ما المقصود بتصنيف البيانات؟
ما المقصود بتسمية البيانات؟
في التعلم الآلي، تصنيف البيانات هو عملية تحديد البيانات الأولية (الصور والملفات النصية ومقاطع الفيديو وما إلى ذلك) وإضافة واحدة أو أكثر من التصنيفات المفيدة والغنية بالمعلومات لتوفير السياق حتى يتمكن نموذج التعلم الآلي من التعلم منه. على سبيل المثال، قد تشير التسميات إلى ما إذا كانت الصورة تحتوي على طائر أو سيارة، أو الكلمات التي تم نطقها في تسجيل صوتي، أو ما إذا كانت الأشعة السينية تحتوي على ورم. تسمية البيانات هي عملية مطلوبة لمجموعة متنوعة من حالات الاستخدام بما في ذلك رؤية الكمبيوتر، ومعالجة اللغة الطبيعية، والتعرّف على الكلام.
ما آلية عمل تسمية البيانات؟
اليوم، تقوم معظم نماذج تعلّم الآلة العملية باستخدام التعلم الخاضع للإشراف، والذي يطبق خوارزميةً لتعيين إدخال واحد لإخراج واحد. لكي ينجح التعلم الخاضع للإشراف، تحتاج إلى مجموعة بيانات مُسمّاة يُمكن للنموذج التعلم منها لاتخاذ قرارات صحيحة. تسمية البيانات تبدأ عادةً بمطالبة العناصر البشرية بتقييم جزء معين من البيانات غير المسماة. على سبيل المثال، قد يُطلب من المُصنِّفين وضع علامة على جميع الصور في مجموعة بيانات تكون فيها العبارة "هل تحتوي الصورة على طائر" صحيحة. عملية وضع العلامات يُمكن أن تكون بسيطة وعامة مثل نعم/لا أو تكون دقيقةً مثل تحديد وحدات البكسل الموجودة في الصورة المرتبطة بالطائر. يستخدم نموذج تعلّم الآلة التسميات التي توفرها العناصر البشرية لمعرفة الأنماط الأساسية في عملية تسمى "تدريب النماذج". والنتيجة هي نموذج مدرب يُمكن استخدامه في عمل تنبؤات حول البيانات الجديدة.
في تعلّم الآلة، مجموعة البيانات المسماة بشكل صحيح التي تستخدمها كمعيار موضوعي في تدريب وتقييم نموذج معين يُطلق عليها في الغالب "الحقيقة الأساسية". دقة نموذجك المُدرَّب تعتمد على دقة الحقيقة الأساسية لديك، وبالتالي من الضروري قضاء الوقت والموارد لضمان الدقة العالية في تسمية البيانات.
ما بعض الأنواع الشائعة في تسمية البيانات؟
رؤية الحاسوب
عند إنشاء نظام رؤية كمبيوتر، تحتاج أولاً إلى تسمية الصور أو وحدات البكسل أو النقاط الرئيسية، أو إنشاء حد (إطار) يحتوي بالكامل على صورة رقمية يُعرف باسم "مربع إحاطة" لإنشاء مجموعة بيانات التدريب الخاصة بك. على سبيل المثال، يُمكنك تصنيف الصور حسب نوع الجودة (مثل صور منتجات مقابل صور نمط الحياة) أو المحتوى (المحتوى الموجود في الصورة نفسها)، أو يُمكنك تقسيم صورة على مستوى البكسل. يُمكنك بعد ذلك استخدام بيانات التدريب هذه في إنشاء نموذج رؤية كمبيوتر يُمكن استخدامه تلقائيًا في تصنيف الصور، أو اكتشاف موقع الكائنات، أو تحديد النقاط الرئيسية في صورة أو في جزء من صورة.
معالجة اللغة الطبيعية
معالجة اللغة الطبيعية تتطلب منك أولاً تحديد الأقسام المهمة بالنص يدويًا أو وضع علامة على النص باستخدام تسميات محددة لإنشاء مجموعة بيانات التدريب الخاصة بك. على سبيل المثال، قد ترغب في تحديد الشعور أو المقصد من التشويش النصي، وتحديد أجزاء الكلام، وتصنيف أسماء الأعلام مثل الأماكن والأشخاص، وتحديد النص في الصور أو ملفات PDF أو الملفات الأخرى. للقيام بذلك، يُمكنك رسم مربعات إحاطة حول النص ثم نسخ النص يدويًا في مجموعة بيانات التدريب الخاصة بك. نماذج معالجة اللغة الطبيعية تُستخدم في تحليل المشاعر، والتعرّف على أسماء الكيانات، والتعرّف البصري على الحروف.
معالجة الصوت
تحوّل معالجة الصوت جميع أنواع الأصوات مثل الكلام وأصوات الحياة البرية (النباح أو الصفير أو التغريد) والأصوات التي تحدث بالمباني (الزجاج المكسور أو عمليات المسح الضوئي أو الإنذارات) إلى تنسيق مهيكل بحيث يمكن استخدامه في تعلّم الآلة. غالبًا ما تتطلب معالجة الصوت أن تقوم أولاً بنسخه يدويًا إلى نص مكتوب. وبعد ذلك، يُمكنك اكتشاف معلومات أعمق حول الصوت عن طريق إضافة علامات وتصنيف الصوت. يُصبح هذا الصوت المصنف مجموعة بيانات التدريب الخاصة بك.
