Como estava esse conteúdo?
- Aprenda
- Guia para startups sobre GenAIOps na AWS, parte 2: Noções básicas
Guia para startups sobre GenAIOps na AWS, parte 2: Noções básicas

Na Parte 1, exploramos as vantagens de adotar o GenAIOps desde o primeiro dia e descrevemos nosso pipeline centrado em aplicações, projetado especificamente para startups que desenvolvem produtos com tecnologia de IA. Agora, na Parte 2, fornecemos orientações práticas para implementar os componentes essenciais que levarão você do protótipo a soluções prontas para produção.
Pipeline de GenaiOps: os fundamentos
A chave para a implementação de sucesso do GenAIOps é estabelecer uma base sólida com recursos de avaliação robustos desde o início, criando um ciclo de melhoria contínua no qual cada iteração aproveita os aprendizados da anterior. Isso evita a dívida técnica significativa e possibilita experimentações rápidas.
Vamos explorar como implementar componentes essenciais para cada etapa do seu pipeline de GenAIOps, usando técnicas enxutas, mas eficazes. Mais informações sobre quais serviços da AWS ou de terceiros são mais adequados para cada etapa podem ser encontradas nos cartões de referência rápida que acompanham este documento.
Engenharia e gerenciamento de dados
Estabeleça um pipeline de dados leve para gerenciar artefatos de dados essenciais que alimentam diretamente sua aplicação de IA. Concentre-se nos seguintes conjuntos de dados importantes com base no seu caso de uso.
Conjuntos de dados de prompt de seleção de modelo: conjuntos de dados de prompts de avaliação padronizados são essenciais para uma comparação justa entre modelos. Comece com conjuntos de dados de benchmark padrão do setor (MMLU, GPQA, DROP, etc.), conjuntos de dados de avaliação integrados do Amazon Bedrock ou crie seus próprios conjuntos de dados personalizados específicos do domínio. Eles servem como seu manual de avaliação de modelos: consulte-os novamente quando novos modelos forem lançados ou quando reconsiderar sua escolha de modelo.
Conjuntos de dados de engenharia de prompts: esses conjuntos de dados incluem seus modelos de prompts e conjuntos de dados de referência. Utilize o Gerenciamento de Prompts do Amazon Bedrock ou uma alternativa de código aberto, como o Langfuse, para implementar um catálogo centralizado de prompts para versionamento, teste e gerenciamento de prompts. Além disso, crie mais de 100 pares de consultas e respostas selecionados por humanos, representando seu padrão ouro para testes e otimização de prompts.
Conjuntos de dados de geração aumentada via recuperação (RAG): comece preparando suas fontes de conhecimento externas: para dados não estruturados, como documentação, o processo envolve ingestão, fragmentação e geração de incorporações de vetores usando modelos do Amazon Titan ou Cohere no Bedrock. Armazene as incorporações em bancos de dados de vetores gerenciados, como o Amazon OpenSearch Sem Servidor ou o Amazon S3 Vectors; para dados estruturados, como dados tabulares, o processo inclui pré-processamento, análise de esquema, enriquecimento de metadados e carregamento em armazenamentos de dados estruturados compatíveis. Para ambos os tipos de dados, implemente mecanismos de atualização de dados simples, mas eficazes, para manter suas fontes de conhecimento atualizadas. Além disso, crie conjuntos de dados de avaliação RAG com tripletos de consulta-contexto-resposta para testar a precisão da recuperação e a qualidade da resposta.
Conjuntos de dados de personalização de modelos: comece coletando seus dados proprietários mais valiosos. Gere exemplos de treinamento sintéticos quando os dados proprietários forem insuficientes.
Cartões de referência rápida: engenharia e gerenciamento de dados num piscar de olhos

Recursos úteis:
- Gerar dados sintéticos para avaliar sistemas RAG usando o Amazon Bedrock
- Uma introdução à preparação do seu próprio conjunto de dados para o treinamento de LLMs

