
초기 개발 단계에서 스타트업은 속도와 단순성을 우선시하고 로우코드 서비스를 통한 신속한 실험에 초점을 맞춰 시장 출시 시간을 단축해야 합니다.
모델 선택: LMArena 또는 Artificial Analysis와 같은 공개 벤치마크를 시작점으로 초기 후보 목록을 작성한 후, 사용 사례별 평가를 통해 후보를 좁혀 나갑니다. Amazon Bedrock을 통해 주요 파운데이션 모델(FM) 패밀리에 접근할 수 있습니다. 후보 모델을 평가하려면 Amazon Bedrock 평가 도구 세트 또는 Amazon SageMaker Clarify를 활용하세요.
프롬프트 엔지니어링: 비즈니스 목표와 일치하는 명확한 성공 기준을 정의하고, 각 기준에 대해 측정 가능한 지표를 만듭니다. 선택한 모델에 대한 설계 지침에 따라 초기 프롬프트를 작성한 후, 정답 데이터세트와 비교하여 체계적으로 평가합니다. 프롬프트 작성 및 개선 과정에서는 Amazon Bedrock의 프롬프트 최적화를 활용하여 모델별 성능을 향상시킵니다. 일관된 결과가 나올 때까지 반복한 후, 성공적인 프롬프트를 적절한 버전 관리를 적용하여 프롬프트 카탈로그에 게시합니다.
RAG: AWS의 완전 관리형 RAG 옵션을 활용하여 데이터 스토어, 리트리버, FM, 오케스트레이터 구현을 간소화하여 개발 시간과 운영 부담을 크게 줄이세요. 먼저 RAG 시스템을 지원되는 데이터 소스와 연결한 후, FM과 통합하여 완전한 증강 생성 워크플로를 구축합니다. 하나의 집중된 지식 도메인부터 시작하여 효과를 검증한 후 추가 데이터 소스로 확장하세요. 쿼리 수정 및 순위 재지정과 같은 고급 RAG 기법을 활용하여 응답의 적합성을 향상시킬 수 있습니다.
모델 사용자 지정: 특정 사용 사례에서 성능 개선을 위해 학습 데이터세트를 활용하여 사전 학습된 FM을 사용자 지정합니다. 항상 먼저 프롬프트 엔지니어링을 수행한 후, 추가 컨텍스트가 필요한 경우 RAG를 적용하세요. 이전의 접근 방식으로 요구사항을 충족하지 못하는 경우에만 모델 사용자 지정을 진행하고, 개선 효과를 검증하기 위해 한 도메인의 집중 데이터세트부터 시작하고 이후 확장하세요.
AI 에이전트: 복잡한 작업을 수행하고 다양한 API 및 서비스와 상호작용할 수 있는 AI 기반 어시스턴트를 생성합니다. Amazon Bedrock Agents는 사용자 의도 이해, 수행할 작업 결정, API 호출, 결과를 자연어로 제공하는 복잡한 오케스트레이션을 자동으로 처리합니다. 맞춤형 구현을 위해서는 Strands 또는LangGraph와 같은 오픈소스 프레임워크를 고려할 수 있습니다.
애플리케이션 구축 및 실험: 팀의 전문 지식과 제공 일정 요구 사항에 따라 개발 접근 방식을 선택합니다. AWS는 스타트업에 적합한 여러 서비스를 제공하며(아래 참조), Amazon Q Developer는 AWS 애플리케이션을 이해, 구축, 확장 및 운영하는 데 도움을 주는 AI 기반 어시스턴트 역할을 합니다. 빠른 반복을 유지하면서 체계적인 개선을 가능하게 하는 구조화된 실험 접근 방식을 수립합니다. 가설, 구현 세부 정보, 결과 지표가 포함된 실험 로그를 유지하여 단순한 기술 지표가 아닌 비즈니스 지표와 관련된 명확한 성공 기준을 실험에 포함시킵니다.