ما بعض أفضل الممارسات في تسمية البيانات؟
توجد العديد من التقنيات التي تحسّن كفاءة تسمية البيانات وتزيد من دقتها. من هذه التقنيات ما يلي:
- واجهات مهام ذكية ومبسطة للمساعدة في تقليل الحمل المعرفي وتبديل السياق لأدوات التسمية البشرية.
- توافق المُصنِّفين للمساعدة في مواجهة الخطأ/التحيز الموجود لدى المعلقين الأفراد. توافق المُصنِّفين يشمل إرسال كل كائن مجموعة بيانات إلى العديد من المعلقين ثم دمج ردودها (تسمى "التعليقات التوضيحية") في تسمية واحدة.
- تدقيق التسميات للتحقق من دقة التسميات وتحديثها إن لزم الأمر.
- التعلّم النشط لزيادة كفاءة تسمية البيانات عن طريق استخدام تعلّم الآلة لتحديد البيانات الأكثر فائدةً ليتم تسميتها بواسطة عناصر بشرية.
كيف تتحقق الكفاءة في تسمية البيانات؟
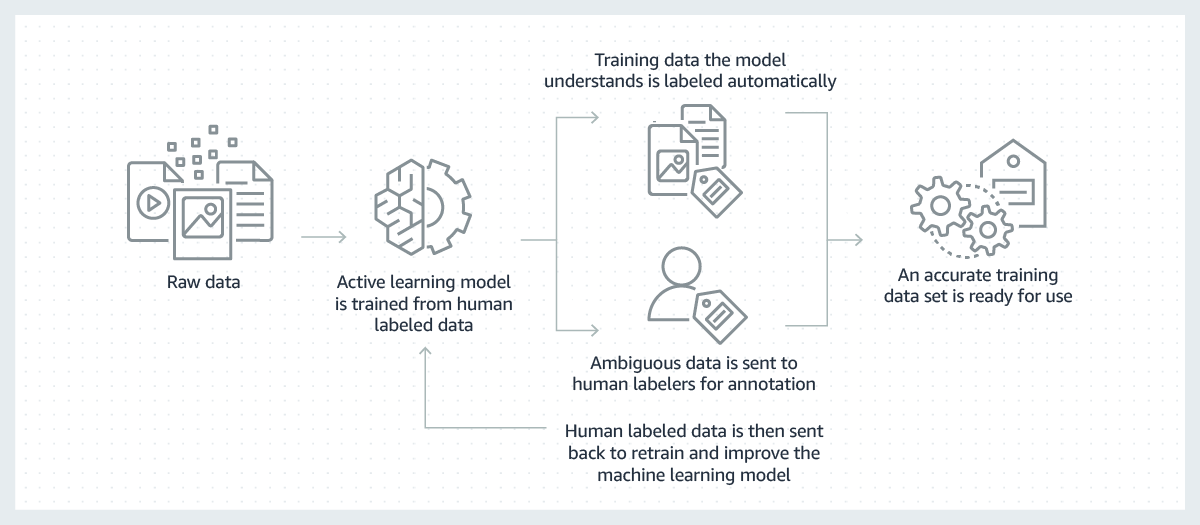
تستند النماذج الناجحة لتعلم الآلة إلى كميات كبيرة من بيانات التدريب عالية الجودة. ولكنَّ عملية إنشاء بيانات التدريب الضرورية لبناء هذه النماذج غالبًا ما تكون مكلفة، ومعقدة، وتستغرق وقتًا طويلاً. تتطلب غالبية النماذج التي تم إنشاؤها اليوم أن يقوم عنصر بشري بتسمية البيانات يدويًا بطريقة تسمح للنموذج بتعلّم كيفية اتخاذ قرارات صحيحة. للتغلب على هذا التحدي، يُمكن جعل التسميات أكثر كفاءةً باستخدام نموذج تعلّم آلة لتسمية البيانات تلقائيًا.
في هذه العملية، يتم تدريب نموذج تعلّم آلة لتسمية البيانات أولاً على مجموعة فرعية من بياناتك الأولية قامت عناصر بشرية بتسميتها. عندما يكون نموذج التسمية شديد الثقة في نتائجه بناءً على ما تعلمه حتى الآن، فإنه يقوم تلقائيًا بتطبيق التسميات على البيانات الأولية. عندما يكون نموذج التسمية أقل ثقةً في نتائجه، فإنه ينقل البيانات إلى العناصر البشرية للقيام بالتسمية. بعد ذلك، تتم إعادة التسميات التي أنشأتها العناصر البشرية إلى نموذج التسمية ليتعلم منها وليحسّن قدرته على تسمية المجموعة التالية من البيانات الأولية تلقائيًا. وبمرور الوقت، يُمكن للنموذج تسمية المزيد والمزيد من البيانات تلقائيًا وتسريع إنشاء مجموعات بيانات التدريب بشكل كبير.
كيف تساعدك AWS في تلبية متطلبات تسمية البيانات؟
يقلل Amazon SageMaker Ground Truth بشكل كبير من الوقت والجهد اللازمين لإنشاء مجموعات بيانات للتدريب. يوفر SageMaker Ground Truth إمكانية وصول إلى أدوات تسمية بشرية عامة وخاصة وتوفر لها تدفقات عمل مضمنة وواجهات لإجراء مهام التسمية الشائعة. من السهل بدء استخدام SageMaker Ground Truth. يُمكن استخدام البرنامج التعليمي حول البدء لإنشاء وظيفة التسمية الأولى في دقائق.
ابدأ اليوم استخدام "تسمية البيانات" على AWS من خلال إنشاء حساب.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages