



Что такое маркировка данных?
В машинном обучении маркировка данных - это процесс идентификации необработанных данных (изображений, текстовых файлов, видео и т.д.) и добавления одной или нескольких значимых и информативных меток для обеспечения контекста, чтобы модель машинного обучения могла на них учиться. Например, метки могут указывать, есть ли на фотографии птица или автомобиль, какие слова были произнесены в аудиозаписи или есть ли на рентгеновском снимке опухоль. Маркировка данных необходима для различных сценариев использования, включая машинное зрение, обработку естественного языка и распознавание речи.
Как работает маркировка данных?
Сегодня в большинстве моделей машинного обучения, применяемых на практике, используется обучение под наблюдением, при котором применяется алгоритм для сопоставления входных данных с выходными. Чтобы обучение под наблюдением работало, нужен маркированный набор данных, на основе которого модель сможет учиться принимать правильные решения. Маркировка данных обычно начинается с того, что людям предлагают вынести суждение по определенному фрагменту немаркированных данных. Например, маркировщикам могут дать задание пометить те изображения из набора данных, для которых ответ на вопрос «изображена ли на фотографии птица?» утвердительный. Процесс маркировки может быть как простым (с ответом «да» или «нет»), так и детализированным (когда необходимо определить на изображении конкретные пиксели, связанные с птицей). Модель машинного обучения использует предоставленные человеком метки для изучения основных закономерностей в процессе под названием «обучение модели». В результате получается обученная модель, которую можно использовать для прогнозирования относительно новых данных.
В машинном обучении правильно маркированный набор данных, который используется в качестве объективного стандарта для обучения и оценки такой модели, часто называют «эталонными данными». Точность обученной модели будет зависеть от точности эталонных данных, поэтому крайне важно уделить время и ресурсы для получения высокоточной маркировки данных.
Какие существуют распространенные типы маркировки данных?
Машинное зрение
Чтобы создать обучающий набор данных для разработки системы машинного зрения, сначала необходимо маркировать изображения, пиксели или ключевые точки либо создать рамку, полностью охватывающую цифровое изображение, которая называется ограничительной рамкой. Например, изображения можно классифицировать по типу характерных особенностей (картинки с продуктами или образом жизни) либо по содержанию (что фактически на них изображено) или сегментировать изображение на уровне пикселей. Затем эти обучающие данные можно использовать для разработки модели машинного зрения, которую можно будет применять для автоматической классификации изображений, определения расположения объектов, выявления ключевых точек на изображении или его сегментации.
Обработка естественного языка
Чтобы создать обучающий набор данных для обработки естественного языка, необходимо сначала вручную определить основные разделы текста или расставить в нем определенные метки. К примеру, нужно определить тональность или цель рекламного объявления, определить части речи, классифицировать имена собственные, такие как места и люди, а также определить текст в изображениях, PDF-документах или других файлах. Для этого можно нарисовать рамки вокруг текста, а затем вручную расшифровать его в обучающем наборе данных. Модели обработки естественного языка используются для анализа тональности высказываний, распознавания названий сущностей и оптического распознавания символов.
Обработка аудиоданных
В процессе обработки аудиоданных все виды звуков, такие как речь, звуки дикой природы (лай собак, свист или чириканье птиц) и техногенные звуки (разбитое стекло, сканеры или сирена), преобразуются в структурированный формат, чтобы затем его можно было использовать в машинном обучении. Часто, прежде чем обработать аудиоданные, их необходимо расшифровать в письменный текст. После этого из него можно извлечь более подробные сведения об аудиоданных, добавив теги и классифицировав их. Затем эти классифицированные аудиоданные становятся обучающим набором данных.
Какие существуют рекомендации по маркировке данных?
Существует множество методов повышения эффективности и точности маркировки данных. Некоторые из этих методов перечислены ниже.
- Интуитивно понятные и оптимизированные интерфейсы заданий помогают людям, маркирующим данные, минимизировать когнитивную нагрузку и необходимость переключаться между контекстами.
- Консенсус маркировщиков помогает нейтрализовать ошибки/предвзятость отдельных авторов аннотаций. Консенсус маркировщиков предполагает отправку каждого объекта набора данных нескольким авторам, а затем объединение их ответов (так называемых «аннотаций») в одну метку.
- Аудит меток обеспечивает проверку их точности и обновление по мере необходимости.
- Активное обучение способствует повышению эффективности маркировки данных с помощью машинного обучения, когда определяются наиболее полезные данные для их последующей маркировки людьми.
Как эффективно выполнять маркировку данных?
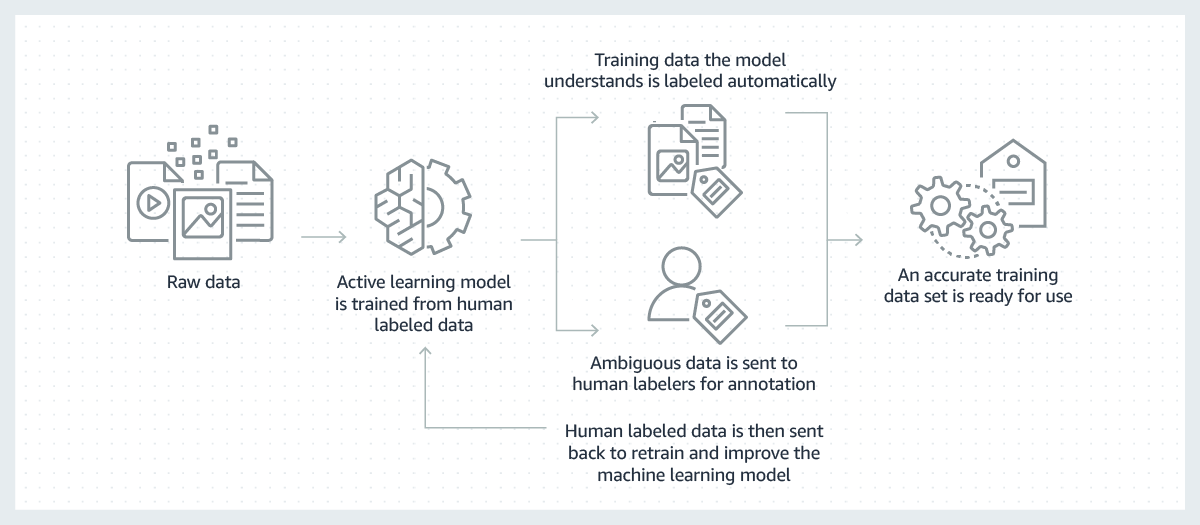
Успешные модели машинного обучения строятся на базе больших объемов высококачественных обучающих данных. Но процесс создания обучающих данных, необходимых для построения этих моделей, зачастую дорог, сложен и отнимает много времени. Для работы большинства современных моделей человек должен вручную маркировать данные так, чтобы дать модели возможность научиться принимать правильные решения. Чтобы облегчить выполнение этой задачи, эффективность маркировки можно повысить, используя модель машинного обучения для автоматической маркировки данных.
В этом процессе модель машинного обучения для маркировки данных сначала обучается на подмножестве первичных данных, промаркированных людьми. В тех случаях, когда модель маркировки достигает высокой степени достоверности полученных результатов на основе пройденного обучения, она автоматически расставляет метки для необработанных данных. Если же степень достоверности ее результатов будет ниже, она передаст задачу по маркировке данных человеку. Затем созданные человеком метки снова передаются в модель маркировки, чтобы она могла на них научиться и улучшить свою способность автоматически маркировать следующий набор необработанных данных. Со временем модель сможет автоматически маркировать все больше и больше данных, что существенно ускорит создание обучающих наборов данных.
Как AWS может поддерживать требования к маркировке данных?
Amazon SageMaker Ground Truth в значительной мере сокращает время и усилия, необходимые для создания обучающих наборов данных. SageMaker Ground Truth обеспечивает доступ государственным и частным специалистам по маркировке данных и предоставляет им встроенные рабочие процессы и интерфейсы для выполнения стандартных задач маркировки. Начать работу с SageMaker Ground Truth очень просто. С помощью учебного пособия по началу работы можно создать первое задание по маркировке за считанные минуты.
Создайте аккаунт уже сегодня и начните работу с маркировкой данных на AWS.
AWS: дальнейшие шаги
Получите мгновенный доступ к уровню бесплатного пользования AWS.