AWS Partner Network (APN) Blog
Serverless Containers are the Future of Container Infrastructure
By Tomer Hadassi, Solutions Architecture Team Leader at Spotinst
By Shashi Raina, Partner Solutions Architect at AWS
 |
 |
In an effort to increase system stability, developer productivity, and cost effectiveness, IT and DevOps teams have undergone two major shifts in recent years.
The first was the move from on-premises infrastructure to the cloud. This shift allows companies to remove a significant amount of overhead in managing their technologies while scaling capacity up or down as needed, and adding the flexibility to use a plethora of virtual machine (VM) types, sizes, and pricing models.
The second and more recent shift is the major pivot to containers and serverless solutions, with Kubernetes taking charge and becoming the industry standard for container orchestration.
The combination of these two shifts presents organizations with a unique question: how do you maximize an application’s uptime while maintaining a cost-effective infrastructure at both layers?
Keeping availability high by over-provisioning is easy, but it’s also very expensive. As a result, several challenges have arisen on the path to building an optimized, cost-effective, and highly available containerized infrastructure on Amazon Web Services (AWS):
- Pricing
- Instance sizing
- Containers utilization
In this post, we will explore the Spotinst platform and review how it solves these challenges with Serverless Containers.
Spotinst is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Container Competency. Spotinst helps companies automate cloud infrastructure management and save on their AWS computing costs by leveraging Amazon EC2 Spot Instances with ease and confidence.
Challenges
To make the most cost-effective use of the cloud, users strive to achieve a flexible infrastructure that will scale up or down based on resource requirements such as CPU or memory utilization.
While natively scaling the application layer, Kubernetes does little to manage the underlying infrastructure layer.
As like most container orchestrators, it was designed with a physical data center in mind and assumes the capacity is always available as applications scale up and down.
Let’s take a closer look at the challenges business face when building optimized, cost-effective, and highly available infrastructure on AWS.
Pricing
With three available pricing models on AWS—On-Demand, Reserved, and Spot—we need to decide which model works best for every part of the workload.
Kubernetes does a great job with resilience and handling the interruption or replacement of servers. This makes it a great candidate to leverage Spot instances at a 70 percent discount compared to On-Demand prices.
Then again, it’s important to maintain some persistent instances for certain workloads as well as cost predictability. That’s where buying a pool of Amazon EC2 Reserved Instances (RIs) ensures a baseline capacity that is cost effective.
Instance Sizing
The second and most complex challenge is choosing the right infrastructure size and type to satisfy the actual containers requirements.
Should we stick to one instance type? Should we mix families or instance sizes? What should we do when a GPU-based pod comes up to do a quick job a few times a day?
Traditionally, the answer to all of these questions has been, “It varies.” As time goes on, clusters grow and more developers freely push new and differing containers into Kubernetes, resulting in constantly changing answers to the questions above.
Moreover, we need to figure out how to make sure it all keeps scaling and addressing changes in application requirements. To illustrate this point, consider that some containers require 0.2vCPU and 200MB of memory, and others require 8vCPU and 16GB of memory or more.
As a result, setting the right auto scaling policy based on simple CPU or memory thresholds rarely stays reliable in the long term.
Containers Utilization
The third and least tackled challenge is the containers utilization. This involves constantly adapting the limits and resource requests of the containers based on their consumption and utilization.
Even after solving for the first two issues and successfully using the right instance sizes for our containers, how do we know the container wasn’t over-allocated resources?
Getting a pod of 3.8vCPU and 7.5GB of memory on a c5.xlarge instance is great as it puts the instance at nearly 100 percent allocation, but what if that pod only uses half of that? That would mean half of our instance resources are wasted and could be used by other containers.
Successfully solving for all of these issues can cut costs and free developer time by having infrastructure and containers that self-optimize in real-time based on application demands.
Spotinst Automation Platform
Spotinst built a DevOps automation platform that helps customers save time and money.
The core of the Spotinst platform is a sophisticated infrastructure scheduling mechanism that is data-driven. It allows you to run production-grade workloads on Spot instances, while utilizing a variety of instance types and sizes. Spotinst offers an enterprise-grade SLA on Spot Instances while guaranteeing the full utilization of RIs.
On top of this automation platform, Spotinst built Ocean, a Kubernetes pod-driven auto scaling and monitoring service. Ocean automatically and in real-time solves the challenges we discussed earlier, while creating a serverless experience inside your AWS environment, and it does so without any access to your data.