간편 참조 카드: 개발 및 실험 개요

유용한 리소스:
- Amazon Bedrock의 프롬프트 관리 및 프롬프트 플로우를 통한 대규모 프롬프트 평가
- 개념에서 현실로: 개념 증명에서 프로덕션까지 RAG의 여정 탐색
- Amazon Bedrock Agents를 사용하여 강력한 생성형 AI 애플리케이션을 구축하기 위한 모범 사례
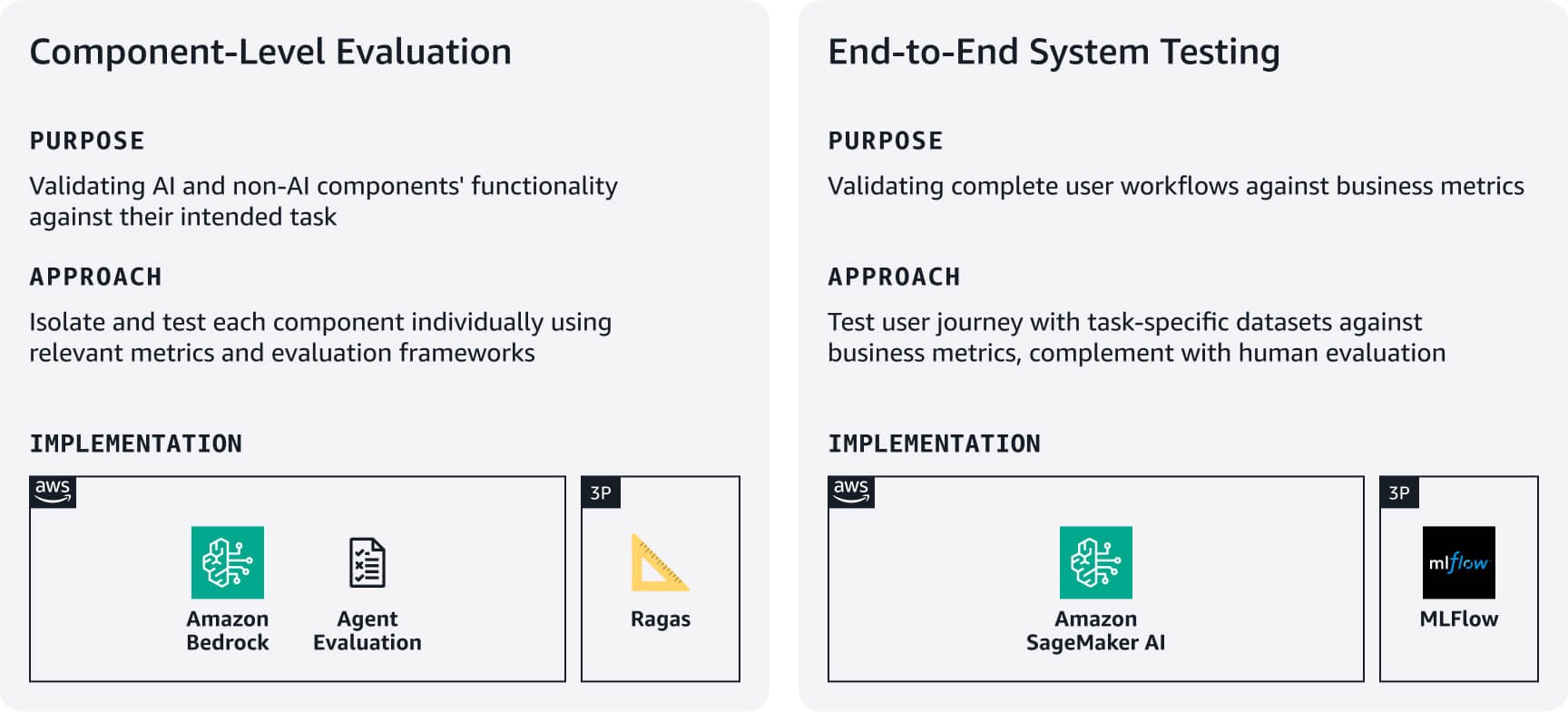
테스트 및 평가
1단계에서 생성한 평가 데이터세트를 활용하여, 애플리케이션이 안정적으로 작동하고 성능이 우수한지 검증할 수 있는 간결하면서도 철저한 프로세스를 구축합니다. 가장 중요한 사용자 워크플로에 집중하여 철저함과 스타트업 속도 사이의 균형을 유지합니다.
