AWS Partner Network (APN) Blog
Improving Data Extraction Processes Using Amazon Textract and Idexcel
By Durga Sai Eswar, Data Scientist at Idexcel
 |
Manually extracting data from multiple sources is repetitive, error-prone, and can create a bottleneck in the business process.
Idexcel built a solution based on Amazon Textract that improves the accuracy of the data extraction process, reduces processing time, and boosts productivity to increase operational efficiencies. We implemented this solution for a client who needed to automate financial data extraction from unstructured financial documents.
Using our Amazon Textract-based Red-Ex (Redaction-Extraction) solution, a variety of documents can be processed. This includes financial reports, medical records, and tax forms. Our solution is scalable, customizable, and error-free.
Idexcel is an AWS Partner Network (APN) Advanced Consulting Partner with AWS Competencies in DevOps, Migration, and Financial Services. Idexcel is a professional services and technology solutions provider, specializing in cloud, application modernization, and data services.
In this post, I will describe our solution for data extraction and redaction. Specifically, I’ll show you how applying a pre-processing phase to the input phase and post-processing to the output phase provides the best extraction quality with our Red-Ex solution using Amazon Textract.
Pre-Processing the Input of Amazon Textract
Information extraction (IE) is the automated retrieval of the specific data related to a selected topic from structured, unstructured or semi-structured documents. Extracting data from structured documents needs less effort, while the process is more challenging for unstructured or semi-structured categories.
Amazon Textract uses machine learning (ML) models to extracts text more accurately from PDF documents or scanned images. It operates at a higher level than the traditional optical character recognition (OCR) system since it uses the power of ML.
It’s also smart enough to identify key-value pairs (the position of every key and its corresponding values) and identify and gather table information.
Before passing an image to Amazon Textract, we pre-process it. When we receive information in a scanned image or PDF, Idexcel’s solution intuitively interacts with the input information to understand its contents. This helps us produce accurate output.
We replicate the same set of intuitive pre-processing techniques through our testing phase before passing the image or PDF to Amazon Textract for processing.
These pre-processing techniques are:
- Image enhancement
- Thresholding
- Resize and crop
Image Enhancement
As humans, if we do not see a piece of text clearly, we zoom in or try to get closer to understand the context and data provided. In a similar way, we apply a function within our solution to zoom the image automatically before passing it to Amazon Textract. This helps Amazon Textract better understand the information being processed.
Whether the file is a text-based PDF document or a scanned image, we use Python to convert it into an image with a resolution of 300 dots per inch (DPI).
Thresholding
Thresholding is powerful image technique in which unnecessary color channels are removed, resulting in much more clear and visible text. This enables the machine to understand and process text more accurately.
For any scanned PDF image, Idexcel produces the output where the text is black and the background is whitebinarization comes to our rescue by converting the input image to grayscale and applying thresholding techniques.
Among several thresholding techniques, Otsu binarization gives optimized results for financial documents, as it automatically finds the threshold value, as shown below.

Figure 1 – 1040 IRS form.
Resize and Crop
In other instances, financial documents or scanned files have information in only a specific part of the document, the rest of the document is blank. This requires us to crop the document to identify and filter out only the necessary content.
We do this by taking out the pixel sum of each row. We then determine whether the respective column has text or white space. This helps us find the x, y coordinates of the first and last line of the text in an image.
Our solution then draws a contour around the text using those x, y coordinates. Figure 2 shows the original image on the left. On the right is the cropped image with the light green contour around the text.

Figure 2 – Original image on the left, cropped and contoured image on the right.
Idexcel’s solution crops the image to achieve that contour. The final output looks like the image in Figure 3, below after applying binarization.

Figure 3 – Final cropped image.
This approach produces an image with only text as black pixels and the background in white pixels. This pre-processed input simplifies information extraction for Amazon Textract.
Post-Processing the Output of Amazon Textract
We have to use a different process to extract information from non-standard documents than we do for standard documents. Following, we describe the process for each.
Extracting Data from Structured Documents
Generally, standard documents maintain a fixed structure and format. As a result, analysis and processing are straightforward. Tax forms and insurance claim forms, for example, fall into this category. Other documents, such as invoices and purchase orders, are semi-structured documents that don’t follow strict formatting and data input guidelines.
For structured documents, we use Amazon Textract to extract raw text, forms, and tables. It processes these types of documents and provides outcomes with better accuracy.
Let’s go through one use case—an extraction from standard U.S. tax forms. There are three main text components to be considered in these tax forms:
- Form data
- Check boxes
- Tables
Form Data
Amazon Textract extracts form data as key-value pairs. For example, in the following field, Amazon Textract uses Name as the key whose value is John Samuel.
