Come ti è sembrato il contenuto?
- Scopri
- Guida per le startup a GenAIOps su AWS Parte 2: Gli elementi di base
Guida per le startup a GenAIOps su AWS Parte 2: Gli elementi di base

Nella Parte 1, abbiamo esplorato i vantaggi dell'adozione di GenAIOps sin dal primo giorno e abbiamo delineato la nostra pipeline incentrata sulle applicazioni progettata specificamente per le startup che creano prodotti basati sull'intelligenza artificiale. Ora, nella Parte 2, forniamo una guida pratica per l'implementazione dei componenti essenziali che vi porteranno dal prototipo alle soluzioni pronte per la produzione.
Pipeline GenAIOps: gli elementi di base
La chiave per un'implementazione di successo di GenAIOps è stabilire una solida base di partenza con solide capacità di valutazione fin da subito, creando un volano di miglioramento continuo in cui ogni iterazione si basa sugli insegnamenti tratti dalla precedente. Ciò previene un debito tecnico significativo e consente una rapida sperimentazione.
Esploriamo come implementare i componenti essenziali per ogni fase della pipeline GenAIOps utilizzando tecniche snelle ma efficaci. Ulteriori informazioni su quali servizi AWS o di terze parti siano più adatti per ogni fase sono disponibili nelle schede di riferimento rapido allegate.
Ingegneria e gestione dei dati
Crea una pipeline di dati leggera per gestire gli artefatti di dati essenziali che alimentano direttamente la tua applicazione di intelligenza artificiale. Concentrati sui seguenti set di dati chiave in base al tuo caso d'uso.
Set di dati relativi ai prompt di selezione del modello: i set di dati dei prompt di valutazione standardizzati sono fondamentali per un confronto equo dei modelli. Inizia con set di dati di benchmarking standard del settore (MMLU, GPQA, DROP, ecc.), set di dati di valutazione integrati in Amazon Bedrock, oppure crea set di dati personalizzati specifici per il dominio. Questi rappresentano il tuo manuale di valutazione del modello: rivisitali quando vengono rilasciati nuovi modelli o quando riconsideri la tua scelta del modello.
Set di dati di progettazione dei prompt: questi set di dati includono i modelli di prompt e i set di dati di base. Usa Gestione prompt di Amazon Bedrock o un'alternativa open source come Langfuse per implementare un catalogo di prompt centralizzato per la versione, il test e la gestione dei prompt. inoltre, crea oltre 100 coppie query-risposta curate da esseri umani che rappresentano il tuo gold standard per test e ottimizzazione rapidi.
Set di dati di generazione potenziata da recupero dati (RAG): inizia preparando le tue fonti di conoscenza esterne per dati non strutturati come la documentazione, il processo prevede l'importazione, la suddivisione in blocchi e la generazione di embedding vettoriali utilizzando modelli di Amazon Titan o Cohere su Bedrock. Archivia gli embedding in database vettoriali gestiti come Amazon OpenSearch serverless o Amazon S3 Vectors per dati strutturati come i dati tabulari, il processo include la pre-elaborazione, l'analisi degli schemi, arricchimento dei metadati e caricamento negli archivi di dati strutturati supportati. Per entrambi i tipi di dati, implementa meccanismi di aggiornamento dei dati semplici ma efficaci per mantenere aggiornate le tue fonti di conoscenza. Inoltre, crea set di dati di valutazione RAG con triplette query-context-answer per testare l'accuratezza del recupero e la qualità delle risposte.
Set di dati per la personalizzazione dei modelli: inizia raccogliendo i tuoi dati proprietari più preziosi. Genera esempi di addestramento sintetico quando i dati proprietari sono insufficienti.
Schede di riferimento rapide: ingegneria e gestione dei dati a colpo d'occhio

Risorse utili:
- Genera dati sintetici per valutare i sistemi RAG utilizzando Amazon Bedrock
- Un'introduzione alla preparazione del proprio set di dati per l'addestramento di LLM

