



什么是强化学习?
强化学习(RL)是一种机器学习(ML)技术,可以训练软件做出决策,以实现最佳结果。它模仿了人类为实现目标所采取的反复试验的学习过程。有助于实现目标的软件操作会得到加强,而偏离目标的操作将被忽略。
RL 算法在处理数据时使用奖惩模式。这些算法从每个操作的反馈中学习,并自行发现实现最终结果的最佳处理路径。此类算法还能够实现延迟满足。最好的整体策略可能需要短期的牺牲,因此其发现的最佳方法可能包括一些惩罚,或在过程中有一些迂回。RL 是一种强大的方法,可以帮助人工智能(AI)系统在看不见的环境中实现最佳结果。
强化学习有哪些好处?
使用强化学习(RL)有很多好处。但是,以下三方面往往是最突出的。
在复杂环境中表现出色
RL 算法可以在有许多规则和依赖关系的复杂环境中使用。在同一个环境中,即使对环境非常了解,人类可能也无法确定最佳路径。而无模型 RL 算法可以快速适应不断变化的环境,并找到新的策略来优化结果。
减少了对人类互动的要求
在传统的 ML 算法中,人类必须通过标记数据对来指导算法。而使用 RL 算法时,就无需手动标记了。这类算法可以自行学习。同时,这类算法还提供整合人类反馈的机制,允许系统根据人类偏好、专业知识和更正进行调试。
针对长期目标进行优化
RL 本质上侧重于长期奖励最大化,因此适用于行动可带来长期后果的场景。它特别适合每一步都无法立即获得反馈的现实情况,因为它可以从延迟的奖励中学习。
例如,有关能源消耗或存储的决策可能会产生长期后果。RL 可用于优化长期能源效率和成本。通过适当的架构,RL 代理还可以将学到的策略推广到相似但不相同的任务中。
强化学习的用例有哪些?
强化学习(RL)可以应用于各种真实用例。下面提供一些示例。
个性化营销
在推荐系统等应用场景中,RL 可以根据各个用户的互动情况量身为其推荐内容。这提高了体验的个性化程度。例如,某应用程序可能会根据某些人口统计信息向用户展示广告。该应用程序会通过每次广告互动,了解要向用户展示哪些广告,以改进产品销售情况。
优化难题
传统优化方法通过根据特定标准评估和比较可能的解决方案来解决问题。相比之下,RL 引入了从互动中学习的方式,以便随着时间的推移找到最佳或接近最佳的解决方案。
例如,云支出优化系统使用 RL 来适应不断变化的资源需求,并选择最佳实例类型、数量和配置。它根据当前和可用的云基础设施、支出和利用率等因素做出决策。
财务预测
金融市场复杂多变,统计特性会随着时间的推移发生变化。RL 算法可以通过考虑交易成本和适应市场变化来提升长期回报。
例如,算法可以在测试行为并记录相关奖励之前,观察股票市场的规则和模式。它会动态创建价值函数,并制定策略来尽可能提高利润。
强化学习如何运作?
强化学习(RL)算法的学习过程类似于行为心理学领域的动物和人类强化学习。例如,儿童可能会发现,当其帮助兄弟姐妹或打扫卫生时,他们会得到父母的称赞;但是,当其乱扔玩具或大喊大叫时,他们会受到父母的批评。儿童很快就会知道哪些活动最终会得到奖励。
RL 算法模仿类似的学习过程。该算法尝试不同的活动来学习相关的负值和正值,以实现最终的奖励结果。
重要概念
在强化学习中,需要熟悉几个关键概念:
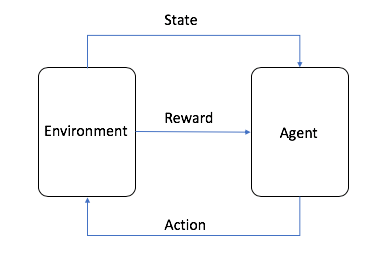
- 代理是 ML 算法(或自治系统)
- 环境是具有变量、边界值、规则和有效操作等属性的自适应问题空间
- 操作是 RL 代理在环境中导航时采取的步骤
- 状态是给定时间点的环境
- 奖励是执行操作的正值、负值或零值,换句话说就是奖励或惩罚
- 累积奖励是所有奖励的总和或最终值
算法基础知识
强化学习基于 Markov 决策过程,Markov 决策过程是一种使用离散时间步骤的数学决策建模。在每一步中,代理都会执行新的操作,从而产生新的环境状态。同样,当前状态归因于先前操作的顺序。
通过在环境中移动进行反复试验,代理构建一组 if-then 规则或策略。这些策略可以帮助代理决定下一步要执行哪些操作以获得最佳的累积奖励。代理还必须选择是进一步探索环境以学习新的状态操作奖励,还是从给定状态选择已知的高奖励操作。这就是所谓的勘探-开采权衡。
有哪些类型的强化学习算法?