Additionally, Ocean helps you right-size the pods in your cluster for optimal resource utilization.
Spotinst solves the pricing and instance sizing challenges by using dynamic container-driven auto scaling based on flexible instance size and life cycles.
There are three main components at play here: dynamic infrastructure scaling, pod rescheduling simulations, and cluster headroom. This is how they work.
Dynamic Infrastructure Scaling
Spotinst Ocean allows customers to run On-Demand, Spot, and Reserved Instances of all types and sizes within a single cluster. This flexibility means the right instance can be provisioned when it’s needed, while guaranteeing minimum resource waste.
Whenever the Kubernetes Horizontal Pod Autoscaler (HPA) scales up, or a new deployment happens, the Ocean auto scaler reads the overall requirements of that event. These include:
- CPU reservation
- Memory reservation
- GPU request
- ENI limitations
- Pod labels, taints, and tolerations
- Custom labels (instance selectors, on-demand request)
- Persistent volume claims
After aggregating the sum of these requests, Ocean calculates the most cost-effective infrastructure to answer the request. This can be anywhere from a single t2.small to a combination of several M5.2xlarge, C5.18xlarge, P3.xlarge, R4.large, or anything in between.
The use of dynamic instance families and sizes helps gain a highly defragmented with high resource allocation cluster as it grows and scales up.
Pod Rescheduling Simulations
This dynamic infrastructure scaling ensures maximum resource allocation as we scale up and grow our clusters.
To make sure the allocation is maintained when Kubernetes scales the pods down as application demands decrease, Ocean runs pod rescheduling simulations every 60 seconds to figure out if the cluster can be further defragmented.
By considering all the requirements, Ocean checks for any expendable nodes. These can have their pods drained and the node removed from the cluster without having any of the pods go into a pending state, and get scheduled to other existing nodes in the cluster.
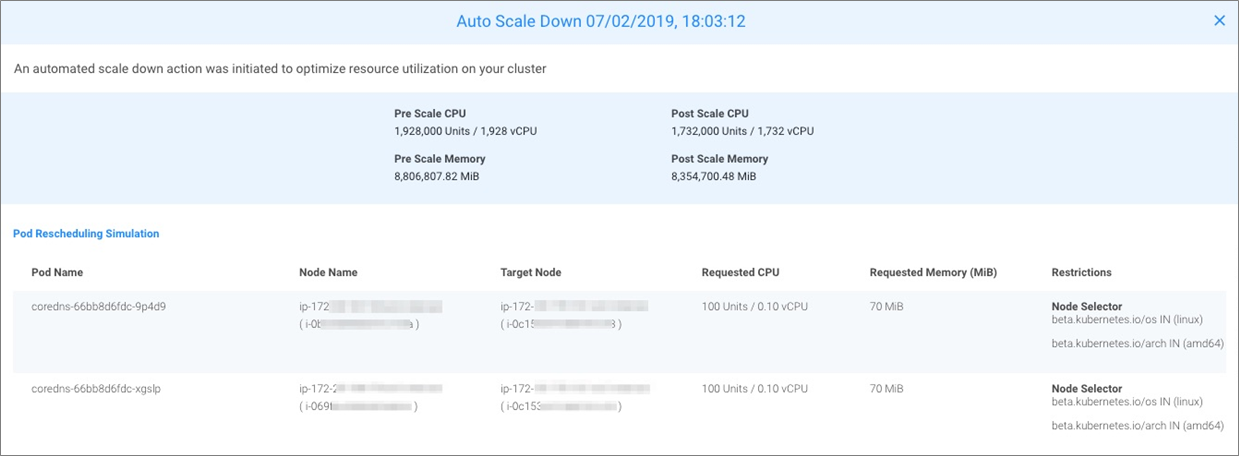
Figure 1 – Pod rescheduling simulation.
In Figure 1, you can see the pod rescheduling simulation when scaling down expendable nodes, considering pod and instance resources as well as other restrictions. In this example, we were able to reduce the cluster size by about 10 percent pre-scale versus post-scale CPU and memory.
Cluster Headroom
Scaling the infrastructure when it’s needed can achieve maximal node resource allocation, but may also slow the responsiveness of our application.
While high availability is critical, waiting for new nodes to spin up every time capacity is needed can lead to less-than-optimal latency and other performance issues. This is where the cluster headroom comes in. Headroom is a capacity of available units of work in the sizes of the most common deployments that stay available in order to allow Kubernetes to instantly schedule new pods.
