このコンテンツはいかがでしたか?
- 学ぶ
- AWS での GenAIOps に関するスタートアップ向けガイドパート 2: 要点
AWS での GenAIOps に関するスタートアップ向けガイドパート 2: 要点

パート 1 では、初日から GenAIOps を採用することの利点を探り、AI を活用した製品を構築するスタートアップ企業向けに特別に設計されたアプリケーション中心のパイプラインの概要を説明しました。パート 2 では、プロトタイプから本番環境への準備が整ったソリューションに至るまで、必要不可欠なコンポーネントを実装するための実用的なガイダンスを提供します。
GenAIOps パイプライン: 要点
GenAIOps の導入を成功させる鍵は、強固な評価機能を備えた強固なベースラインを早期に確立することです。これにより、各イテレーションが前のイテレーションから学んだことを基に継続的な改善のフライホイールを構築できます。これにより、迅速な実験が可能になると同時に、大きな技術的負債を防ぐことができます。
無駄のない効果的な手法を使用して、GenAIOps パイプラインの各段階に不可欠なコンポーネントを実装する方法を探りましょう。各ステップに最適な AWS またはサードパーティのサービスの詳細については、付属のクイックリファレンスカードを参照してください。
データエンジニアリングと管理
軽量なデータパイプラインを確立して、AI アプリケーションを直接活用する重要なデータアーティファクトを管理します。ユースケースに基づいて、以下の主要なデータセットに焦点を当ててください。
モデル選択プロンプトデータセット:標準化された評価プロンプトデータセットは、公正なモデル比較に不可欠です。まず、業界標準のベンチマークデータセット (MMLU、GPQA、DROPなど。), Amazon Bedrock の組み込み評価データセット、または独自のカスタムドメイン固有データセットを構築することもできます。これらはモデル評価プレイブックの役割を果たします。新しいモデルがリリースされたときや、モデルの選択を再検討するときには、これらを再検討してください。
プロンプトエンジニアリングデータセット:これらのデータセットには、プロンプトテンプレートとグラウンドトゥルースデータセットが含まれます。Amazon Bedrock プロンプト管理 または Langfuse などのオープンソースの代替手段を使用して、プロンプトのバージョン管理、テスト、および管理を行う集中型のプロンプトカタログを実装します。さらに、プロンプトのテストと最適化のゴールドスタンダードとなる、人間が精選した 100 以上のクエリと応答のペアを作成してください。
検索拡張生成 (RAG) データセットの取得: まず、外部の知識ソースを準備することから始めます。ドキュメントのような 非構造化データ の場合、このプロセスには、Amazon Titan または Bedrock 上の Cohere のモデルを使用した取り込み、チャンク化、および ベクトル埋め込み の生成が含まれます。Amazon OpenSearch Serverless や Amazon S3 Vectors などのマネージドベクトルデータベースに埋め込みを保存します。表形式データなどの 構造化データ の場合、プロセスには前処理、スキーマ分析、メタデータの拡充、サポートされている構造化データストアへのロードが含まれます。どちらのデータタイプにおいても、シンプルかつ効果的なデータ更新メカニズムを実装し、知識源を最新の状態に保ちます。さらに、クエリ、コンテキスト、回答のトリプレットを含む RAG評価データセット を作成し、検索精度と応答品質をテストします。
モデルカスタマイズデータセット: まずは、最も価値のある所有データを収集することから始めます。所有データでは不十分な場合は、合成トレーニングの例を生成 できます。
クイックリファレンスカード: データエンジニアリングと管理の概要

役立つリソース:

開発と実験
開発の初期段階では、スタートアップはスピードとシンプルさを優先し、ローコード サービスによる迅速な実験に重点を置いて市場投入までの時間を短縮する必要があります。
モデルの選択: まず LMArena や Artificial Analysis などの公開ベンチマークから始めて、最初の候補リストを作成し、その後ユースケース固有の評価を通じて選択範囲を絞り込みます。Amazon Bedrock は、主要な基盤モデル (FM) ファミリーへのアクセスを提供します。候補モデルを評価するには、Amazon Bedrock Evaluations または Amazon SageMaker Clarify を活用してください。
プロンプトエンジニアリング: ビジネス目標に沿った明確な成功基準を定義し、それぞれについて測定可能な指標を作成します。選択したモデルの設計ガイドライン に従って初期プロンプトを作成し、グランドトゥルースデータセットを用いて体系的に評価します。Amazon Bedrock のプロンプト最適化 を活用して、モデル固有の改善を図りながら、ドラフト作成と改良を進めます。一貫した結果が得られるまで反復処理を行い、成功したプロンプトを適切なバージョニング管理の下でプロンプトカタログに公開します。
RAG: AWS の 完全に管理された RAG オプション を活用して、データストア、リトリーバー、FM、オーケストレーターの実装を効率化し、開発時間と運用オーバーヘッドを大幅に削減します。まず、RAG システムをサポートされているデータソースに接続し、その後、FM と統合して完全な拡張生成ワークフローを構築します。まずは特定の知識ドメインに絞り込み、有効性を検証してから、他のデータソースに拡張します。クエリの変更や再ランク付け といった高度な RAG 技術を活用して、回答の関連性を向上させます。
モデルのカスタマイズ: トレーニングデータセットを使用して、事前にトレーニングされた FM をカスタマイズ し、特定のユースケースにおけるパフォーマンスを向上させます。常にプロンプトエンジニアリングから始め、追加のコンテキストが必要な場合は RAG に移行します。以前のアプローチが要件を満たさない場合にのみ、モデルのカスタマイズを検討してください。まずは、1 つのドメインに絞ったデータセットを使用して改善点を検証し、その後拡張してください。
AI エージェント: 複雑なタスクを実行したり、さまざまな API やサービスとやり取りしたりできる AI 搭載アシスタントを作成します。Amazon Bedrock エージェント は、ユーザーの意図の理解、アクションの決定、API コールの実行、自然言語での結果の表示といった複雑なオーケストレーションを自動的に処理します。カスタマイズされた実装の場合は、Strands や LangGraph. などのオープンソースフレームワークの使用を検討してください。
アプリケーションの構築と実験: チームの専門知識と納品スケジュールの要件に基づいて、開発アプローチを選択してください。AWS はスタートアップに最適なサービスをいくつか提供しており (下記参照)、Amazon Q Developer は、AWS アプリケーションの理解、構築、拡張、運用を支援する AI 搭載アシスタントとして機能します。迅速なイテレーションを維持しながら体系的な改善を可能にする、構造化された実験アプローチを確立してください。仮説、実装の詳細、結果の指標を含む実験ログを維持し、実験が技術的な指標だけでなくビジネス指標にも結びついた明確な成功基準を持つようにしてください。
クイックリファレンスカード: 開発と実験の概要