구성 요소 수준 평가: AI 및 AI 외의 구성 요소가 의도한 태스크를 얼마나 잘 수행하는지 측정합니다. 예를 들어, RAG 시스템의 경우 Amazon Bedrock 평가 도구 세트 또는 RAGAS와 같은 프레임워크를 활용하여 검색 정확도 및 응답 생성 품질을 평가합니다. 에이전트의 경우, 에이전트 평가 또는 평가형 LLM 접근 방식과 같은 프레임워크를 활용하여 사용 사례 요구 사항에 따라 태스크 완료율이나 결정 및 도구 사용 정확도와 같은 지표를 평가합니다.
엔드 투 엔드 시스템 테스트: 작업별 평가 데이터세트를 사용하여 전체 사용자 워크플로를 테스트합니다. 각 핵심 작업에 대해 비즈니스에 맞는 성공 지표를 정의한 다음 구성 요소가 사용자 여정 전반에서 원활하게 작동하는지 검증합니다. 자동화된 지표가 놓치기 쉬운 측면인 응답 품질, 관련성, 브랜드 일치를 사람이 평가하여 자동화된 테스트를 보완합니다. 이러한 평가 결과를 바탕으로 기준을 설정한 다음 사용자 피드백과 비즈니스 영향에 따라 반복적으로 개선합니다. 시스템 버전 전반에서 실험을 추적하도록 SageMaker AI에서 관리형 MLFlow를 사용하는 것을 고려해 보세요.
간편 참조 카드: 한눈에 보는 테스트 및 평가
유용한 리소스:
배포 및 서비스
기술 요구 사항과 팀 역량을 기반으로 가장 간단한 배포 옵션으로 시작한 다음 성장에 따라 아키텍처를 발전시키세요. AWS 에코시스템은 아키텍처를 완전히 다시 작성할 필요 없이 이러한 배포 패턴 간에 자연스러운 업그레이드 경로를 제공합니다.
모델 배포: 통합 API를 통해 즉시 FM에 접근하려면 Amazon Bedrock부터 시작하세요. Bedrock에서 제공되지 않는 특화 모델이 필요한 경우, Amazon Bedrock Marketplace 또는 Amazon SageMaker JumpStart로 모델을 탐색하고 SageMaker AI에 직접 배포하세요.
애플리케이션 호스팅 및 운영: AWS Amplify Hosting을 사용하여 최신 웹 애플리케이션을 배포합니다. AWS Lambda 함수와 Amazon API Gateway를 통합하여 경량 마이크로서비스를 구축합니다. 컨테이너화된 애플리케이션 배포의 진입점으로 AWS App Runner를 사용합니다. 신뢰성을 확보하기 위해 단순한 폴백 메커니즘을 구현합니다. 예를 들어, RAG 검색 실패 시 기본 모델 응답으로 대체하고, 주요 모델을 사용할 수 없을 때 백업 모델로 전환하고, Amazon MemoryDB를 통해 자주 사용되는 쿼리를 캐싱합니다. 종속 서비스에 대한 서킷 브레이커를 설정하여 연쇄 장애를 방지합니다. 이러한 패턴은 사용자 기반이 성장함에 따라 보다 정교한 복원력 전략의 토대가 됩니다.