Sviluppo e sperimentazione
Durante le prime fasi di sviluppo, le startup dovrebbero dare priorità alla velocità e alla semplicità, concentrandosi sulla sperimentazione rapida tramite servizi low code per accelerare il time-to-market.
Selezione del modello: inizia con benchmark pubblici come LMArena o Artificial Analysis per creare una rosa iniziale, quindi restringi la selezione attraverso una valutazione specifica del caso d'uso. Amazon Bedrock fornisce l'accesso alle principali famiglie di modelli di fondazione (FM). Per valutare i modelli selezionati, utilizza Amazon Bedrock Evaluations o Amazon SageMaker Clarify.
Progettazione dei prompt: definisci criteri di successo chiari in linea con gli obiettivi aziendali e crea parametri misurabili per ciascuno. Redigi i prompt iniziali seguendo le linee guida di progettazione per i modelli scelti, quindi valutali sistematicamente rispetto al set di dati di base. Sfrutta l'ottimizzazione dei prompt di Amazon Bedrock durante la stesura e il perfezionamento per miglioramenti specifici del modello. Ripeti l'iterazione fino a ottenere risultati coerenti, quindi pubblica i prompt corretti nel tuo catalogo di prompt con il corretto controllo delle versioni.
RAG: sfrutta le opzioni RAG completamente gestite su AWS per semplificare l'implementazione di archivi dati, strumenti di recupero, modelli di fondazione e orchestratori, riducendo significativamente i tempi di sviluppo e il sovraccarico operativo. Inizia connettendo il tuo sistema RAG alle fonti di dati supportate, quindi integralo con un FM per creare il flusso di lavoro completo di generazione aumentata. Inizia con un dominio di conoscenza mirato per convalidare l'efficacia prima di estenderlo a origini dati aggiuntive. Sfrutta tecniche RAG avanzate come la modifica delle query e il riposizionamento per migliorare la pertinenza delle risposte.
Personalizzazione del modello: utilizza i set di dati di addestramento per personalizzare i modelli di fondazione pre-addestrati per migliorare le prestazioni in casi d'uso specifici. Inizia sempre con una progettazione dei prompt, quindi passa a RAG se è necessario un contesto aggiuntivo. Persegui la personalizzazione del modello solo se gli approcci precedenti non soddisfano i tuoi requisiti, iniziando con un set di dati mirato proveniente da un dominio per convalidare i miglioramenti prima di espanderlo.
Agenti IA: crea assistenti basati sull'intelligenza artificiale in grado di eseguire attività complesse e interagire con varie API e servizi. Gli agenti Amazon Bedrock gestiscono automaticamente un'orchestrazione complessa per comprendere le intenzioni dell'utente, determinare le azioni, effettuare chiamate API e presentare i risultati in linguaggio naturale. Per un'implementazione personalizzata, valuta l'utilizzo di framework open source come Strands o LangGraph.
Creazione e sperimentazione di applicazioni: scegli il tuo approccio di sviluppo in base alle competenze del tuo team e ai requisiti di tempistica di consegna. AWS offre diversi servizi adatti alle startup (vedi sotto) e Amazon Q Developer funge da assistente basato sull'intelligenza artificiale per comprendere, creare, estendere e gestire le applicazioni AWS. Stabilisci approcci di sperimentazione strutturati che consentano un miglioramento sistematico pur mantenendo una rapida iterazione. Mantieni un registro degli esperimenti con ipotesi, dettagli di implementazione e metriche dei risultati, assicurandoti che gli esperimenti abbiano chiari criteri di successo legati a parametri aziendali piuttosto che solo a parametri tecnici.
Schede di riferimento rapido: sviluppo e sperimentazione a colpo d'occhio