强化学习(RL)使用了多种算法,例如 Q-Learning、策略梯度法、蒙特卡罗方法和时序差分学习。深度 RL 是深度神经网络在强化学习领域的应用。深度 RL 算法的一个示例是信任区域策略优化(TRPO)。
所有这些算法可以分为两大类。
基于模型的 RL
基于模型的 RL 通常用于环境定义明确、不会发生变化,且难以进行真实环境测试的情况。
代理首先构建环境的内部表示形式(模型)。它通过以下过程来构建此模型:
- 在环境中采取行动,并记录新的状态和奖励值
- 将行动状态过渡与奖励值相关联。
模型构建完成后,代理将根据最佳累积奖励的概率模拟行动序列。然后,进一步为行动序列本身分配值。因此,代理会在环境中制定不同的策略,来实现预期的最终目标。
示例
假设一个机器人正在学习在某个新建筑物中导航,以到达特定房间。最初,该机器人可以自由探索,并构建建筑物的内部模型(或地图)。例如,它可能会学到,自己从正门向前移动 10 米后遇到了一部电梯。构建地图后,它可以在建筑物中经常访问的不同位置之间建立一系列最短路线序列。
无模型 RL
当环境规模大、复杂且不易描述时,最好使用无模型 RL。当环境未知且不断变化,并且基于环境的测试没有发现明显的缺点时,该环境也是理想选择。
代理不会构建环境及其动态的内部模型。相反,它会在环境中使用反复试验的方法。它会为状态-行动对及其序列打分并记录下来,以制定策略。
示例
以一辆需要在城市车流中穿行的自动驾驶汽车为例。道路、交通模式、行人行为和无数的其他因素都可能使环境变得非常复杂多变。在初始阶段,AI 团队在模拟环境中训练车辆。车辆根据其当前状态采取行动并获得奖励或惩罚。
随着时间的推移,通过在不同的虚拟场景中行驶数百万英里后,车辆无需对整个交通动态进行明确建模,即可了解最适合各种状态的相应行动。引入现实世界后,车辆会使用学到的策略,但也会继续利用新数据完善该策略。
强化机器学习、有监督机器学习和无监督机器学习之间有什么区别?
虽然有监督学习、无监督学习和强化学习(RL)都是人工智能领域的机器学习算法,但三者之间有区别。
强化学习与有监督学习
在有监督学习中,您可以定义输入和预期的关联输出。例如,您可以提供一组标有狗或猫的图像,然后算法会将新的动物图像识别为狗或猫。
有监督学习算法会学习模式以及输入和输出对之间的关系。然后,算法会根据新的输入数据预测结果。它要求监督者(通常是人类)用输出标记训练数据集中的每条数据记录。
相比之下,RL 有明确的最终目标,即预期结果,但没有监督者事先标记相关数据。在训练过程中,它不会尝试将输入映射到已知输出,而是将输入映射到可能的结果。通过奖励所需的行为,您可以权衡最佳结果。
强化学习与无监督学习
在训练过程中,无监督学习算法接收没有指定输出的输入。它们使用统计手段在数据中发现隐藏的模式和关系。例如,您可以提供一组文档,然后算法可能会根据文本中的字词,将其划分到将自己识别的类别中。您不会获得具体结果;结果会在某个范围内。
相反,RL 有预先确定的最终目标。虽然 RL 需要探索性方法,但探索会不断得到验证和改进,以提高实现最终目标的可能性。它可以自学以实现非常具体的结果。
强化学习面临哪些挑战?
虽然强化学习(RL)应用程序有可能改变世界,但部署这些算法可能并不容易。
实用性
用现实世界的奖励和惩罚系统进行试验可能不切实际。例如,在现实世界中测试无人机,而不先在模拟器中进行测试,会导致大量飞机损坏。现实世界的环境经常发生显著变化,而且警告有限。这可能会使算法在实践中难以发挥作用。
可解释性
像任何科学领域一样,数据科学也着眼于确凿的研究和调查发现,以建立标准和程序。数据科学家更想要知道如何得出具体结论,以便进行证明和重复。
对于复杂的 RL 算法,可能很难确定采取特定步骤序列的原因。序列中的哪些操作导致了最佳最终结果? 这可能很难推断,给实施带来了挑战。
AWS 如何提供强化学习方面的帮助?
Amazon Web Services(AWS)提供许多产品,可以帮助您为现实世界的应用程序开发、训练和部署强化学习(RL)算法。
借助 Amazon SageMaker,开发人员和数据科学家可以快速轻松地开发可扩展的 RL 模型。将深度学习框架(比如 TensorFlow 或 Apache MXNet)、RL 工具包(比如 RL Coach 或 RLlib)和一个模仿现实世界场景的环境相结合。您可以用它来创建和测试您的模型。
借助 AWS RoboMaker,开发人员可以在没有任何基础设施要求的情况下,使用机器人的 RL 算法运行、扩展和自动执行模拟。
亲身体验 AWS DeepRacer,这是一款完全自主的 1/18 比例赛车。它拥有完全配置的云环境,可用于训练 RL 模型和神经网络配置。
立即创建账户,开始在 AWS 上使用强化学习。