워크플로 오케스트레이션: 요청/응답 분리가 필요한 복잡한 AI 작업의 경우, 작업 대기열을 위한 Amazon SQS과 다단계 워크플로 오케스트레이션을 위한 AWS Step Functions를 결합하여 사용하세요. 이 패턴은 배치 처리나 여러 모델 호출이 포함된 워크플로와 같이 시간이 많이 소요되는 작업에서 특히 유용합니다.
간편 참조 카드: 한눈에 보는 배포 및 서비스

유용한 리소스:
관찰성 및 개선
복잡성을 최소화하면서 즉각적인 비즈니스 영향을 이끌어내는 필수 관찰성에 집중하세요.
핵심 지표 모니터링: 사용 사례에 해당하는 기술 성능 지표에 집중하고, 중요한 임계값에 대해 CloudWatch 알람을 설정합니다. 간단한 피드백 메커니즘(좋아요/싫어요), 대화 완료율, 기능 사용 패턴을 통해 사용자 경험을 추적합니다. 이는 기술적 지표가 놓치기 쉬운 문제를 드러내고 비즈니스 성과에 직접적인 영향을 미치는 경우가 많습니다.
필수 관찰성 설정: 기본 모니터링을 위해 Bedrock 및 SageMaker AI 등 서비스와의 Amazon CloudWatch의 기본 통합을 사용합니다. 복잡한 RAG 패턴의 경우, 사용자 지정 CloudWatch 대시보드 구축을 고려해 보세요. 다양한 애플리케이션 구성 요소 간의 상호작용을 파악하기 위해 Amazon X-Ray 또는 Langfuse나 LangSmith 등 전문 LLM 관찰 가능성 플랫폼을 활용한 분산 추적을 구현합니다.
비용 추적: AWS 비용 할당 태그를 사용하여 기능, 환경 또는 고객 세그먼트별 지출을 추적합니다. 태그 기반 필터가 있는 AWS Budgets를 설정하여 이상 지출이나 임계값 위반 시 알림을 받습니다.
개선 워크플로: 운영 대시보드 및 비용 내역을 매주 검토하여 최적화 기회를 파악합니다. 인사이트를 활용하여 프롬프트 길이 조정, 비용 또는 지연 시간에 민감한 워크로드의 모델 전환, 사용 패턴에 따른 검색 전략 최적화 등 즉각적인 개선을 이끌어냅니다. 프로덕션 관찰을 조정이 필요한 특정 파이프라인 단계에 연결하는 문제 추적 시스템을 구현합니다. 문제가 되는 쿼리와 응답의 수집을 자동화하여 향후 테스트 시나리오에 정보를 제공합니다.
간편 참조 카드: 한눈에 보는 관찰성 및 개선

유용한 리소스:
거버넌스 및 유지 관리
빠른 반복을 지원하는 동시에 스타트업을 보호하는 간단한 거버넌스 관행을 수립합니다. 이를 통해 개발 속도를 늦추지 않고도 이해관계자의 신뢰를 구축할 수 있습니다.
책임 있는 AI 및 안전: Amazon Bedrock Guardrails를 최초 방어선으로 구현합니다. 사용 사례에 특정된 증오 발언, 폭력, 관련된 주제에서 벗어난 콘텐츠에 대한 콘텐츠 필터를 구성합니다. 이러한 가드레일은 Bedrock 모델 및 외부 모델 모두에서 작동하여 개발 속도에 영향을 주지 않으면서 실시간 보호를 제공합니다.
버전 관리 및 문서화: 버전 관리가 활성화된 Amazon S3를 활용하여 AI 아티팩트를 체계적으로 추적하고, 모델, 프롬프트, 데이터세트에 대해 명확한 명명 규칙을 적용합니다. 각 AI 모델의 목적, 데이터 출처, 한계, 성능 지표를 기록한 경량 모델 카드를 작성하세요. 투명성을 확보하고 향후 규제 준수 요구 사항에 대비하는 데 필수적입니다.