Risorse utili:
- Valutazione dei prompt su larga scala con la gestione dei prompt e i flussi di prompt per Amazon Bedrock
- Dall'idea alla realtà: il viaggio di RAG dal proof of concept alla produzione
- Best practice per la creazione di applicazioni di IA generativa affidabili con agenti Amazon Bedrock
Test e valutazione
Stabilisci processi snelli ma rigorosi per verificare che la tua applicazione funzioni in modo affidabile e funzioni bene, utilizzando i set di dati di valutazione creati nella fase 1. Bilancia la completezza con la velocità di avvio concentrandoti innanzitutto sui flussi di lavoro più critici per gli utenti.
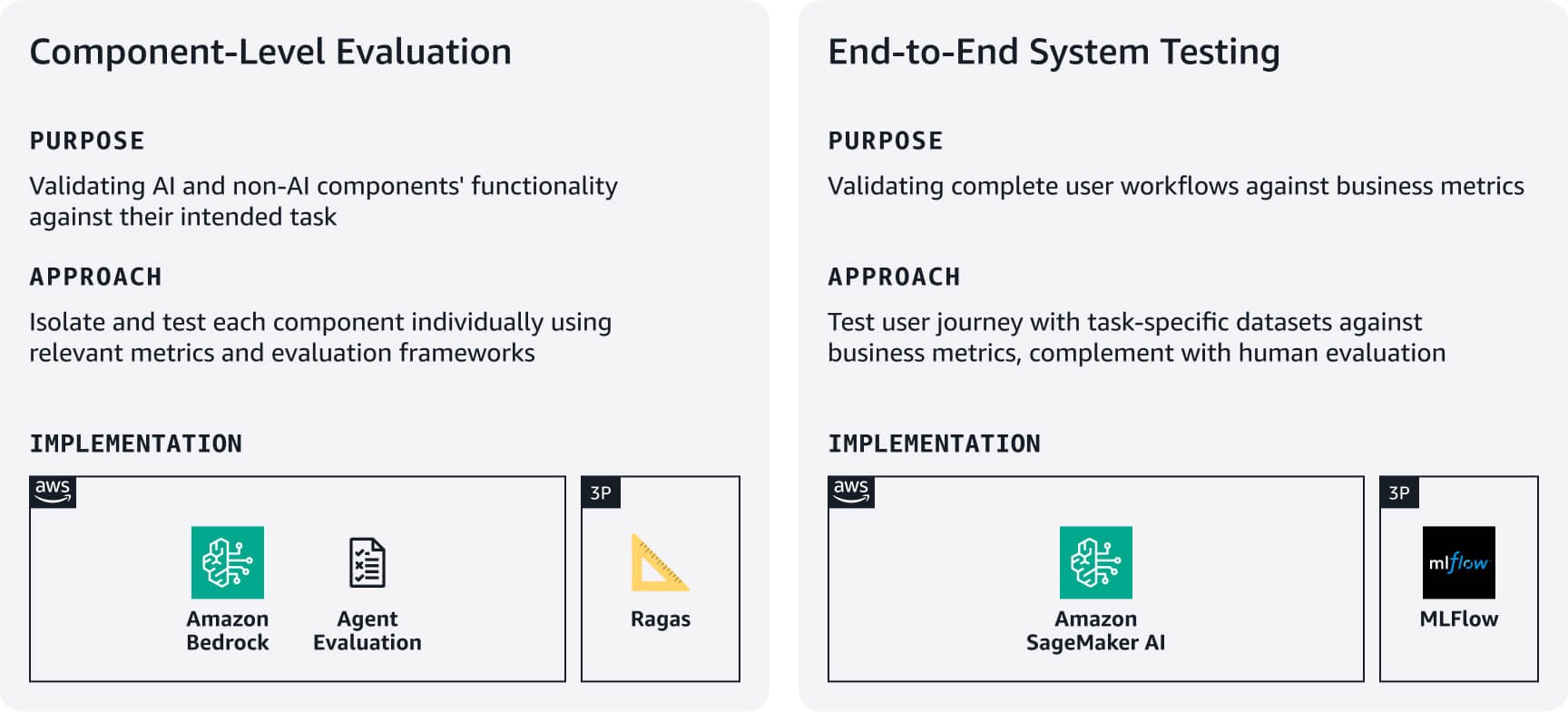
Valutazione a livello di componente: misura come i componenti IA e non IA eseguono le attività previste. Ad esempio, per i sistemi RAG utilizza Amazon Bedrock Evaluations o framework come RAGAS per valutare l'accuratezza del recupero e la qualità della generazione delle risposte. Per gli agenti, utilizza framework come Agent Evaluation o un approccio LLM-as-a-judge per valutare parametri come i tassi di completamento delle attività e l'accuratezza delle decisioni e degli strumenti in base ai requisiti del caso d'uso.
Test di sistema end-to-end: testa i flussi di lavoro completi degli utenti utilizzando set di dati di valutazione specifici per le attività. Definisci parametri di successo allineate all'azienda per ogni attività principale, quindi verifica che i componenti funzionino perfettamente durante i percorsi degli utenti. Completa i test automatici con una valutazione umana della qualità delle risposte, della pertinenza e dell'allineamento del marchio: aspetti che le metriche automatiche spesso non tengono conto. Usa questi risultati di valutazione per stabilire le linee di base, quindi migliora in modo iterativo in base al feedback degli utenti e all'impatto sul business. Prendi in considerazione l'utilizzo di MLFlow gestito su SageMaker AI per tenere traccia degli esperimenti tra le versioni del sistema.
Schede di riferimento rapido: test e valutazione a colpo d'occhio
Risorse utili:
- Valuta le risposte RAG con Amazon Bedrock, LlamaIndex e RAGAS
- Valutazione del carico di lavoro dell'IA generativa
Implementazione e servizio
Inizia con l'opzione di implementazione più semplice in base ai requisiti tecnici e alle capacità del team, quindi evolvi la tua architettura man mano che cresci. L'ecosistema AWS fornisce percorsi di aggiornamento naturali tra questi modelli di distribuzione senza richiedere riscritture architettoniche complete.
Implementazione del modello: inizia con Amazon Bedrock per accedere immediatamente ai modelli di fondazione tramite un'API unificata. Se hai bisogno di modelli specializzati non disponibili in Bedrock, esplora Marketplace Amazon Bedrock o Amazon SageMaker JumpStart per scoprire e distribuire il tuo modello direttamente su SageMaker AI.
Hosting e funzionamento delle applicazioni: implementa applicazioni Web moderne utilizzando l'hosting AWS Amplify. Crea microservizi leggeri integrando le funzioni AWS Lambda con Gateway Amazon API. Usa AWS App Runner come punto di partenza per la distribuzione di applicazioni containerizzate. Per garantire l'affidabilità, implementa semplici meccanismi di riserva: torna alle risposte del modello base quando il recupero RAG fallisce, passa ai modelli di backup quando i modelli primari non sono disponibili e memorizza nella cache le query comuni utilizzando Amazon MemoryDB. Stabilisci interruttori automatici per i servizi dipendenti per prevenire guasti a cascata. Questi modelli costituiscono la base per strategie di resilienza più sofisticate man mano che la base di utenti cresce.
Orchestrazione del flusso di lavoro: per operazioni di intelligenza artificiale complesse che richiedono il disaccoppiamento richiesta/risposta, combina Amazon SQS per l'accodamento delle attività con AWS Step Functions per orchestrare flussi di lavoro in più fasi. Questo modello è particolarmente utile per operazioni che richiedono molto tempo come l'elaborazione in batch o i flussi di lavoro che coinvolgono più chiamate al modello.
Schede di riferimento rapido: implementazione e gestione a colpo d'occhio