役立つリソース:
- Amazon Bedrock のプロンプト管理とプロンプトフローによるプロンプトの大規模な評価
- コンセプトから現実へ: 概念実証から製造までの RAG の道のり
- Amazon Bedrock エージェントを使用して堅牢な生成 AI アプリケーションを構築するためのベストプラクティス
テストと評価
ステージ 1 で作成した評価データセットを使用して、無駄のない厳密なプロセスを確立して、アプリケーションが確実に動作し、正常に動作することを検証します。最も重要なユーザーワークフローに最初に焦点を当てて、徹底性とスタートアップスピードのバランスを取ってください。
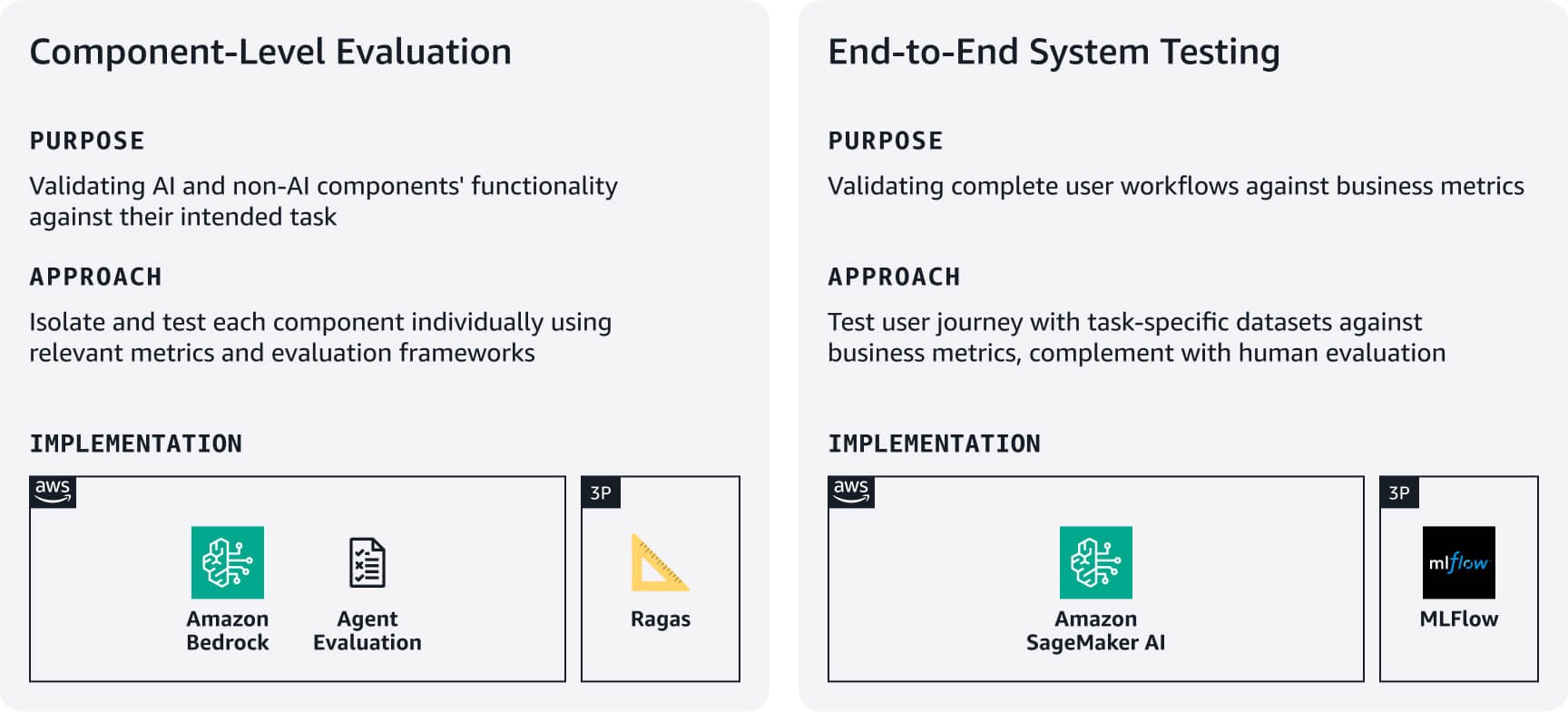
コンポーネントレベルの評価: AI コンポーネントと非 AI コンポーネントが意図したタスクをどの程度実行できるかを測定します。たとえば、RAG システムの場合、Amazon Bedrock の評価 または RAGAS などのフレームワークを使用して、検索精度 と 応答生成品質 を評価します。エージェントの場合は、エージェント評価 や LLM-as-a-judge アプローチ などのフレームワークを活用して、ユースケースの要件に基づいてタスク完了率や意思決定/ツールの使用精度などの指標を評価します。
エンドツーエンドのシステムテスト:タスク固有の評価データセットを使用して、完全なユーザーワークフローをテストします。コアタスクごとにビジネスに合った成功指標を定義し、コンポーネントがユーザージャーニー全体でシームレスに機能することを検証します。自動テストを、回答の質、関連性、ブランド・アライメントに関する人間による評価で補完します。こうした側面は、自動化指標では見落とされがちです。これらの評価結果を使用してベースラインを確立し、ユーザーからのフィードバックとビジネスへの影響に基づいて繰り返し改善します。システムバージョン間の実験を追跡するには、 SageMaker AI のマネージド MLflow を使用することを検討してください。
クイックリファレンスカード: テストと評価の概要
役立つリソース:
デプロイとサービス
技術要件とチームの能力に基づいた 最もシンプルなデプロイオプションから始めて、成長に合わせてアーキテクチャを進化させてください。AWS エコシステムでは、アーキテクチャを全面的に書き直すことなく、これらのデプロイパターン間の自然なアップグレードパスを提供します。
モデルのデプロイ: Amazon Bedrock から始めれば、統一された API を通じて FM にすぐにアクセスできます。Bedrock で利用できない特殊なモデルが必要な場合は、Amazon Bedrock Marketplace または Amazon SageMaker JumpStart を調べて、SageMaker AI で直接モデルを検出してデプロイしてください。
アプリケーションのホスティングと運用: AWS Amplify Hosting を使用して最新のウェブアプリケーションをデプロイします。AWS Lambda 関数を Amazon API Gateway と統合して 軽量のマイクロサービスを作成します。AWS App Runner をコンテナ化されたアプリケーションのデプロイのエントリーポイントとしてご利用ください。信頼性を確保するため、シンプルなフォールバックメカニズムを実装します。RAG の取得に失敗した場合はベースモデルのレスポンスにフォールバックし、プライマリモデルが利用できない場合はバックアップモデルに切り替え、Amazon MemoryDB を使用して一般的なクエリをキャッシュ します。また、依存するサービスにサーキットブレーカーを設定し、連鎖的な障害を防止します。これらのパターンは、ユーザーベースの拡大に合わせて、より洗練されたレジリエンス戦略の基盤となります。
ワークフローオーケストレーション: リクエストとレスポンスの分離を必要とする複雑な AI 操作の場合は、タスクキューイング用のAmazon SQS と、マルチステップワークフローのオーケストレーション用の AWS Step Functions を組み合わせます。このパターンは、バッチ処理や複数のモデル呼び出しを伴うワークフローなど、時間のかかる操作に特に役立ちます。
クイックリファレンスカード: デプロイとサービスの概要