Headroom is automatically configured by Ocean based on the size of each deployment in the cluster, and changes dynamically over time.
In practice, effective headroom means that more than 90 percent of scaling events in Kubernetes instantly get scheduled on the cluster into the headroom capacity, combined with a call for a headroom scaling event to be prepared for the next time Kubernetes scales.
In case an abnormal deployment happens that requires more than the available headroom, the cluster auto scaler handles the scaling events with a single scaling event of varying instance types and sizes to cover the entire deployment resource requirements. This helps Ocean achieve a 90 percent resource allocation in the cluster while staying more responsive than a traditional step scaling policy.
Monitoring CPU and Memory Utilization
Once the pods are placed on the instances, the Ocean Pod Right-Sizing mechanism will start monitoring the pods for CPU and memory utilization. Once enough data is aggregated, Ocean starts pushing recommendations on how to right-size the pod.
For example, if a pod was allocated with 4GB of memory and over a few days its usage is between 2GB and 3.4GB , with an average of 2.9GB, Ocean Right-Sizing will recommend sizing the pod at ~3.4GB, which further helps bin pack and defragment the cluster while keeping it highly utilized.
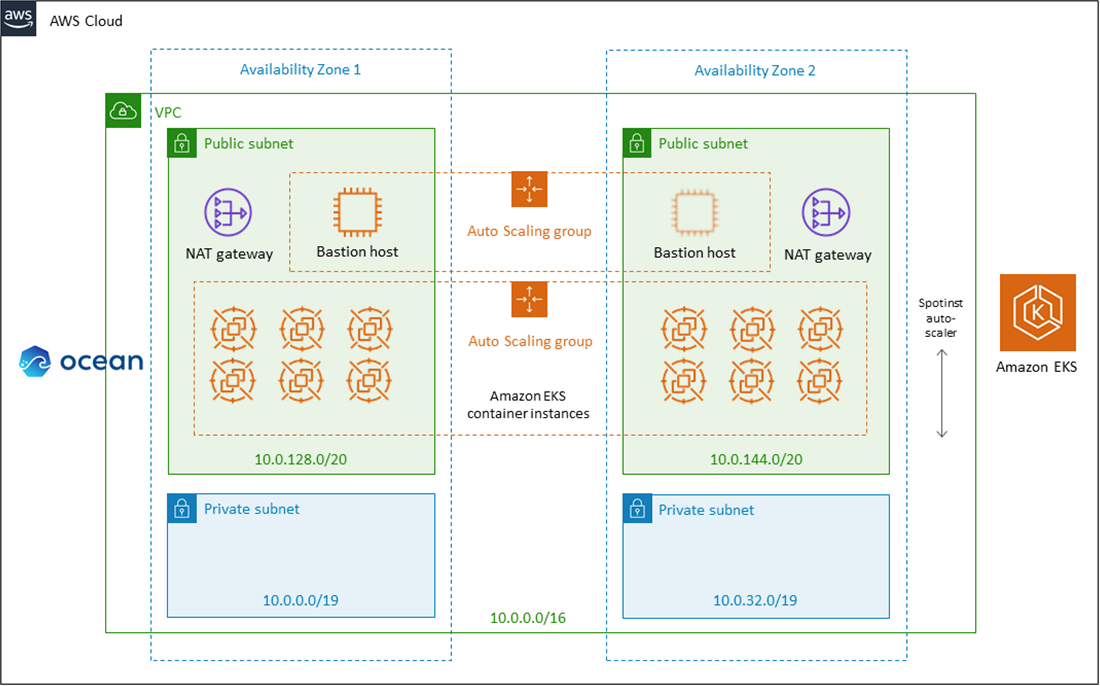
Figure 2 – Deployment with Amazon EKS best practices.
In Figure 2, you can see the deployment architecture of Ocean + Amazon Elastic Kubernetes Service (Amazon EKS) where EKS managed the Kubernetes control pane and Ocean the worker nodes. The Amazon EKS architecture and security stays in place, and Ocean wraps around the worker nodes to dynamically orchestrate them.