Risorse utili:
Osservabilità e perfezionamento
Concentrati sull'osservabilità essenziale che determina un impatto aziendale immediato riducendo al minimo la complessità.
Monitoraggio dei parametri chiave: concentrati sui parametri tecnici delle prestazioni applicabili al tuo caso d'uso e configura gli allarmi CloudWatch per le soglie critiche. Tieni traccia dell'esperienza utente attraverso semplici meccanismi di feedback (pollice su/giù), tassi di completamento delle conversazioni e modelli di utilizzo delle funzionalità. Questi spesso rivelano problemi che i parametri tecnici trascurano e influiscono direttamente sul successo aziendale.
Configurazione essenziale dell'osservabilità: utilizza l'integrazione nativa di Amazon CloudWatch con servizi come Bedrock e SageMaker AI per il monitoraggio fondamentale. Per modelli RAG complessi, valuta la possibilità di creare pannelli di controllo CloudWatch personalizzati. Per catturare l'interazione tra i vari componenti dell'applicazione, implementa il tracciamento distribuito utilizzando Amazon X-Ray o piattaforme di osservabilità LLM specializzate come Langfuse o LangSmith.
Monitoraggio dei costi: utilizza i tag di allocazione dei costi di AWS per tenere traccia della spesa per funzionalità, ambiente o segmento di clienti. Configura AWS Budgets con filtri basati su tag per ricevere avvisi in caso di anomalie o violazioni delle soglie.
Perfezionamento del flusso di lavoro: stabilisci revisioni settimanali dei pannelli di controllo operativi e delle suddivisioni dei costi per identificare le opportunità di ottimizzazione. Usa le informazioni per apportare miglioramenti immediati, ad esempio regolando la durata dei prompt, cambiando modello per carichi di lavoro sensibili ai costi o alla latenza o ottimizzando le strategie di recupero in base ai modelli di utilizzo. Implementa un sistema di tracciamento dei problemi che colleghi le osservazioni sulla produzione a fasi specifiche della pipeline che richiedono modifiche. Automatizza la raccolta di domande e risposte problematiche per orientare gli scenari di test futuri.
Schede di riferimento rapido: osservabilità e perfezionamento a colpo d'occhio

