처리량은 늘리고 지연 시간은 단축하도록 개발된 Amazon CloudSearch는 34개국 언어에 대한 언어별 텍스트 처리, 자유 텍스트 검색, 패싯 검색, 지형 정보 검색, 사용자 지정 가능한 관련성 순위, 강조 표시, 자동 완성, 사용자 구성 가능한 조정 및 가용성 옵션을 비롯하여 다양한 기능을 지원합니다.
Amazon CloudSearch를 사용하려면 다음과 같은 간단한 단계를 따르십시오.
- 검색 도메인 생성
- 데이터에 대한 인덱싱 옵션 구성
- 인덱싱할 데이터 업로드
- 웹 사이트나 애플리케이션에서 검색 요청 제출
아래 섹션에 CloudSearch 작동 방법에 대한 세부 정보가 나와 있습니다.
무료로 Amazon CloudSearch 사용해 보기
CloudSearch 무료 평가판 시작자세히 알아보기
모든 기능을 갖춘 검색 인스턴스를 30일 750시간 동안 무료로 사용하십시오. 시작하려면 다음을 수행합니다.
AWS 계정에 로그인하고 CloudSearch Console을 시작합니다.
몇 번의 클릭으로 검색 도메인을 생성하고 구성합니다.
검색 가능하게 만들 데이터 집합에 대해 Amazon CloudSearch 검색 도메인을 생성합니다. 검색 도메인에는 검색 엔진을 운영하는 데 필요한 하드웨어 및 소프트웨어 리소스와 데이터가 포함됩니다. 각 검색 도메인에는 하나 이상의 검색 인스턴스가 있습니다. 검색 인스턴스는 정해진 양의 RAM 및 CPU 리소스를 이용해 데이터를 인덱싱하고 요청 처리 작업을 수행하는 서버 인스턴스입니다. 도메인의 검색 인스턴스 수는 검색 요청의 양과 복잡도, 데이터 집합 내의 문서 수에 따라 다릅니다.
관리형 검색 서비스인 Amazon CloudSearch가 짧은 지연 시간과 높은 처리량의 검색 성능을 제공하기 위해 필요한 검색 인스턴스의 크기와 수를 결정합니다. 검색 도메인을 만들면 Amazon CloudSearch에서 기본적으로 스몰 검색 인스턴스 유형(search.m1.small)을 사용합니다. 규모가 더 큰 검색 인스턴스 유형을 선택하면 도메인의 업데이트 용량을 늘리고 대규모 데이터 집합을 업로드하고 인덱싱하는 데 소요되는 시간을 단축할 수 있습니다. 규모가 가장 큰 인스턴스 유형보다 더 많은 용량이 필요한 경우에는 인스턴스 수를 늘린 다음 인덱스를 여러 인스턴스로 분할할 수 있습니다.
검색 인덱스에 있는 데이터의 양이 증가하면 Amazon CloudSearch에서 필요한 만큼 검색 도메인을 자동 확장합니다. 인덱스가 현재 인스턴스 유형의 용량을 초과하면 도메인이 다음 크기의 인스턴스 유형으로 확장됩니다. 검색 인덱스가 가장 규모가 큰 인스턴스 유형의 용량을 초과하는 경우 Amazon CloudSearch에서 인덱스를 여러 인스턴스로 분할합니다. 반대로 인덱스 용량이 줄면 CloudSearch에서 도메인의 파티션 수를 줄이거나 더 작은 검색 인스턴스 유형으로 축소합니다.
또한 처리해야 하는 검색 트래픽의 양이 증가하면 Amazon CloudSearch가 자동 확장됩니다. 검색 인스턴스가 최대 쿼리 로드에 근접하면 CloudSearch는 검색 인스턴스의 복제본을 배포합니다. 반대로 트래픽이 줄면 Amazon CloudSearch는 불필요한 복제본을 제거하여 비용을 최소화합니다.
예를 들어 3개의 파티션으로 분할된 검색 인스턴스는 3개의 검색 인스턴스를 사용합니다(파티션당 1개). 검색 트래픽이 증가하여 개별 검색 인스턴스의 처리 용량을 초과하면 추가 쿼리 용량을 제공할 수 있도록 파티션이 복제됩니다. 인스턴스가 복제되면 도메인에 총 6개의 검색 인스턴스(파티션당 2개)가 실행됩니다. 트래픽이 계속 증가하면 Amazon CloudSearch는 필요한 만큼 복제본을 추가합니다.
많은 양의 쿼리 트래픽 또는 갑작스러운 트래픽 증가가 예상되면 도메인에 검색 인스턴스 복제본을 명시적으로 추가할 수 있습니다.

AWS 웹 사이트의 계정 활동 페이지에서, AWS Management Console을 통해 또는 AWS CLI나 AWS SDK를 통해 CloudSearch API 요청을 제출하여 Amazon CloudSearch 도메인이 사용하고 있는 리소스를 확인할 수 있습니다.
각 검색 인스턴스 유형이 지원할 수 있는 데이터의 양은 대부분 인덱싱하는 문서의 크기 및 도메인에 구성된 인덱싱 옵션에 따라 달라집니다.
