



O que é aprendizado por reforço?
O aprendizado por reforço (RL) é uma técnica de machine learning (ML) que treina o software para tomar decisões em busca dos melhores resultados. Ele imita o processo de aprendizado por tentativa e erro que os seres humanos usam para atingir seus objetivos. As ações de software que atingem sua meta são reforçadas, enquanto as ações que prejudicam a meta são ignoradas.
Os algoritmos de RL usam um paradigma de recompensa e punição ao processar dados. Eles aprendem com o feedback de cada ação e descobrem por si mesmos os melhores caminhos de processamento para alcançar os resultados finais. Os algoritmos também são capazes de atrasar a gratificação. A melhor estratégia geral pode exigir sacrifícios de curto prazo. Por isso, a melhor abordagem que eles descobrem pode incluir algumas punições ou retrocessos ao longo do caminho. O RL é um método poderoso para ajudar os sistemas de inteligência artificial (IA) a alcançar resultados ideais em ambientes inéditos.
Quais são os benefícios do aprendizado por reforço?
Há muitos benefícios em usar o aprendizado por reforço (RL). No entanto, esses três geralmente se destacam.
Destaca-se em ambientes complexos
Os algoritmos de RL podem ser usados em ambientes complexos com muitas regras e dependências. No mesmo ambiente, um ser humano pode não ser capaz de determinar o melhor caminho a seguir, mesmo com um conhecimento superior do ambiente. Em vez disso, algoritmos de RL sem modelo se adaptam rapidamente a ambientes em constante mudança e encontram novas estratégias para otimizar os resultados.
Requer menos interação humana
Nos algoritmos de ML tradicionais, os seres humanos devem rotular os pares de dados para direcionar o algoritmo. Quando você usa um algoritmo de RL, isso não é necessário. Ele aprende sozinho. Ao mesmo tempo, oferece mecanismos para integrar o feedback humano, permitindo sistemas que se adaptam às preferências, conhecimentos e correções humanos.
Otimiza para metas de longo prazo
O RL se concentra inerentemente na maximização da recompensa de longo prazo, o que o torna adequado a cenários em que as ações têm consequências prolongadas. É particularmente adequado a situações do mundo real em que o feedback não está imediatamente disponível para cada etapa, pois pode aprender com recompensas atrasadas.
Por exemplo, decisões sobre consumo ou armazenamento de energia podem ter consequências em longo prazo. O RL pode ser usado para otimizar a eficiência e o custo de energia em longo prazo. Com arquiteturas apropriadas, os atendentes de RL também podem generalizar suas estratégias aprendidas em tarefas semelhantes, mas não idênticas.
Quais são os casos de uso do aprendizado por reforço?
O aprendizado por reforço (RL) pode ser aplicado a uma ampla variedade de casos de uso do mundo real. Veja alguns exemplos a seguir.
Personalização de marketing
Em aplicações como sistemas de recomendação, o RL pode personalizar sugestões para usuários individuais com base em suas interações. Isso leva a experiências mais personalizadas. Por exemplo, uma aplicação pode exibir anúncios para um usuário com base em algumas informações demográficas. Com cada interação com o anúncio, a aplicação aprende quais anúncios exibir para o usuário para otimizar as vendas do produto.
Desafios de otimização
Os métodos tradicionais de otimização resolvem problemas avaliando e comparando possíveis soluções com base em determinados critérios. Em contraste, o RL introduz o aprendizado a partir das interações para encontrar as melhores ou mais próximas das melhores soluções ao longo do tempo.
Por exemplo, um sistema de otimização de gastos na nuvem usa RL para se ajustar às necessidades flutuantes de recursos e escolher tipos, quantidades e configurações de instância ideais. Ele toma decisões com base em fatores como infraestrutura de nuvem atual e disponível, gastos e utilização.
Previsões financeiras
A dinâmica dos mercados financeiros é complexa, com propriedades estatísticas que mudam com o tempo. Os algoritmos de RL podem otimizar os retornos de longo prazo considerando os custos de transação e se adaptando às mudanças do mercado.
Por exemplo, um algoritmo pode observar as regras e padrões do mercado de ações antes de testar ações e registrar as recompensas associadas. Ele cria dinamicamente uma função de valor e desenvolve uma estratégia para maximizar os lucros.
Como funciona o aprendizado por reforço?
O processo de aprendizagem dos algoritmos de aprendizado por reforço (RL) é semelhante ao aprendizado por reforço animal e humano no campo da psicologia comportamental. Por exemplo, uma criança pode descobrir que recebe elogios dos pais quando ajuda um irmão ou faxineira, mas recebe reações negativas quando joga brinquedos ou grita. Logo, a criança aprende qual combinação de atividades resulta na recompensa final.
Um algoritmo de RL imita um processo de aprendizagem similar. Experimenta atividades diferentes para aprender os valores negativos e positivos associados a fim de alcançar o resultado final da recompensa.
Principais conceitos
No aprendizado por reforço, existem alguns conceitos-chave com os quais você deve se familiarizar:
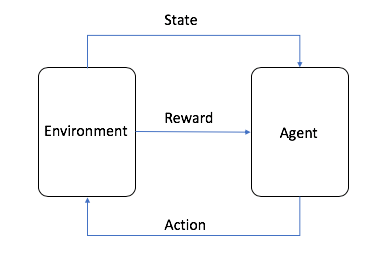
- O agente é o algoritmo de ML (ou o sistema autônomo)
- O ambiente é o espaço adaptativo do problema com atributos como variáveis, valores limite, regras e ações válidas
- A ação é uma etapa que o agente de RL executa para navegar pelo ambiente
- O estado é o ambiente em um determinado momento
- A recompensa é o valor positivo, negativo ou zero, em outras palavras, a recompensa ou punição, por realizar uma ação
- A recompensa cumulativa é a soma de todas as recompensas ou o valor final
Noções básicas sobre algoritmos
O aprendizado por reforço é baseado no processo de decisão de Markov, uma modelagem matemática da tomada de decisão que usa etapas de tempo discretas. Em cada etapa, o agente realiza uma nova ação que resulta em um novo estado do ambiente. Da mesma forma, o estado atual é atribuído à sequência de ações anteriores.
Por meio de tentativa e erro na movimentação pelo ambiente, o agente cria um conjunto de regras ou políticas if-then. As políticas ajudam a decidir qual ação tomar em seguida para obter uma recompensa cumulativa ideal. O agente também deve escolher entre explorar mais o ambiente para aprender novas recompensas de ação estadual ou selecionar ações conhecidas de alta recompensa de um determinado estado. Isso é chamado de compensação de exploration-exploitation.
Quais são os tipos de algoritmos de aprendizado por reforço?
Existem vários algoritmos usados no aprendizado por reforço (RL), como o Q-learning, métodos de gradiente de políticas, métodos de Monte Carlo e aprendizado por diferença temporal. O RL profundo é a aplicação de redes neurais profundas para reforçar o aprendizado. Um exemplo de algoritmo de RL profundo é o Trust Region Policy Optimization (TRPO).
Todos esses algoritmos podem ser agrupados em duas grandes categorias.
RL baseado em modelos
O RL baseado em modelos normalmente é usado quando os ambientes são bem definidos e imutáveis e onde o teste do ambiente no mundo real é difícil.
O atendente primeiro cria uma representação interna (modelo) do ambiente. Ele usa esse processo para criar esse modelo:
- Ele realiza ações dentro do ambiente e observa o novo estado e o valor da recompensa
- Ele associa a transição do estado de ação ao valor da recompensa.
Quando o modelo é concluído, o atendente simula sequências de ação com base na probabilidade de recompensas cumulativas ideais. Em seguida, atribui ainda mais valores às próprias sequências de ação. Assim, o atendente desenvolve diferentes estratégias dentro do ambiente para atingir o objetivo final desejado.
Exemplo
Considere um robô aprendendo a navegar em um novo prédio para chegar a uma sala específica. Inicialmente, o robô explora livremente e cria um modelo interno (ou mapa) do prédio. Por exemplo, ele pode descobrir que encontra um elevador depois de avançar 10 metros da entrada principal. Depois de criar o mapa, ele pode criar uma série de sequências de caminho mais curto entre os diferentes locais que visita com frequência no prédio.
RL sem modelo
É melhor usar o RL sem modelo quando o ambiente é grande, complexo e não é facilmente descritível. Ele também é ideal quando o ambiente é desconhecido, está mudando e os testes baseados no ambiente não apresentam desvantagens significativas.
O atendente não cria um modelo interno do ambiente e de sua dinâmica. Em vez disso, ele usa uma abordagem de tentativa e erro dentro do ambiente. Ele pontua e anota pares de ações estatais e sequências de pares de ações estatais para desenvolver uma política.
Exemplo
Considere um carro autônomo que precisa navegar pelo trânsito da cidade. Estradas, padrões de tráfego, comportamento de pedestres e inúmeros outros fatores podem tornar o ambiente altamente dinâmico e complexo. As equipes de IA treinam o veículo em um ambiente simulado nos estágios iniciais. O veículo realiza ações com base em seu estado atual e recebe recompensas ou multas.
Com o tempo, ao dirigir milhões de quilômetros em diferentes cenários virtuais, o veículo aprende quais ações são melhores para cada estado sem modelar explicitamente toda a dinâmica do tráfego. Quando introduzido no mundo real, o veículo usa a política aprendida, mas continua a refiná-la com novos dados.
Qual é a diferença entre machine learning reforçado, supervisionado e não supervisionado?
Embora o aprendizado supervisionado, o aprendizado não supervisionado e o aprendizado por reforço (RL) sejam todos algoritmos de ML no campo da IA, há distinções entre os três.
Leia sobre aprendizado supervisionado e não supervisionado »
Aprendizado por reforço versus aprendizado supervisionado
No aprendizado supervisionado, você define tanto a entrada quanto a saída associada esperada. Por exemplo, você pode apresentar um conjunto de imagens rotuladas como cães ou gatos. Com isso, espera-se que o algoritmo identifique uma nova imagem de animal como um cachorro ou gato.
Os algoritmos de aprendizado supervisionado aprendem padrões e relacionamentos entre os pares de entrada e saída. Em seguida, eles preveem os resultados com base em novos dados de entrada. É necessário que um supervisor, normalmente uma pessoa, rotule cada registro de dados em um conjunto de dados de treinamento com uma saída.
Em contraste, o RL tem uma meta final bem definida na forma de um resultado desejado, mas nenhum supervisor para rotular os dados associados com antecedência. Durante o treinamento, em vez de tentar mapear entradas com saídas conhecidas, ele mapeia entradas com resultados possíveis. Ao recompensar os comportamentos desejados, você dá peso aos melhores resultados.
Aprendizado por reforço versus aprendizado não supervisionado
Algoritmos de aprendizado não supervisionado recebem entradas sem saídas especificadas durante o processo de treinamento. Eles encontram padrões e relacionamentos ocultos nos dados usando meios estatísticos. Por exemplo, você pode apresentar um conjunto de documentos e o algoritmo pode agrupá-los em categorias que ele identifica com base nas palavras do texto. Você não obtém nenhum resultado específico; eles estão dentro de um intervalo.
Por outro lado, o RL tem um objetivo final predeterminado. Embora seja necessária uma abordagem exploratória, as explorações são continuamente validadas e aprimoradas para aumentar a probabilidade de atingir a meta final. Ele pode aprender sozinho a alcançar resultados muito específicos.
Quais são os desafios do aprendizado por reforço?
Embora as aplicações de aprendizado por reforço (RL) possam potencialmente mudar o mundo, talvez não seja fácil implantar esses algoritmos.
Praticidade
Experimentar sistemas de recompensa e punição do mundo real pode não ser prático. Por exemplo, testar um drone no mundo real sem testar primeiro em um simulador resultaria em um número significativo de aeronaves quebradas. Os ambientes do mundo real mudam com frequência, de forma significativa e com aviso limitado. Isso pode dificultar a eficácia do algoritmo na prática.
Interpretabilidade
Como qualquer campo da ciência, a ciência de dados também analisa pesquisas e descobertas conclusivas para estabelecer padrões e procedimentos. Os cientistas de dados preferem saber como uma conclusão específica foi alcançada para comprovação e replicação.
Com algoritmos de RL complexos, os motivos pelos quais uma sequência específica de etapas foi executada podem ser difíceis de determinar. Quais ações em uma sequência foram as que levaram ao resultado final ideal? Isso pode ser difícil de deduzir, o que causa desafios de implementação.
Como a AWS pode ajudar com o aprendizado por reforço?
A Amazon Web Services (AWS) tem muitas ofertas que ajudam você a desenvolver, treinar e implantar algoritmos de aprendizado por reforço (RL) para aplicações do mundo real.
Com o Amazon SageMaker, desenvolvedores e cientistas de dados podem desenvolver de forma rápida e fácil modelos de RL escaláveis. Combine uma estrutura de aprendizado profundo (como TensorFlow ou Apache MXNet), um kit de ferramentas de RL (como RL Coach ou RLlib) e um ambiente para imitar um cenário do mundo real. Você pode usá-lo para criar e testar seu modelo.
Com o AWS RoboMaker, os desenvolvedores podem executar, escalar e automatizar simulações com algoritmos de RL para robótica sem nenhum requisito de infraestrutura.
Adquira experiência prática com o AWS DeepRacer, o carro de corrida totalmente autônomo em escala 1/18. Ele possui um ambiente de nuvem totalmente configurado que você pode usar para treinar seus modelos de RL e configurações de rede neural.
Comece a usar o aprendizado por reforço na AWS criando uma conta hoje mesmo.