Risorse utili:
- Monitora, alloca e gestisci i costi e l'utilizzo dell'IA generativa con Amazon Bedrock
- Utilizzo di CloudWatch Logs Insights per identificare le opportunità di miglioramento
Governance e manutenzione
Stabilisci pratiche di governance leggere che proteggano la tua startup consentendo al contempo una rapida iterazione. Questo aiuta a creare la fiducia degli stakeholder senza rallentare la velocità di sviluppo.
IA responsabile e sicurezza: implementa guardrail Amazon Bedrock come prima linea di difesa. Configura filtri di contenuto per incitamento all'odio, violenza e altri contenuti inappropriati o fuori tema specifici per il tuo caso d'uso. Questi guardrail funzionano su modelli Bedrock e modelli esterni, fornendo protezione in tempo reale senza influire sulla velocità di sviluppo.
Controllo delle versioni e documentazione: tieni traccia degli artefatti IA in modo sistematico utilizzando Amazon S3 con il controllo delle versioni abilitato e implementa convenzioni di denominazione chiare per modelli, prompt e set di dati. Crea schede del modello che documentino lo scopo, le origini dati, le limitazioni e i parametri prestazionali di ogni modello di intelligenza artificiale, essenziali per la trasparenza e i futuri requisiti di conformità.
Sicurezza e conformità: configura ruoli di AWS IAM seguendo i principi del privilegio minimo con ruoli separati per lo sviluppo, il test e la produzione. Usa AWS Secrets Manager per chiavi API e configurazioni sensibili. Abilita AWS CloudTrail per la registrazione automatica degli audit, creando le basi essenziali per la conformità.
Risposta agli incidenti: sviluppa semplici runbook per i guasti più comuni: errori del modello, riduzione delle prestazioni o picchi dei costi. Stabilisci percorsi di escalation chiari e implementa strategie di backup di base per gli artefatti critici.
Schede di riferimento rapido: governance e manutenzione a colpo d'occhio

Conclusioni
L'implementazione di GenAIOps nelle fasi iniziali delle startup non richiede ingenti investimenti o infrastrutture complesse. Concentrandoti sugli elementi essenziali di ogni fase della pipeline e sfruttando i servizi gestiti di AWS, puoi creare una base che supporti l'iterazione rapida stabilendo al contempo le pratiche operative che consentiranno la crescita futura.
Ricorda che l'obiettivo in questa fase non è la perfezione ma l'intenzionalità: creare sistemi che riconoscano le sfide uniche delle applicazioni di intelligenza artificiale pur rimanendo adeguati alla tua scala attuale. Inizia con questi elementi essenziali, misura ciò che conta per i tuoi utenti e documenta le tue conoscenze.
Nella Parte 3, ti mostreremo come completare queste procedure man mano che inizi a scalare le tue operazioni per soddisfare la crescente domanda dei clienti.

Nima Seifi
Nima Seifi è Senior Solutions Architect presso AWS, nella sede della California del sud, ed è specializzato in SaaS e GenaiOps. È consulente tecnico per le startup che sviluppano su AWS. Prima di entrare in AWS, ha lavorato come architetto DevOps nel settore dell'e-commerce per più di 5 anni, dopo un decennio di attività di ricerca e sviluppo nelle tecnologie Internet mobili. Nima ha effettuato più di 20 pubblicazioni su importanti riviste e conferenze tecniche, e detiene 7 brevetti statunitensi. Al di fuori del lavoro, ama leggere, guardare documentari e fare passeggiate sulla spiaggia.

Anu Jayanthi
Anu Jayanthi collabora con i clienti di startup, fornendo assistenza e supporto tecnico strategico per aiutare a pianificare e creare soluzioni utilizzando le best practice di AWS.
.jpg)
Pat Santora
Pat Santora è GenAI Labs Cloud Architect and Technologist con oltre 25 anni di esperienza nell'implementazione di soluzioni sul cloud per aziende e startup. Ha lanciato con successo numerosi prodotti sin dalla fase iniziale, ha guidato riprogettazioni analitiche e gestito team da remoto con una filosofia incentrata sulla trasparenza e sulla fiducia. La sua esperienza tecnica spazia dalla pianificazione strategica, alla gestione dei sistemi e al redesign architettonico, unitamente a interessi in GenAI, Analisi e Big Data.
.jpg)
Clement Perrot
Clement Perrot aiuta le startup di alto livello ad accelerare le loro iniziative di IA fornendo indicazioni strategiche sulla selezione dei modelli, sull'implementazione dell'IA responsabile e sulle operazioni di machine learning ottimizzate. Imprenditore seriale e vincitore di Inc 30 Under 30, vanta una profonda esperienza nella creazione e nella scalabilità delle aziende IA, avendo fondato ed essendo uscito con successo da diverse joint-venture nel campo della tecnologia di consumo e dell'IA per le aziende.
Come ti è sembrato il contenuto?