보안 및 규정 준수: 개발, 테스트, 운영 환경별로 별도의 AWS IAM 역할을 구성하고 최소 권한 원칙을 적용합니다. API 키 및 민감한 구성 정보는 AWS Secrets Manager를 사용하여 관리합니다. 자동 감사 로그 생성을 위해 AWS CloudTrail을 활성화하여 필수적인 규정 준수 기반을 마련합니다.
인시던트 대응: 모델 오류, 성능 저하, 비용 급증 등 일반적인 실패에 대한 간단한 런북을 작성합니다. 명확한 에스컬레이션 경로를 설정하고 중요한 아티팩트에 대한 기본 백업 전략을 구현합니다.
간편 참조 카드: 한눈에 보는 거버넌스 및 유지 보수

결론
초기 시작 단계에서 GenAIOps를 구현하는 데는 대규모 투자나 복잡한 인프라가 필요하지 않습니다. 각 파이프라인 단계의 필수 요소에 집중하고 AWS 관리형 서비스를 활용하면 빠른 반복을 지원하면서 향후 성장을 가능하게 하는 운영 관행의 기반을 마련할 수 있습니다.
이 단계의 목표는 완벽함이 아니라 의도성에 있다는 점을 기억하세요. 즉, AI 애플리케이션이 가진 고유한 과제를 고려하면서도 현재 규모에 적합한 시스템을 만드는 것입니다. 이러한 필수 사항부터 시작하여 사용자에게 중요한 지표를 측정하고 학습한 내용을 문서화하세요.
3부에서는 증가하는 고객 수요에 맞춰 운영을 확장하기 시작하면서 이러한 관행을 발전시키는 방법을 보여드리겠습니다.

Nima Seifi
Nima Seifi는 남부 캘리포니아에 본사를 둔 AWS의 Senior Solutions Architect로, SaaS 및 GenAIOps를 전문으로 합니다. Nima는 AWS를 기반으로 하는 스타트업의 기술 고문으로 활동하고 있습니다. AWS에 입사하기 전에는 모바일 인터넷 기술 분야에서 10년간 R&D 업무를 맡아 수행했고, 그 이후에는 전자 상거래 업계에서 DevOps 아키텍트로 5년 이상 근무했습니다. Nima는 저명한 기술 저널과 컨퍼런스에 20개 이상의 간행물을 출판했으며 7개의 미국 특허를 보유하고 있습니다. 업무 외 시간에는 독서, 다큐멘터리 감상, 해변 산책을 즐깁니다.

Anu Jayanthi
Anu Jayanthi는 스타트업 고객과 협력하여 AWS 모범 사례를 사용하여 솔루션을 계획하고 구축하는 데 도움이 되는 지지 및 전략적 기술 지침을 제공합니다.
.jpg)
Pat Santora
Pat Santora는 GenAI Labs Cloud Architect이자 Technologist로, 25년 이상 기업과 스타트업을 위해 클라우드 전반에서 솔루션을 구현한 경험이 있습니다. Pat는 처음부터 수많은 제품을 성공적으로 출시했으며, 분석 재구성 프로젝트를 주도했으며, 투명성과 신뢰에 중점을 둔 철학을 바탕으로 원격 팀을 관리했습니다. 기술 전문 분야로는 전략 계획, 시스템 관리 및 아키텍처 재설계 분야가 있으며, GenAI, 분석 및 빅 데이터에 대한 관심도 더해졌습니다.
.jpg)
Clement Perrot
Clement Perrot은 모델 선택, 책임 있는 AI 구현, 최적화된 기계 학습 운영에 대한 전략적 지침을 제공하여 최상위 스타트업이 AI 이니셔티브를 가속화할 수 있도록 지원합니다. 연쇄 창업가이자 Inc 30 Under 30 수상자인 Clement는 소비자 기술 및 엔터프라이즈 AI 분야에서 AI 기업 설립 및 확장에 깊이 있는 전문 지식을 갖추고 여러 벤처를 설립하고 성공적으로 사업을 마무리한 경험이 있습니다.
이 콘텐츠는 어떠셨나요?