役立つリソース:
オブザーバビリティと改良
複雑さを最小限に抑えながら、ビジネスへの影響を即座に引き起こす重要なオブザーバビリティに焦点を当てます。
主要メトリクスのモニタリング: ユースケースに該当する技術的なパフォーマンスメトリクスに焦点を当て、重要なしきい値に対しては CloudWatch アラーム を設定します。シンプルなフィードバックメカニズム (評価を上げる/下げる)、会話の完了率、機能の使用パターンを通じてユーザーエクスペリエンスを追跡します。これにより、技術指標が見落としている問題が明らかになり、ビジネスの成功に直接影響することがよくあります。
基本的なオブザーバビリティ設定: 基本的なモニタリングには、Bedrock や SageMaker AI などのサービスと Amazon CloudWatch のネイティブ統合 をご利用ください。複雑な RAG パターンの場合は、カスタム CloudWatch ダッシュボード の構築をご検討ください。さまざまなアプリケーションコンポーネント間の相互作用をキャプチャするには、Amazon X-Ray または Langfuse や LangSmith などの専用の LLM オブザーバビリティプラットフォームを使用して分散トレースを実装します。
コストトラッキング: AWS コスト配分タグ を使用して、機能、環境、または顧客セグメントごとに支出を追跡します。タグベースのフィルターを使用してAWS Budgets を設定すると、異常やしきい値違反に関するアラートを受信できます。
改良ワークフロー: 運用ダッシュボードとコスト内訳を毎週見直して、最適化の機会を特定します。インサイトを活用して、プロンプトの長さの調整、コストや遅延の影響を受けやすいワークロードのモデルの切り替え、使用パターンに基づく検索戦略の最適化など、即時の改善を推進してください。生産現場の観測を調整が必要な特定のパイプライン段階に結び付ける問題追跡システムを実装しましょう。問題のあるクエリと応答の収集を自動化し、今後のテストシナリオに通知します。
クイックリファレンスカード: オブザーバビリティと改良の概要