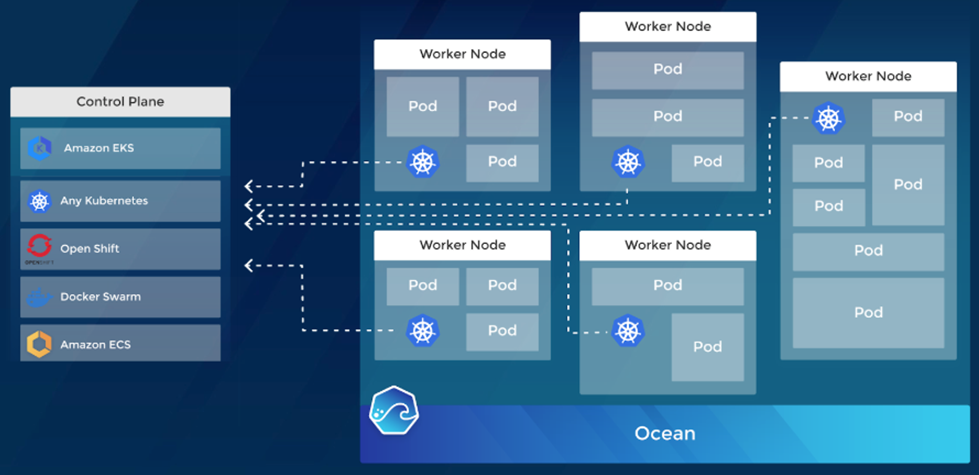
Figure 3 – Deployment with any container orchestrator on AWS.
In Figure 3, you see the general Ocean architecture with the worker nodes connecting to one of the supported container orchestrators. On the left side, you can see the variety of container management control planes and on the right, Ocean wrapping around the worker nodes.
Implementation Walkthrough
Deploying Spotinst Ocean for your existing Kubernetes implementation is simple and can be done in just a few minutes using your preferred deployment method, such as Amazon CloudFormation, Terraform, Ansible, RESTful API, or the Spotinst UI.
Ocean orchestrates within your AWS environment and leverages existing cluster components, including virtual private clouds (VPC), subnets, AWS Identity and Access Management (IAM) roles, images, security groups, instance profiles, key pairs, user data, and tags.
In a nutshell, Ocean will fetch all of the existing configurations from your cluster to build the configuration for the worker nodes that it will spin up. Then, all you have to do is deploy the Spotinst Kubernetes Cluster Controller into your cluster so that Ocean can get the Kubernetes metrics reported to it.
Once this is done, Ocean will handle all infrastructure provisioning for you going forward. You should be able to give your developers complete freedom to deploy whatever they choose.
Let’s walk through a set up so you can see how simple it is.
- First, navigate on the left to Ocean > Cloud Clusters, and then choose Create Cluster.
- On the next screen, choose to either join an existing cluster or create a new one.
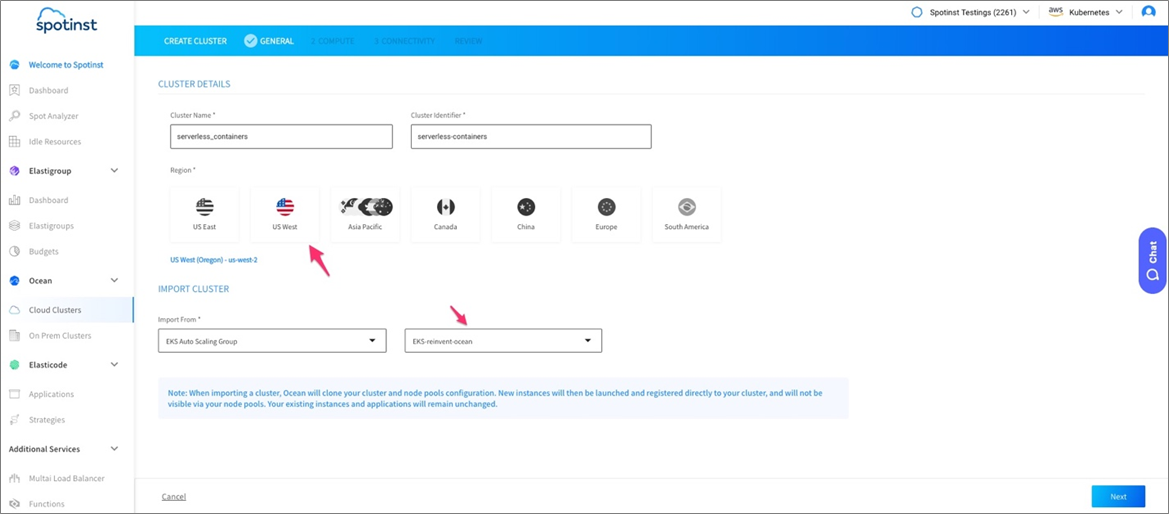
- In the General tab, choose the cluster name, region and Auto Scaling Group to import the worker nodes configurations from.
