AWS Architecture Blog
Building a Serverless FHIR Interface on AWS
Technology is revolutionizing the healthcare industry but it can be a challenge for healthcare providers to take full advantage because of software systems that don’t easily communicate with each other. A single patient visit involves multiple systems such as practice management, electronic health records, and billing. When these systems can’t operate together, it’s harder to leverage them to improve patient care.
To help make it easier to exchange data between these systems, Health Level Seven International (HL7) developed the Fast Healthcare Interoperability Resources (FHIR), an interoperability standard for the electronic exchange of healthcare information. In this post, I will show you the AWS services you use to build a serverless FHIR interface on the cloud.
In FHIR, resources are your basic building blocks. A resource is an exchangeable piece of content that has a common way to define and represent it, a set of common metadata, and a human readable part. Each resource type has the same set of operations, called interactions, that you use to manage the resources in a granular fashion. For more information, see the FHIR overview.
FHIR Serverless Architecture
My FHIR architecture features a server with its own data repository and a simple consumer application that displays Patient and Observation data. To make it easier to build, my server only supports the JSON content type over HTTPs, and it only supports the Bundle, Patient, and Observation FHIR resource types. In a production environment, your server should support all resource types.
For this architecture, the server supports the following interactions:
- Posting bundles as collections of Patients and Observations
- Searching Patients and Observations
- Updating and reading Patients
- Creating a CapabilityStatement
You can expand this architecture to support all FHIR resource types, interactions, and data formats.
The following diagram shows how the described services work together to create a serverless FHIR messaging interface.
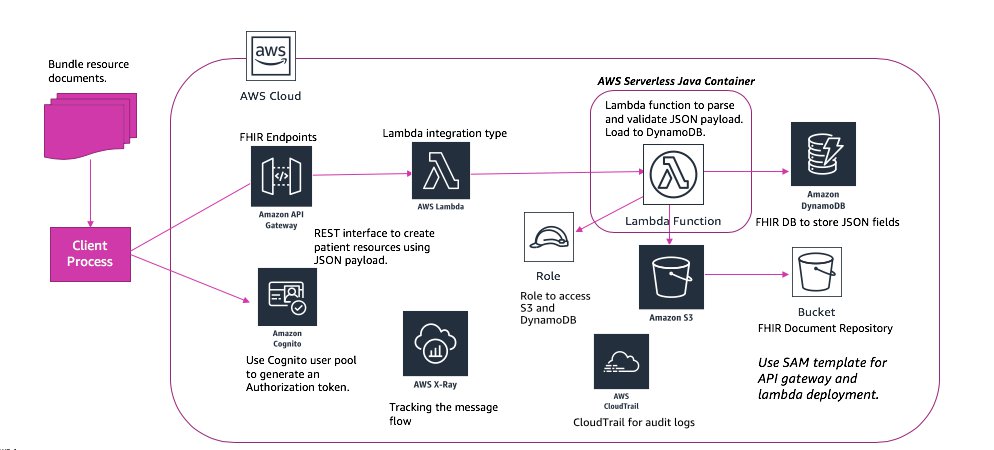
Amazon API Gateway
In Amazon API Gateway, you create the REST API that acts as a “front door” for the consumer application to access the data and business logic of this architecture. I used API Gateway to host the API endpoints. I created the resource definitions and API methods in the API Gateway.
For this architecture, the FHIR resources map to the resource definitions in API Gateway. The Bundle FHIR resource type maps to the Bundle API Gateway resource. The observation FHIR resource type maps to the observation API Gateway resource. And, the Patient FHIR resource type maps to the Patient API Gateway resource.
To keep the API definitions simple, I used the ANY method. The ANY method handles the various URL mappings in the AWS Lambda code, and uses Lambda proxy integration to send requests to the Lambda function.
You can use the ANY method to handle HTTP methods, such as:
- POST to represent the interaction to create a Patient resource type
- GET to read a Patient instance based on a patient ID, or to search based on predefined parameters
We chose Amazon DynamoDB because it provides the input data representation and query patterns necessary for a FHIR data repository. For this architecture, each resource type is stored in its own Amazon DynamoDB table. Metadata for resources stored in the repository is also stored in its own table.
We set up global secondary indexes on the patient and observations tables in order to perform searches and retrieve observations for a patient. In this architecture, the patient id is stored as a patient reference id in the observation table. The patientRefid-index allows you to retrieve observations based on the patient id without performing a full scan of the table.


We chose Amazon S3 to store archived FHIR messages because of its low cost and high durability.
Processing FHIR Messages
Each Amazon API Gateway request in this architecture is backed by an AWS Lambda function containing the Jersey RESTful web services framework, the AWS serverless Java container framework, and the HAPI FHIR library.
The AWS serverless Java framework provides a base implementation for the handleRequest method in LambdaHandler class. It uses the serverless Java container initialized in the global scope to proxy requests to our jersey application.
The handler method calls a proxy class and passes the stream classes along with the context.
This source code from the LambdaHandler class shows the handleRequest method:
// Main entry point of the Lambda function, uses the serverless-java-container initialized in the global scope
// to proxy requests to our jersey application
public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context)
throws IOException {
handler.proxyStream(inputStream, outputStream, context);
// just in case it wasn't closed by the map per
outputStream.close();
}
The resource implementations classes are in the com.amazonaws.lab.resources package. This package defines the URL mappings necessary for routing the REST API calls.
The following method from the PatientResource class implements the GET patient interaction based on a patient id. The annotations describe the HTTP method called, as well as the path that is used to make the call. This method is invoked when a request is sent with the URL pattern: Patient/{id}. It retrieves the Patient resource type based on the id sent as part of the URL.
@GET
@Path("/{id}")
public Response gETPatientid(@Context SecurityContext securityContext,
@ApiParam(value = "", required = true) @PathParam("id") String id, @HeaderParam("Accept") String accepted) {
…
}
Deploying the FHIR Interface
To deploy the resources for this architecture, we used an AWS Serverless Application Model (SAM) template. During deployment, SAM templates are expanded and transformed into AWS CloudFormation syntax. The template launches and configures all the services that make up the architecture.
Building the Consumer Application
For out architecture, we wrote a simple Node.JS client application that calls the APIs on FHIR server to get a list of patients and related observations. You can build more advanced applications for this architecture. For example, you could build a patient-focused application that displays vitals and immunization charts. Or, you could build a backend/mid-tier application that consumes a large number of messages and transforms them for downstream analytics.
This is the code we used to get the token from Amazon Cognito:
token = authcognito.token();
//Setting url to call FHIR server
var options = {
url: "https://<FHIR SERVER>",
host: "FHIR SERVER",
path: "Prod/Patient",
method: "GET",
headers: {
"Content-Type": "application/json",
"Authorization": token
}
}
This is the code we used to call the FHIR server:
request(options, function(err, response, body) {
if (err) {
console.log("In error ");
console.log(err);
}
else {
let patientlist = JSON.parse(body);
console.log(patientlist);
res.json(patientlist["entry"]);
}
});
We used AWS CloudTrail and AWS X-Ray for logging and debugging.
The screenshots below display the results:


Conclusion
In this post, we demonstrated how to build a serverless FHIR architecture. We used Amazon API Gateway and AWS Lambda to ingest and process FHIR resources, and Amazon DynamoDB and Amazon S3 to provide a repository for the resources. Amazon Cognito provides secure access to the API Gateway. We also showed you how to build a simple consumer application that displays patient and observation data. You can modify this architecture for your individual use case.
Final note:
Review the source code and link FHIR with Comprehend Medical on GitHub.