役立つリソース:
ガバナンスとメンテナンス
スタートアップ企業を保護すると同時に、迅速なイテレーションを可能にする、軽量なガバナンスプラクティスを確立しましょう。これにより、開発速度を落とすことなく、利害関係者の信頼を築くことができます。
責任ある AI と安全: 最初の防御線として Amazon Bedrock のガードレール を実装します。ヘイトスピーチ、暴力、その他不適切または主題から外れたコンテンツに対して、ユースケースに特化したコンテンツフィルターを設定します。これらのガードレールはBedrockモデルと外部モデルの両方で機能し、開発速度に影響を与えることなくリアルタイム保護を提供します。
バージョン管理と文書化: バージョニングが有効な Amazon S3 を使用して AI アーティファクトを体系的に追跡し、モデル、プロンプト、およびデータセットに明確な命名規則を実装します。透明性と将来のコンプライアンス要件に不可欠な、各 AI モデルの目的、データソース、制限、パフォーマンスメトリックを文書化した軽量の モデルカード を作成します。
セキュリティとコンプライアンス: 開発、テスト、本番環境用の個別のロールを持つ最小特権の原則に従ってAWS IAM ロール を構成します。API キーと機密性の高い設定には AWS Secrets Manager を使用します。AWS CloudTrail を有効にして自動監査ログを作成し、コンプライアンスの基盤を構築します。
インシデント対応: 一般的な障害 (モデルエラー、パフォーマンスの低下、コストの急上昇) に対応する簡単な手順書を作成します。明確なエスカレーションパスを確立し、重要なアーティファクトの基本的なバックアップ戦略を実装します。
クイックリファレンスカード: ガバナンスとメンテナンスの概要

まとめ
スタートアップの初期段階で GenAIOps を実装する場合、多額の投資や複雑なインフラストラクチャは必要ありません。パイプラインの各段階の重要な要素に焦点を当て、AWS マネージドサービスを活用することで、将来の成長を可能にする運用手法を確立しながら、迅速なイテレーションをサポートする基盤を構築できます。
この段階での目標は完璧ではなく、意図性であることを忘れないでください。つまり、現在の規模に適切でありながら、AI アプリケーション固有の課題を認識するシステムを作成することです。これらの重要事項から始めて、ユーザーにとって何が重要かを測定し、学んだことを文書化してください。
パート 3 では、増大する顧客の需要を満たすために事業を拡大し始める際に、これらのプラクティスをどのように進化させるかを紹介します。

Nima Seifi
Nima Seifi 氏は、南カリフォルニアに拠点を置く AWS のシニアソリューションアーキテクトで、SaaS と GenAIOps を専門としています。彼は AWS を基盤とするスタートアップの技術顧問を務めています。AWS に入社する前は、モバイルインターネット技術で 10 年間研究開発に携わった後、e コマース業界で DevOps アーキテクトとして 5 年以上働いていました。Nima は著名な技術雑誌や会議で 20 件以上の論文を発表し、7 件の米国特許を保有しています。仕事以外では、読書、ドキュメンタリー鑑賞、ビーチウォークなどを楽しんでいます。

Anu Jayanthi
Anu Jayanthi 氏はスタートアップの顧客と協力して、AWS ベストプラクティスを使用したソリューションの計画と構築に役立つ提案と戦略的技術ガイダンスを提供しています。
.jpg)
Pat Santora
Pat Santora 氏は、GenAI Labs のクラウドアーキテクト兼テクノロジストであり、企業とスタートアップの両方のクラウド全体でソリューションを実装してきた 25 年以上の経験があります。彼は、透明性と信頼を中心とした理念のもと、創業当初から数多くの製品の上市を成功させ、分析的再構築プロジェクトを主導し、リモートチームを管理してきました。彼の技術的専門知識は、戦略的計画、システム管理、アーキテクチャの再設計に及んでおり、GenAI、分析、ビッグデータへの関心によって補完されています。
.jpg)
Clement Perrot
Clement Perrot 氏は、モデルの選択、責任ある AI の実装、および最適化された機械学習運用に関する戦略的ガイダンスを提供することで、一流スタートアップが AI イニシアチブを加速できるよう支援しています。シリアルアントレプレナーであり、Inc 30 Under 30 の受賞者でもある彼は、コンシューマーテクノロジーとエンタープライズ AI の分野で複数のベンチャーを設立したり、成功裏に撤退したりした実績があり、AI 企業の構築と拡大に関する深い専門知識を持っています。
このコンテンツはいかがでしたか?