Desenvolvimento e experimentação
Durante o desenvolvimento inicial, as startups devem priorizar a velocidade e a simplicidade, concentrando-se na rápida experimentação por meio de serviços low code para acelerar o tempo de lançamento no mercado.
Seleção de modelos: comece com benchmarks públicos, como o LMArena ou o Artificial Analysis, para criar uma lista inicial de candidatos, e depois reduza a seleção usando uma avaliação específica para cada caso de uso. O Amazon Bedrock fornece acesso às principais famílias de modelos de base (FM). Para avaliar os modelos selecionados, utilize Avaliações do Amazon Bedrock ou o Amazon SageMaker Clarify.
Engenharia de prompts: defina critérios de sucesso claros alinhados com as metas de negócios e crie métricas mensuráveis para cada um deles. Elabore prompts iniciais seguindo as diretrizes de design para os modelos escolhidos e, em seguida, avalie-os sistematicamente em relação ao seu conjunto de dados de referência. Aproveite a otimização de prompts do Amazon Bedrock durante a elaboração e o refinamento para obter melhorias específicas do modelo. Repita até obter resultados consistentes e, em seguida, publique os prompts com êxito em seu catálogo de prompts com o versionamento adequado.
RAG: aproveite as opções de RAG totalmente gerenciadas na AWS para otimizar a implementação de datastores, recuperadores, FMs e orquestradores, reduzindo significativamente o tempo de desenvolvimento e a sobrecarga operacional. Comece conectando seu sistema RAG a fontes de dados compatíveis e, em seguida, integre-o a um FM para criar o fluxo de trabalho completo de geração aumentada. Comece com um domínio de conhecimento específico para validar a eficácia antes de expandir para fontes de dados adicionais. Aproveite técnicas avançadas de RAG, como modificação de consulta e reclassificação, para melhorar a relevância das respostas.
Personalização do modelo: use conjuntos de dados de treinamento para personalizar FMs pré-treinados a fim de melhorar a performance em casos de uso específicos. Sempre comece com a engenharia de prompts e, em seguida, passe para a RAG se for necessário contexto adicional. Só busque a personalização do modelo se as abordagens anteriores não atenderem aos seus requisitos, começando com um conjunto de dados focado em um domínio para validar as melhorias antes de expandir.
Agentes de IA: crie assistentes com tecnologia de IA capazes de realizar tarefas complexas e interagir com várias APIs e serviços. O Amazon Bedrock Agents lida automaticamente com a complexa orquestração de compreender a intenção do usuário, determinar ações, fazer chamadas de API e apresentar resultados em linguagem natural. Para uma implementação personalizada, considere usar frameworks de código aberto, como o Strands ou o LangGraph.
Compilação e experimentação de aplicações: escolha sua abordagem de desenvolvimento com base na experiência da sua equipe e nos requisitos de prazo de entrega. A AWS oferece vários serviços adequados para startups (veja abaixo), e o Amazon Q Developer funciona como um assistente com tecnologia de IA que ajuda você a entender, compilar, ampliar e operar aplicações da AWS. Estabeleça abordagens de experimentação estruturadas que possibilitem melhorias sistemáticas, mantendo a iteração rápida. Mantenha um log de experimentos com hipóteses, detalhes de implementação e métricas de resultados, garantindo que os experimentos tenham critérios de sucesso claros vinculados a métricas de negócios, em vez de apenas métricas técnicas.
Cartões de referência rápida: desenvolvimento e experimentação num piscar de olhos