각 검색 인스턴스 유형의 용량에 대해 설명하기 위해 IMDb 동영상 데이터 세트의 샘플 문서 및 구성을 살펴보겠습니다. 다음 예제는 크기가 약 1KB인 IMDb 동영상 문서를 보여줍니다.
{
"fields" : {
"directors" : [
"Francis Lawrence"
],
"release_date" : "2013-11-11T00:00:00Z",
"genres" : [
"Action",
"Adventure",
"Sci-Fi",
"Thriller"
],
"image_url" : "http://ia.media-imdb.com/images/M/MV5xMzNeMzAx._V1_SX400_.jpg",
"plot" : "Katniss Everdeen and Peeta Mellark become targets of the Capitol after their victory in the 74th Hunger Games sparks a rebellion in the Districts of Panem.","title" : "The Hunger Games: Catching Fire",
"rank" : 4,
"running_time_secs" : 8760,
"actors" : [
"Jennifer Lawrence",
"Josh Hutcherson",
"Liam Hemsworth"
],
"year": 2013
},
"id" : "tt1951264",
"type": "add"
}
이와 같은 동영상 문서를 인덱싱하고 검색하기 위해 문서 필드당 하나의 인덱스 필드를 사용하도록 검색 도메인을 구성합니다. 필드 유형을 비롯하여 필드의 검색, 패시팅, 반환, 정렬, 강조 표시 가능 여부 등 각 필드에 대한 여러 인덱싱 옵션을 지정할 수 있습니다. 이러한 인덱싱 옵션은 검색 인스턴스에 포함될 수 있는 문서 수에 직접적인 영향을 미칩니다. 아래 표는 IMDb 동영상 문서에 대한 샘플 인덱스 필드 구성입니다.
| 이름 |
유형 |
검색 |
패싯 |
반환 |
정렬 | 강조 표시 |
|---|---|---|---|---|---|---|
| actors |
text-array |
✔ | – | ✗ | – | ✗ |
| directors |
text-array |
✔ | – | ✗ | – | ✗ |
| genres |
literal-array |
✔ | ✔ | ✗ |
– | – |
| image_url |
text |
✗ | – | ✗ | ✗ | ✗ |
| plot |
text |
✔ | – | ✗ | ✗ | ✔ |
| rank | int | ✔ | ✗ | ✗ | ✔ | – |
| rating |
double |
✔ | ✔ | ✗ | ✔ | – |
| release_date |
date |
✔ | ✔ | ✗ | ✔ | – |
| running_time_secs |
int |
✔ | ✔ | ✗ | ✔ | – |
| title |
text |
✔ | – | ✔ | ✔ | ✔ |
| year |
int |
✔ | ✔ | ✔ | ✔ | – |
문서 크기(1KB) 및 이 인덱스 구성을 기준으로 각 검색 인스턴스 유형에 포함될 수 있는 문서 용량은 다음 표와 같습니다.
| 검색 인스턴스 유형 | 데이터 용량 |
|---|---|
| 스몰 검색 인스턴스(search.m1.small) |
문서 200만 개 |
| 라지 검색 인스턴스(search.m1.large) | 문서 800만 개 |
| 엑스트라 라지 검색 인스턴스(search.m2.xlarge) |
문서 1,600만 개 |
| 더블 엑스트라 라지 검색 인스턴스(search.m2.2xlarge) | 문서 3,200만 개 |
물론, 이는 하나의 예에 불과합니다. 문서 또는 구성이 달라지면 인스턴스에 포함될 수 있는 문서 수가 크게 변경될 수 있습니다. 단일 더블 엑스트라 라지 검색 인스턴스의 용량이 초과되면 Amazon CloudSearch는 추가 더블 엑스트라 라지 검색 인스턴스에 검색 인덱스를 자동 분할합니다. 인덱스는 최대 10개의 더블 엑스트라 라지 검색 인스턴스에 분할되어 수천 또는 수억 개 이상의 문서를 지원할 수 있습니다. 추가 확장이 필요한 경우 당사에 문의하시기 바랍니다.
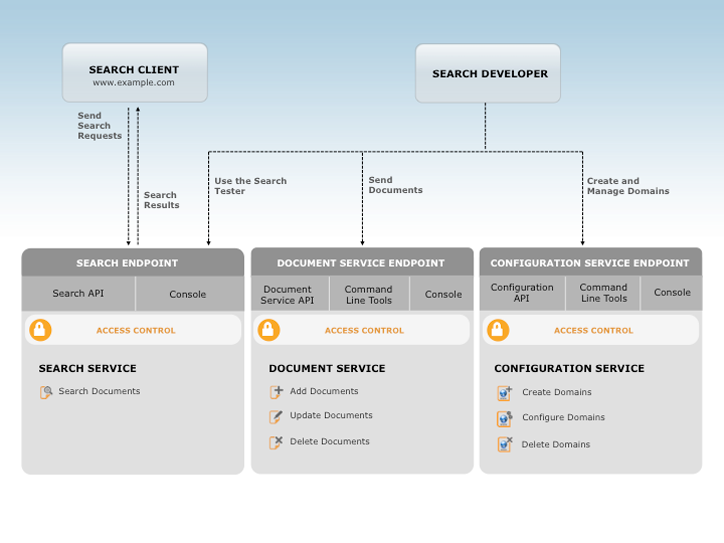
Amazon CloudSearch는 다음 3가지 서비스를 통해 사용합니다.
