Artificial Intelligence
Introducing Model Server for Apache MXNet
Earlier this week, AWS announced the availability of Model Server for Apache MXNet, an open source component built on top of Apache MXNet for serving deep learning models. Apache MXNet is a fast and scalable training and inference framework with an easy-to-use, concise API for machine learning. With Model Server for Apache MXNet, engineers are now able to serve MXNet models easily, quickly, and at scale.
What is Model Server for Apache MXNet?
Model Server for Apache MXNet (MMS) is an open source component that is designed to simplify the task of deploying deep learning models for inference at scale. Deploying models for inference is not a trivial task. It requires collecting the various model artifacts, setting up a serving stack, initializing and configuring the deep learning framework, exposing an endpoint, emitting real-time metrics, and running custom pre-process and post-process code, to mention just a few of the engineering tasks. While each task might not be overly complex, the overall effort involved in deploying models is significant enough to make the deployment process slow and cumbersome.
With MMS, AWS contributes an open source engineering toolset for Apache MXNet that drastically simplifies the process of deploying deep learning models. Here are the key capabilities you obtain by using MMS for model deployment:
- Tooling to package and export all model artifacts into a single “model archive” file that encapsulates everything required for serving an MXNet model.
- Automated setup of a serving stack, including HTTP inference endpoints, MXNet-based engine, all automatically configured for the specific models being hosted.
- Pre-configured Docker images, set up with NGINX, MXNet, and MMS, for scalable model serving.
- Ability to customize every step in the inference execution pipeline, from model initialization, through pre-processing and inference, up to post-processing the model’s output.
- Real-time operational metrics to monitor the inference service and endpoints, covering latencies, resource utilization, and errors.
- Support for the OpenAPI specifications, which enables easy integration and auto-generation of client code for popular stacks such as Java, JavaScript, C#, and more.
MMS is available to use through a PyPi package, or directly from the Model Server GitHub repository, and it runs on Mac and Linux. For scalable production use cases, we recommend using the pre-configured Docker images that are provided in the MMS GitHub repository.
An example reference architecture is illustrated in the following diagram:
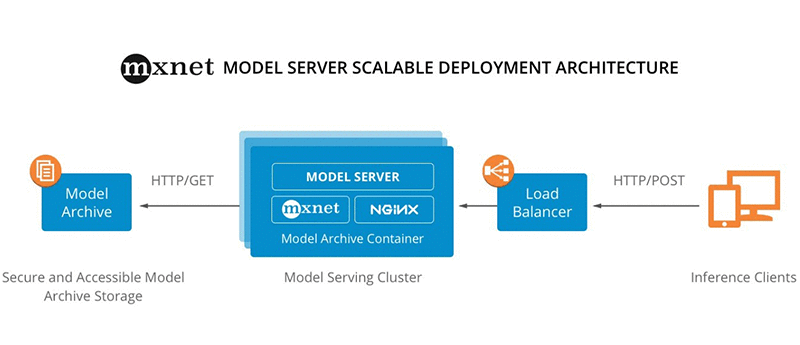
Model Serving Quick Start
Getting started with MMS is easy, as we’ll demonstrate in the following example. This example leverages a pre-trained SqueezeNet v1.1 object detection model that is publicly available in MMS Model Zoo.
To get started, you need Python, which is the only prerequisite for MMS. If you don’t have Python installed, install Python 2.7 or 3.6, following instructions on the Python website.
Next, use PyPi to install MMS on your machine of choice. MMS supports Mac and Linux operating systems.
Serving a model is done by simply running MMS and pointing it at a model archive URL or local file:
After you execute this command, the MMS process will start, download, and unpack the model archive, configure the service with the model artifacts, and start listening for incoming requests over the /squeezenet/predict endpoint on localhost, port 8080 (host and port are configurable).
To test your newly created service, let’s send an inference request over HTTP, asking the model to classify an image:
You will see a response similar to the one that follows, with the model identifying the object in the image to be an “Egyptian cat” with 85% probability. Yay!
To dive deeper into model serving, check out the Server documentation.
Exporting a Model for Serving
MMS serves models packaged in the MMS model archive format. It includes a command line interface mxnet-model-export to package up model artifacts and export a single model archive file. The exported model archive encapsulates all artifacts and meta-data required for serving the model. It’s consumed by MMS when initializing a serving endpoint. No additional model metadata or resources are required for serving.
The following diagram depicts the export process:

As shown in the diagram, the mandatory artifacts required to package up a model archive are the model’s neural network architecture and parameters (layers, operators, and weights), as well as service input and output data type and tensor shape definitions. However, using models in real-world use cases requires more than just the neural network. For example, many vision models require the preprocessing and transformation of input images before they are fed into the model. Another example is classification models that typically require post processing to sort and truncate classification results. To address these requirements, and enable full encapsulation of models into the model archive, MMS can package up custom processing code, as well as any auxiliary file into the archive, and make those files available at runtime. With this powerful mechanism, you can generate model archives that encapsulate a complete processing pipeline: from preprocessing inputs, through customizing inference, and up to applying class label identifiers on the network’s output right before it’s returned to the client over the network.
To learn more about model archive export, check out MMS export Docs.
Learn More and Contribute
MMS was designed for ease of use, flexibility, and scalability. It offers additional capabilities beyond those discussed in this blog post, including serving endpoint configuration, real-time metrics and logging, pre-configured container images, and more.
To learn more about MMS, we recommend starting with our Single Shot MultiBox Detector (SSD) tutorial, which will take you through exporting and serving an SSD model. More examples and additional documentation are available in the repository’s documentation folder.
As we further develop and extend MMS, we welcome community participation through questions, requests, and contributions. Head over to awslabs/mxnet-model-server repository to get started!
Additional Reading
Learn more about AWS and MXNet!
- AWS Contributes to Milestone 1.0 Release of Apache MXNet Including the Addition of a New Model Serving Capability
- Announcing ONNX Support for Apache MXNet
- Distributed Inference Using Apache MXNet and Apache Spark on Amazon EMR
About the Authors
 Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family.
Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family.
 Ruofei Yu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys spending time with friends and family.
Ruofei Yu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys spending time with friends and family.
 Yao Wang is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking, reading and music.
Yao Wang is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking, reading and music.