Name: John Samuel
The below code snippet helps to call Amazon Textract Form API to extract key-value pairs
An example of key-value pair block from Amazon Textract Form API response looks as following:
Detected key-value pairs like the one above is stored as a KEY_VALUE_SET block in the Amazon Textract response. This block provides positional information as well, which specifies the top, left, right, and width values of the detected pair.
We can check the confidence score that Amazon Textract provides with each block, as seen the table below. The confidence score indicates the probability that a given prediction is correct.
This table provides you the guideline to evaluate the output using the confidence scores.
| S.No | Confidence Range | Comment |
| 1 | > 95% | No spelling errors |
| 2 | 85% – 95% | Minimal spelling errors |
| 3 | < 80% | Less confident on type of the block and more spelling errors |
For example, in the code block below, we have three results—the first is very accurate which is > 99% confidence score; next is > 85% and has minimal spelling errors; the last has the lowest confidence score < 80% where it failed to detect the content.
Although Amazon Textract is good at detecting key-value pairs in form data, its results are limited by the quality of the input document. Let’s run through a few extraction issues and see how to resolve them by using the information provided by Amazon Textract.
Identifying a Missing ‘key_value’ set
Key-value pairs missing from an Amazon Textract key-value set can be extracted by analyzing line blocks. Since tax forms follow a fixed format, we can prepare a list of keys that need to be extracted.
If Amazon Textract is not able to detect any of those predefined keys, we can parse through line blocks and extract any line block that contains that key. Later, we can extract the corresponding value of that key by using positional information.
Assuming that, there are ‘N’ LINE blocks, we would be searching for the key name in the ‘N’ LINE blocks. If we find the key in ‘LINE block 2′, then we can get the value of the corresponding key using positional information of ‘LINE block 2’.

Figure 4 – Caption goes here.
Handling Spelling Mistakes
At times, Amazon Textract spells certain words in standard forms incorrectly. This can happen if the input document has poor quality. To resolve this, we perform post-processing on the output.
For structured documents, we have a list of the keys that need to be extracted. Using an ML-based sentence similarity measure, we can find the extracted fields that are most similar to our list. To find the correct spelling, we simply select the values that correspond to the most similar keys.
For example, the key ‘Social socuriy gumber’ is misspelled, but has a Levenshtein similarity score of 0.846 to Social Security Number. That is a good indication that its value is precisely what is being looked for. A lower similarity score might not give you the same confidence score.
Besides spelling mistakes, Amazon Textract output may include noise, as well. By using the same list of predefined keys, the noise can be addressed in the same way misspelled words are addressed.
Check Boxes
Checkbox is the method to gather information in standard forms where the user can select one of the available options as answer to a corresponding question. The checkbox can be extracted using the same code snippet as mentioned in the form extraction.
Amazon Textract extracts check boxes as a key-value set. It interprets the question as the key, and the answer (true or false) as its value. In the Amazon Textract output, blocks specifying check boxes are SELECTON_ELEMENT blocks.
We receive positional information of each field from its corresponding block. We also receive the status of a check box (whether it is checked or unchecked) by specifying SelectionStatus as SELECTED or NOT_SELECTED, as shown below.
Missing Check Boxes
We have noticed that sometimes, even if there is a SELECTON_ELEMENT block for some check box fields, Amazon Textract is not able to identify it as a key-value set. To extract those missing check boxes, we parse through all SELECTON_ELEMENT blocks and identify the missing block.
From the bounding box information of each LINE block, we need to specifically search for SELECTION_ELEMENT block within that LINE block region and get the corresponding value. An example code flow for missing checkbox is in the figure below.
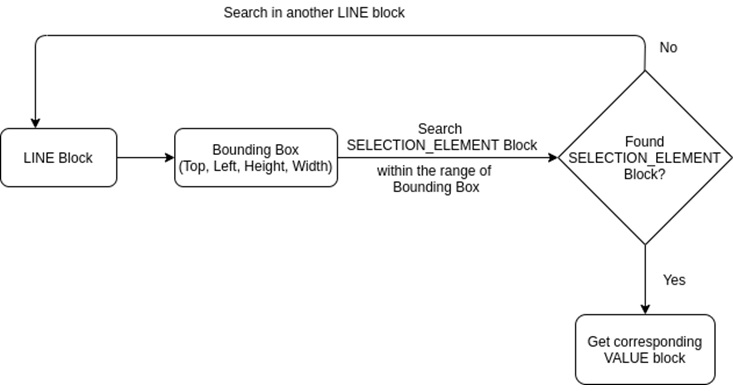
Figure 5 – Caption goes here.