- 구성 서비스 – 검색 도메인 생성 및 구성
- 문서 서비스 – 문서 일괄 업로드
- 검색 서비스 – 검색 및 제안 요청 제출
Amazon CloudSearch 구성 서비스 및 각 도메인의 문서와 검색 서비스에 대한 액세스 권한을 관리하는 데는 AWS Identity and Access Management(IAM) 정책을 사용합니다.
구성 서비스로 검색 도메인을 생성하고 구성할 수 있습니다. 검색 도메인을 설정하려면 고유한 이름을 지정하고 인덱싱 옵션, 텍스트 분석 스키마, 가용성 옵션, 조정 옵션, 제안 기능 및 표현식을 구성합니다.
- 인덱싱 옵션에서 인덱스에 포함하려는 필드를 지정합니다. AWS Management Console 또는 Amazon CloudSearch 명령행 도구를 사용하면 데이터를 스캔하여 기본 인덱싱 옵션을 자동 구성할 수 있습니다.
- 텍스트 분석 체계는 text 및 text-array 필드의 언어별 텍스트 처리 옵션을 지정합니다. 분석 체계는 인덱싱 중 무시해야 하는 불용어 제어하고, 용어의 일반적인 동의어를 정의하고, 단어를 공통 어간에 매핑하는 방식을 지정합니다.
- 가용성 옵션을 사용하면 두 개의 가용 영역에 하나의 도메인을 배포하여 서비스 중단 시에도 고가용성을 보장할 수 있습니다.
- 조정 옵션을 사용하면 원하는 인스턴스 유형, 복제본 수 및 파티션 수를 지정하여 도메인을 사전 조정할 수 있습니다. 이 기능은 문서를 대량으로 업로드하거나 쿼리 트래픽이 크게 증가할 것으로 예상되는 경우에 유용합니다.
- 입력어 제안기를 사용하면 현재 입력 중인 미완성 검색 쿼리에 대해서도 가능한 결과가 검색되므로 사용자 입력과 동시에 바로 결과를 표시할 수 있습니다.
- 표현식은 쿼리 시에 평가되는 숫자 표현식입니다. 표현식을 사용하면 검색 결과의 순위를 제어할 수 있습니다. 기본적으로 문서 내에서 검색어가 사용된 빈도에 따른 관련성 점수로 문서의 순위가 매겨집니다. 표현식을 사용하면 순위 도출에 다른 요소를 포함할 수 있습니다. 예를 들어, 문서에 '인기도'라는 이름의 숫자 필드가 있는 경우, 인기 있는 관련 문서가 검색 결과에서 더 높은 순위로 나타나도록 기본 관련성 점수와 인기도를 결합한 표현식을 정의할 수 있습니다.
문서 서비스를 사용하여 변경 사항을 도메인에서 검색 가능한 데이터로 만들 수 있습니다. 각 도메인에는 고유의 문서 서비스 HTTP 엔드포인트가 있습니다.
도메인으로 데이터를 전송하려면 해당 데이터를 JSON 또는 XML 형식으로 지정해야 합니다. 검색 결과로 반환하려고 하는 각 항목은 문서로 표시됩니다. 모든 문서에는 고유한 ID 및 검색하여 결과로 반환할 데이터가 포함된 하나 이상의 필드가 있습니다. 문서 필드는 모든 UTF-8 문자열 데이터를 포함할 수 있습니다. 도메인의 인덱싱 옵션은 데이터를 인덱싱하고 사용하려는 방법을 지정합니다.
검색 서비스는 도메인에 대한 검색 및 제안 요청을 처리합니다. 각 도메인에는 고유의 검색 HTTP 엔드포인트가 있습니다. 검색 또는 제안 요청을 보내면 검색 서비스에서 일치하는 문서 목록을 반환합니다. 결과는 JSON 또는 XML 형식으로 반환될 수 있습니다.
Amazon CloudSearch에서는 다양한 쿼리 언어를 제공하므로 이를 사용하여 특정 필드 내에서 검색하고, 복잡한 부울 검색을 수행하며, 패싯 정보를 검색하고, 결과에 포함하길 원하는 데이터를 지정할 수 있습니다. 또한, 쿼리 용어가 처리되는 방법과 쿼리 용어가 Lucene 또는 DisMax 파서와 같은 다른 쿼리 파서를 사용하는 방법을 제어하는 옵션을 지정할 수도 있습니다.
Amazon CloudSearch 콘솔의 검색 테스터를 사용하여 샘플 쿼리를 테스트할 수 있습니다.
이 서비스 사용은 Amazon Web Services 고객 계약에 따릅니다.