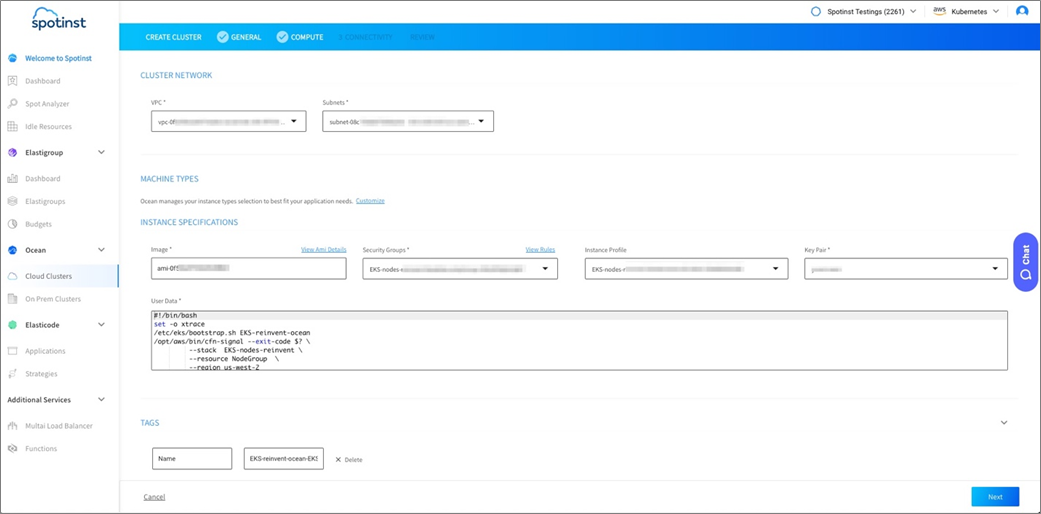
- On the Configuration page, verify that all of your configurations were imported and click Next.
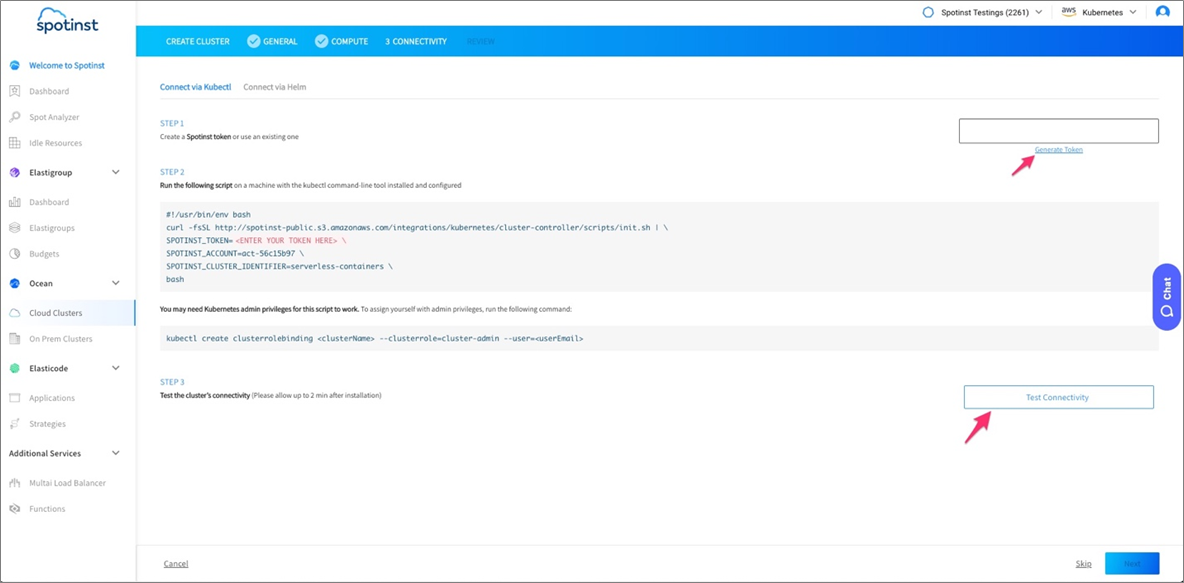
- To install the controller, generate a token in Step 1 of the wizard and run the script provided in Step 2. Wait two minutes and test connectivity; a green arrow will appear.