Tables
To extract tables from a tax form, we use the table extraction functionality of Amazon Textract. From table blocks, we get information for each cell. Each cell block provides information such as row_index, column_index, row_span, column_span, as well as positional information.
To extract the table, we simply change the FeatureTypes parameter to ["TABLES"]:
Extracting Data from Unstructured Documents
Unstructured documents are free-form and don’t have a fixed structure and consistency. Contracts, balance sheets, and income statements are some of the most common unstructured documents that we would encounter in the financial industry.
As a prime example, consider balance sheet extraction. Form extraction does not work here, so we must use table extraction.
Since balance sheets do not have a fixed set of fields or a fixed format, Amazon Textract can extract the table information, irrespective of these anomalies. Once the extraction is complete, an ML-based spell checker system identifies words with spelling issues so we can fix them.
Solution Architecture
Idexcel’s solution is deployed as an application wrapped around a user interface (UI). You can also deploy our solution without a UI, as a job that you schedule to run on a new input file in an Amazon Simple Storage Service (Amazon S3) bucket.
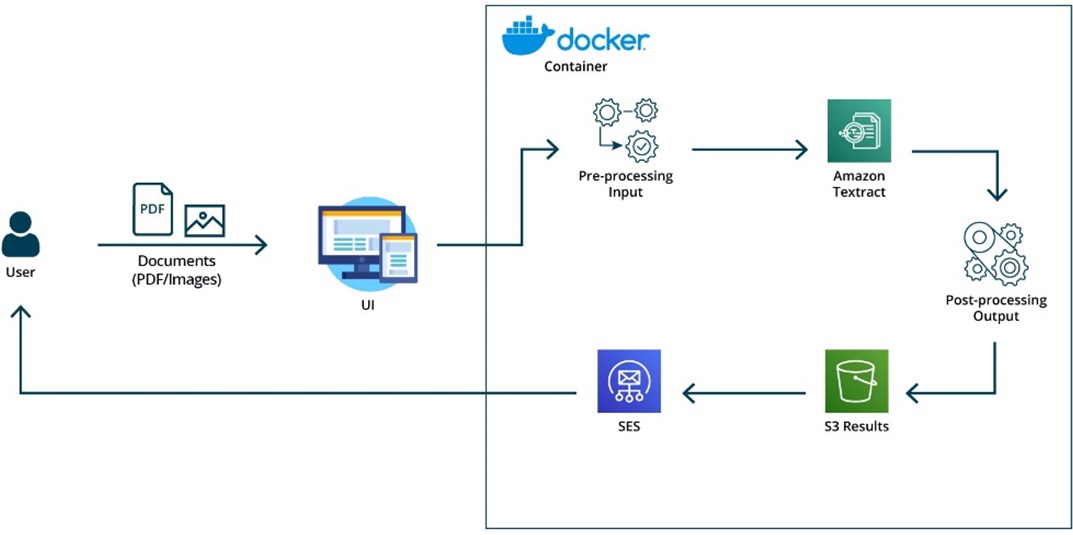
Figure 6 – Architectural diagram of Idexcel’s solution.
This architecture has a UI that invokes a flask API hosted on a Docker container by passing documents (PDF/images). It makes a request to the Amazon Textract API after pre-processing on the input documents, and it does post-processing on the Amazon Textract response.
A quick configuration setup is required before making an API call to Amazon Textract:
In this configuration, ACCESS_KEY, SECRET_KEY, and SESSION_TOKEN are variables that contain access key, secret key, and session token of your AWS account.
Once set up, we can call the analyze_document API with an input document that is stored inside the Docker container.
After receiving a response from Amazon Textract, we do post-processing on it and push the final results to the Amazon S3 bucket.
We send the output to the user through an email using Amazon Simple Email Service (SES). The code snippet below shows how we connect to SES.
Conclusion
With tools like Amazon Textract, we can create applications that can extract text from structured and unstructured documents with tremendous accuracy. We can also build several extensions to our applications by utilizing the output from Amazon Textract.
With this approach, you can solidify your competitive edge, respond faster to market opportunities, and increase your operational efficiency.
Consider these next steps:
- Get started with Amazon Textract using the Developer Guide.
- Implement our proposed solution using Java.
- Access Amazon Textract Code in GitHub.
- Explore more Amazon Textract use cases.
- Download Idexcel’s case study.
- Schedule a two-week free assessment with Idexcel.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Idexcel – APN Partner Spotlight
Idexcel is an AWS Competency Partner. Idexcel is a professional services and technology solutions provider, specializing in cloud, application modernization, and data services.
Contact Idexcel | Practice Overview
*Already worked with Idexcel? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.