Apache Accumulo and Amazon Elastic MapReduce
This article will show you how to install and use Apache Accumulo with Amazon Elastic MapReduce.
Submitted By: Parviz Deyhim
Language(s): java
Created On: February 19, 2013
Apache Accumulo and Amazon Elastic MapReduce
Introducing Apache Accumulo
Apache Accumulo is a sorted, distributed key-value store that is built on top of Apache Hadoop, Apache Zookeeper, and Apache Thrift. Accumulo is written in Java, and has several unique features including:
- User permissions and access control, including cell-based access labels
- Server-side features called iterators for additional data management capabilities
- An extensible balancing algorithm
- High-ingest performance
- High-level features for data management including: table merge, efficient data deletion, table renaming, table cloning, fast and efficient table splitting
Accumulo has several security features that make it an ideal distributed, key-value store for managing sensitive information applicable to many industries. Accumulo has per-cell visibility labels as well as table access control lists (ACLs). Each cell has an ACL of what the user may see, while users who do not have access to those cells do not even know they exist.
For more information about Apache Accumulo and how to configure it, see https://accumulo.apache.org/. For more information about Accumulo features, see https://accumulo.apache.org/notable_features.html.
Accumulo is designed to run on top of the Hadoop architecture, which means you can distribute operations across many computers in a cluster to efficiently parse vast amounts of data. In this article, we walk through how to provision an Accumulo cluster instance using Amazon EMR.
Amazon Elastic MapReduce (Amazon EMR) makes it easy to run Hadoop in the Amazon Web Services (AWS) cloud. With Amazon EMR, you can set up a Hadoop cluster in minutes and automatically terminate the resources when the processing is complete. For information about Amazon EMR, see the Amazon Elastic MapReduce Documentation.
To install Accumulo, you use Amazon EMR bootstrap actions. Bootstrap actions allow you to install custom applications or libraries on EMR nodes and pass a reference to a script stored in Amazon Simple Storage Service (Amazon S3). This script can contain configuration settings and arguments related to Hadoop or Amazon EMR. Bootstrap actions are run before Hadoop starts and before the node begins processing data.
Before You Begin
There is a prerequisite to deploying Accumulo on Amazon EMR: you need to have a Zookeeper cluster up and running. Accumulo uses ZooKeeper to coordinate settings between processes and helps finalize TabletServer failure.
There are many ways to install Zookeeper on AWS. You can download Zookeeper from https://zookeeper.apache.org/ and follow https://zookeeper.apache.org/doc/trunk/zookeeperStarted.html to run a simple Zookeeper cluster.
You can also use Apache Whirr to install Zookeeper: First, Download Whirr at https://whirr.apache.org/. Then, run:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa_whirr bin/whirr launch-cluster --cluster-name=zookeeper --instance-templates='1 zookeeper' --provider=aws-ec2 --identity=$AWS_ACCESS_KEY_ID --credential=$AWS_SECRET_ACCESS_KEY
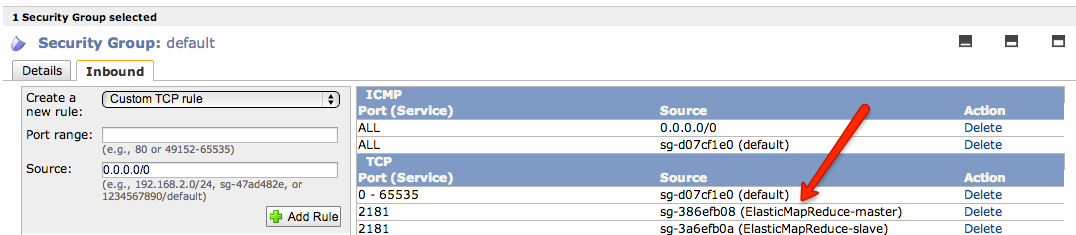
Note: After you have Zookeeper installed, you must ensure that the Zookeeper security group allows traffic from your Amazon EMR master and slave node security groups.
Installing the Amazon EMR Command Line Interface
A popular tool for using Amazon EMR is the Amazon EMR CLI. If you do not have this installed, you can follow the instructions at https://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/emr-cli-install.html
Installing Accumulo
After you have the Amazon EMR Ruby client installed and you have a Zookeeper cluster running, use the following steps to get Accumulo installed on your Amazon EMR nodes.
-
Run the following Amazon EMR CLI command and replace the text in capital letters as follows:
elastic-mapreduce --create --alive --name "Accumulo" --bootstrap-action \ s3://elasticmapreduce/samples/accumulo/accumulo-install.sh \ --args "IP,DBNAME,PASSWORD" --bootstrap-name "install Accumulo" \ --enable-debugging --log-uri s3://BUCKETNAME/accumulo-logs/ \ --instance-type m1.large --instance-count 4 --key-pair KEY
Note: In the GovCloud (US) region the Accumulo script is located in a different S3 bucket so you should instead use s3://us-gov-west-1.elasticmapreduce/samples/accumulo/accumulo-install.sh
IP: IP address of a Zookeeper node
DBNAME: Name of the database that you would like to create in Accumulo
PASSWORD: Accumulo DB password
KEY: Your Amazon EC2 SSH key-pair name
BUCKETNAME: Your Amazon S3 bucket name where the Amazon EMR logs will be uploadedThe Amazon EMR cluster deployment and bootstrapping takes about 5-10min. The above command should have an output similar to the following:
Created job flow j-1XIYVOM2PGH3R
-
Check the status of your Amazon EMR cluster by running the following command:
elastic-mapreduce --list j-1XIYVOM2PGH3R
The output should be similar to the following:
j-1XIYVOM2PGH3R BOOTSTRAPPING ec2-23-22-183-67.compute-1.amazonaws.com Accumulo PENDING Setup Hadoop Debugging
When the put command shows the cluster status as PENDING, you can start using your Amazon EMR cluster.
j-1XIYVOM2PGH3R Waiting ec2-23-22-183-67.compute-1.amazonaws.com Accumulo PENDING Setup Hadoop Debugging
-
After the cluster is ready (with a status of COMPLETED), use SSH to log in to the master node:
ssh hadoop@ec2-23-22-183-67.compute-1.amazonaws.com
-
Run the following Accumulo command after you have logged in. The command requires the DB password from step 1 as input.
accumulo-1.4.2/bin/accumulo shell -u root
If the installation is successful, you should be in the Accumulo shell and able to run Accumulo commands. For more information, see https://accumulo.apache.org/1.4/user_manual/Accumulo_Shell.html.
You can monitor your Accumulo cluster by browsing to the following URL, where masternodehostname is the master node's hostname from step 4: https://masternodehostname:50095.
Other Considerations
- Running Accumulo on EMR requires a well-defined backup strategy. In order to avoid data loss, it is highly recommended that you regularly back up your data to S3 using using EMR's s3distcp or Hadooop's distcp tool.
- In the case of node failure there may be a delay before the data is fully recovered by other healthy nodes. It is important to architect for database recovery delays.