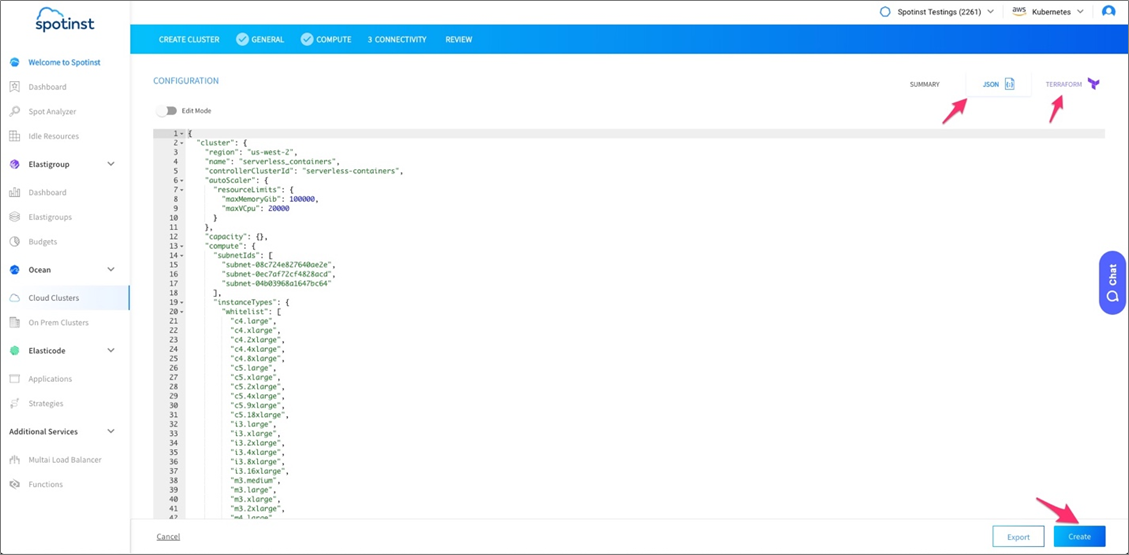
- On the summary page, you can see the JSON configuration of the cluster, and get a Terraform template populated with all of the cluster’s configurations.
. - Once reviewed, create the cluster and Ocean will handle and optimize your infrastructure going forward.
Optimization Data
Now that we know what Ocean is and how to deploy it, let’s look at some of the numbers and benefits of real usage scenarios, and how using dynamic infrastructure can help.
Example #1: Pod requires 6,500mb of memory and 1.5vCPUs – Different Instance Size
Running five such pods on m5.large or m5.xlarge instances will cost $0.096 per hour per pod. However, going up to 2XL will allow further bin-packing and reduce the cost to $0.077 per hour per pod.

As seen in the chart above, by going a few sizes up, we can achieve better resource allocation and reduce the cost by 20 percent.
Example #2: Pod of 6500mb of memory and 1.8vCPUs – Different Instance Family
Running replicas of such pods on c5.xlarge will only allow for one pod per instance, while an m5.xlarge will allow for two and reduce the cost from $0.17 per hour per pod to $0.096 per hour per pod.

As seen in the chart above, by changing instance family, we can achieve better resource allocation and reduce the cost by 43 percent.
Conclusion
To summarize, when running a Kubernetes cluster on AWS there are three main challenges in cost optimization and availability that Spotinst Ocean helps automate and solve.
- Pricing model: Spotinst Ocean automatically gets you to 100 percent Reserved Instance coverage to preserve your investment and leverages cost effective Spot instances beyond that.
- Instance sizing: Using its container driven auto scaler, Ocean spins up the right instance at the right time based on pod requirements, so you no longer have to deal with it.
- Containers utilization: Ocean monitors your containers utilization and how to right-size them and avoid idle resources.
With all of this overhead out of the way, managing Kubernetes clusters on AWS is easier than ever. If you’re new to Kubernetes, check out the Amazon EKS + Spotinst Ocean Quick Start.
If you’re already running a Kubernetes cluster on AWS, sign up for Spotinst for free.
.

Spotinst – APN Partner Spotlight
Spotinst is an APN Advanced Technology Partner. They help companies automate cloud infrastructure management and save on their AWS computing costs by leveraging Amazon EC2 Spot Instances with ease and confidence.
Contact Spotinst | Solution Overview | AWS Marketplace
*Already worked with Spotinst? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.