Recursos úteis:
- Avaliar prompts em grande escala com o Gerenciamento de Prompts e Fluxos de Prompts para o Amazon Bedrock
- Do conceito à realidade: como navegar pela jornada rumo à RAG, desde a prova de conceito até a produção
- Práticas recomendadas para o desenvolvimento de aplicações robustas de IA generativa com os Amazon Bedrock Agents
Testes e avaliação
Estabeleça processos enxutos, porém rigorosos, para verificar se sua aplicação funciona de maneira confiável e tem uma boa performance, utilizando os conjuntos de dados de avaliação criados na etapa 1. Equilibre o rigor com a velocidade de inicialização, concentrando-se primeiro nos fluxos de trabalho mais críticos para os usuários.
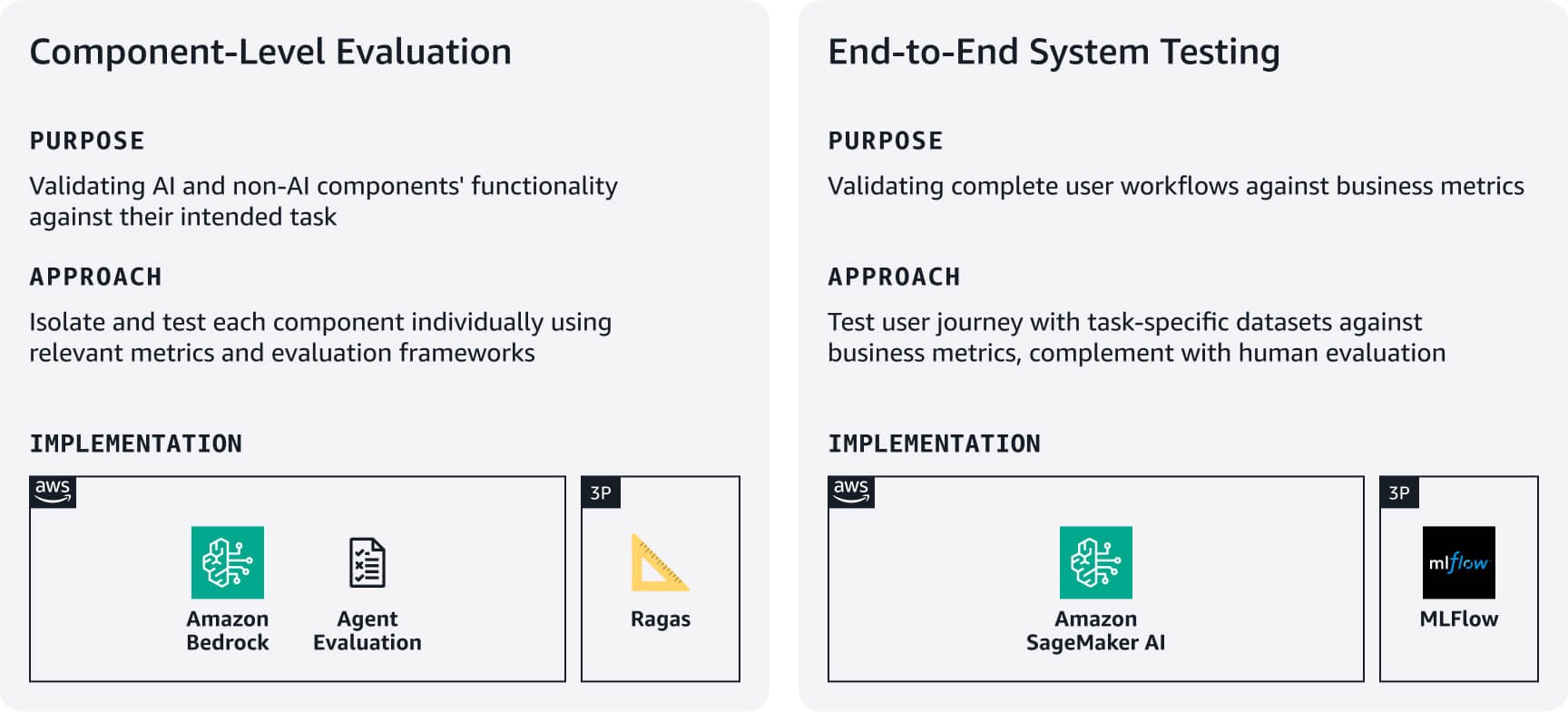
Avaliação no nível dos componentes: avalie a performance dos componentes de IA e de não IA nas tarefas pretendidas. Por exemplo, para sistemas RAG, use as Avaliações do Amazon Bedrock ou frameworks como o RAGAS para avaliar a precisão da recuperação e a qualidade da geração de respostas. Para agentes, aproveite as frameworks como o Avaliações do agente ou a abordagem de LLM como avaliador a fim de avaliar métricas como taxas de conclusão de tarefas e precisão na tomada de decisões/uso de ferramentas com base nos requisitos do seu caso de uso.
Testes completos do sistema: Teste fluxos de trabalho completos do usuário de acordo com conjuntos de dados de avaliação específicos para cada tarefa. Defina métricas de sucesso alinhadas aos negócios para cada tarefa principal e, em seguida, valide se os componentes funcionam perfeitamente em todas as jornadas do usuário. Complemente os testes automatizados com avaliações humanas da qualidade da resposta, relevância e alinhamento com a marca — aspectos que as métricas automatizadas muitas vezes deixam passar. Utilize esses resultados de avaliação para estabelecer linhas de base e, em seguida, melhore iterativamente com base no feedback do usuário e no impacto nos negócios. Considere usar o MLFlow gerenciado no SageMaker AI para acompanhar experimentos em diferentes versões do sistema.
Cartões de referência rápida: testes e avaliação num piscar de olhos
Recursos úteis:
- Avalie as respostas da RAG com o Amazon Bedrock, o LlamaIndex e o RAGAS
- Avaliação da workload da IA generativa
Implantação e serviço
Comece com a opção de implantação mais simples com base nos seus requisitos técnicos e nas capacidades da sua equipe e, em seguida, evolua sua arquitetura à medida que você cresce. O ecossistema da AWS oferece caminhos de upgrade naturais entre esses padrões de implantação, sem exigir reescritas completas da arquitetura.
Implantação do modelo: comece com o Amazon Bedrock para obter acesso imediato a FMs por meio de uma API unificada. Se você precisar de modelos especializados não disponíveis no Bedrock, explore o Amazon Bedrock Marketplace ou o Amazon SageMaker JumpStart para descobrir e implantar seu modelo diretamente no SageMaker AI.
Hospedagem e operação de aplicações: implante aplicações Web modernas utilizando o AWS Amplify Hosting. Crie microsserviços leves integrando funções do AWS Lambda com o Amazon API Gateway. Use o AWS App Runner como ponto de entrada para a implantação de aplicações em contêineres. Para garantir a confiabilidade, implemente mecanismos de fallback simples: recorra às respostas do modelo básico quando a recuperação da RAG falhar, mude para modelos de backup quando os modelos principais estiverem indisponíveis e armazene consultas comuns de cache usando o Amazon MemoryDB. Estabeleça disjuntores para serviços dependentes para evitar falhas em cascata. Esses padrões formam a base para estratégias de resiliência mais sofisticadas à medida que sua base de usuários cresce.
Orquestração de fluxo de trabalho: para operações complexas de IA que exigem a separação entre solicitação e resposta, combine o Amazon SQS para enfileiramento de tarefas com o AWS Step Functions para orquestrar fluxos de trabalho com várias etapas. Esse padrão é especialmente valioso para operações demoradas, como processamento em lote ou fluxos de trabalho que envolvem vários chamadas de modelo.
Cartões de referência rápida: implantação e atendimento num piscar de olhos

Recursos úteis:
Observabilidade e refinamento
Concentre-se na observabilidade essencial que gera impacto imediato nos negócios, minimizando a complexidade.
Monitoramento de métricas importantes: concentre-se nas métricas de performance técnica aplicáveis ao seu caso de uso e configure alarmes do CloudWatch para limites críticos. Acompanhe a experiência dos usuários por meio de mecanismos simples de feedback (curtir/não curtir), taxas de conclusão de conversas e padrões de utilização de recursos. Isso geralmente revela problemas que as métricas técnicas não detectam e que afetam diretamente o sucesso dos negócios.
Configuração essencial da observabilidade: utilize a integração nativa do Amazon CloudWatch com serviços como o Bedrock e o SageMaker AI para monitoramento básico. Para padrões de RAG complexos, considere a criação de painéis personalizados do CloudWatch. Para capturar a interação entre vários componentes das aplicações, implemente o rastreamento distribuído usando o Amazon X-Ray ou plataformas especializadas de observabilidade de LLM, como o Langfuse ou o LangSmith.
Acompanhamento dos custos: use etiquetas de alocação de custos da AWS para acompanhar os gastos por recurso, ambiente ou segmento de clientes. Configure o AWS Budgets com filtros baseados em etiquetas para receber alertas sobre anomalias ou violações de limites.
Fluxo de trabalho de refinamento: estabeleça revisões semanais dos painéis operacionais e das análises de custos para identificar oportunidades de otimização. Utilize insights para promover melhorias imediatas, como ajustar a duração dos prompts, trocar modelos para workloads sensíveis a custos ou latência ou otimizar estratégias de recuperação com base nos padrões de uso. Implemente um sistema de rastreamento de problemas que vincule as observações de produção a etapas específicas do pipeline que exijam ajustes. Automatize a coleta de consultas e respostas problemáticas para informar cenários de testes futuros.
Cartões de referência rápida: observabilidade e refinamento num piscar de olhos

Recursos úteis:
- Acompanhe, aloque e gerencie seus custos e uso da IA generativa com o Amazon Bedrock
- Usar o CloudWatch Logs Insights para identificar oportunidades de melhoria
Governança e manutenção
Estabeleça práticas de governança leves que protejam sua startup e possibilitem iterações rápidas. Isso ajuda a construir a confiança das partes interessadas sem diminuir a velocidade do desenvolvimento.
IA responsável e segurança: implemente as Barreiras de proteção do Amazon Bedrock como sua primeira linha de defesa. Configure filtros de conteúdo para discurso de ódio, violência e tópicos não relacionados ao seu caso de uso. Essas barreiras de proteção funcionam em modelos do Bedrock e modelos externos, fornecendo proteção em tempo real sem afetar a velocidade de desenvolvimento.
Controle de versão e documentação: acompanhe os artefatos de IA sistematicamente usando o Amazon S3 com versionamento habilitado e implemente convenções de nomenclatura claras para modelos, prompts e conjuntos de dados. Crie cartões de modelo leves que documentem a finalidade, as fontes de dados, as limitações e as métricas de performance de cada modelo de IA, o que é essencial para a transparência e os requisitos de conformidade futuros.
Segurança e conformidade: configure perfis do AWS IAM seguindo os princípios de privilégios mínimos, com perfis separados para desenvolvimento, teste e produção. Use o AWS Secrets Manager para chaves de API e configurações confidenciais. Habilite o AWS CloudTrail para registro em log automático de auditoria, criando bases essenciais de conformidade.
Resposta a incidentes: Desenvolva manuais simples para falhas comuns: erros de modelo, degradação de performance ou picos de custo. Estabeleça caminhos de escalonamento claros e implemente estratégias básicas de backup para artefatos críticos.
Cartões de referência rápida: governança e manutenção num piscar de olhos

Conclusão
A implementação do GenAIOps nos estágios iniciais da startup não requer investimentos vultosos nem infraestrutura complexa. Ao se concentrar nos elementos essenciais de cada estágio do pipeline e aproveitar os serviços gerenciados da AWS, você pode construir uma base que suporta iterações rápidas e, ao mesmo tempo, estabelecer práticas operacionais que possibilitarão o crescimento futuro.
Lembre-se de que o objetivo nesta fase não é a perfeição, mas a intencionalidade — criar sistemas que reconheçam os desafios únicos das aplicações de IA, mantendo-se adequados à sua escala atual. Comece com estes elementos essenciais, avalie o que é importante para os seus usuários e documente o que aprendeu.
Na Parte 3, mostraremos como evoluir essas práticas à medida que você começa a escalar suas operações para atender à crescente demanda dos clientes.

Nima Seifi
Nima Seifi é arquiteto de soluções sênior na AWS, com escritório no sul da Califórnia, onde é especialista em SaaS e GenAIOps. Ele atua como consultor técnico para startups que utilizam a AWS. Antes da AWS, trabalhou como arquiteto de DevOps no setor de comércio eletrônico por mais de cinco anos, após uma década de trabalho em pesquisa e desenvolvimento em tecnologias de internet móvel. Nima possui mais de 20 publicações em revistas técnicas e conferências de renome e detém sete patentes nos Estados Unidos. Fora do trabalho, ele aprecia ler, assistir documentários e caminhar pela praia.

Anu Jayanthi
Anu Jayanthi trabalha com clientes de Startups, fornecendo apoio e orientação técnica estratégica para ajudar a planejar e construir soluções utilizando práticas recomendadas da AWS.
.jpg)
Pat Santora
Pat Santora é arquiteto de nuvem e tecnólogo da GenAI Labs, com mais de 25 anos de experiência na implementação de soluções em nuvem para empresas e startups. Ele lançou com êxito vários produtos desde o início, liderou projetos de reestruturação analítica e gerenciou equipes remotas com uma filosofia centrada na transparência e na confiança. Sua experiência técnica abrange planejamento estratégico, gerenciamento de sistemas e redesenho arquitetônico, complementada por interesses em IA generativa, analytics e Big Data.
.jpg)
Clement Perrot
Clement Perrot auxilia startups de primeira linha a acelerar suas iniciativas de IA, fornecendo orientação estratégica sobre seleção de modelos, implementação responsável de IA e operações otimizadas de machine learning. Empreendedor em série e premiado pela Inc 30 Under 30, ele traz profunda experiência na construção e escalabilidade de empresas de IA, tendo fundado e encerrado com êxito vários empreendimentos em tecnologia de consumo e IA empresarial.
Como estava esse conteúdo?