AWS Architecture Blog
Serving Billions of Ads in Just 100 ms Using Amazon Elasticache (Redis OSS)
This post was co-written with Lucas Ceballos, CTO of Smadex
Introduction
Showing ads may seem to be a simple task, but it’s not. Showing the right ad to the right user is an incredibly complex challenge that involves multiple disciplines such as artificial intelligence, data science, and software engineering. Doing it one million times per second with a 100-ms constraint is even harder.
In the ad-tech business, speed and infrastructure costs are the keys to success. The less the final user waits for an ad, the higher the probability of that user clicking on the ad. Doing that while keeping infrastructure costs under control is crucial for business profitability.
About Smadex
Smadex is the leading mobile-first programmatic advertising platform specifically built to deliver best user acquisition performance and complete transparency.
Its Demand Side Platform (DSP) technology provides advertisers with the tools they need to achieve their goals and ROI, with measurable results from web forms, post-app install events, store visits, and sales.
Smadex advertising architecture
What does showing ads look like under the hood? At Smadex, our technology works based on the OpenRTB (Real-Time Bidding) protocol.
RTB is a means by which advertising inventory is bought and sold on a per-impression basis, via programmatic instantaneous auction, which is similar to financial markets.
To show ads, we participate in auctions deciding in real time which ad to show and how much to bid trying to optimize the cost of every impression.
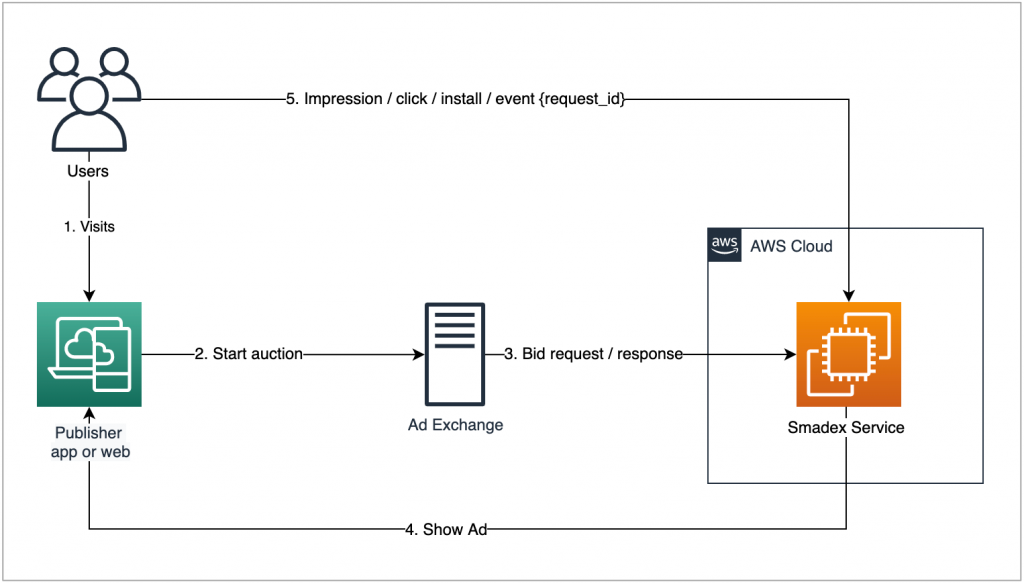
- The final user browses the publisher’s website or app.
- Ad-exchange is called to start a new auction.
- Smadex receives the bid request and has to decide which ad to show and how much to offer in just 100 ms (and this is happening one million times per second).
- If Smadex won the auction, the ad must be sent and rendered on the publisher’s website or app.
- In the end, the user interacts with the ad sending new requests and events to Smadex platform.
Flow of data
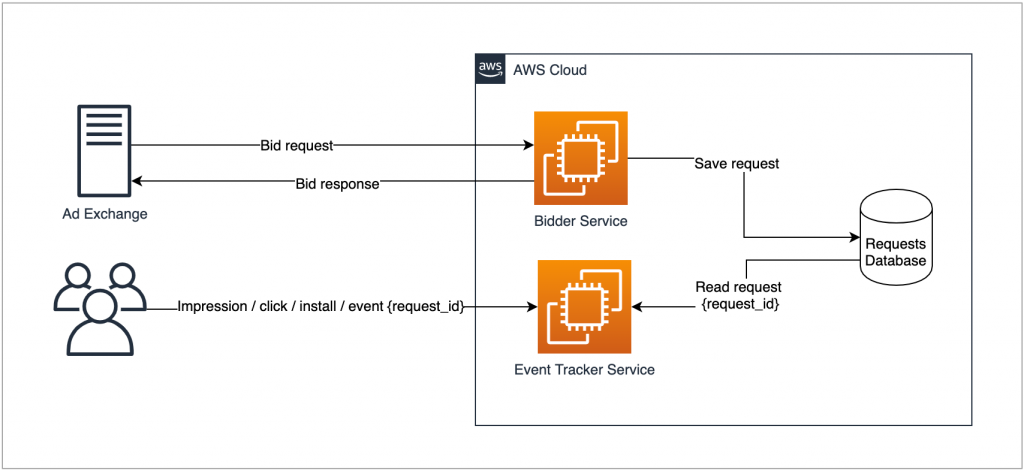
As you can see in the previous diagram, showing ads is just one part of the challenge. After the ad is shown, the final user interacts with it in multiple ways, such as clicking it, installing an application, subscribing to a service, etc. This happens during a determined period that we call the “attribution window.” All of those interactions must be tracked and linked to the original bid transaction (using the request_id parameter).
Doing this is complicated: billions of bid transactions must be stored and available so that they can be quickly accessed every time the user interacts with the ad. The longer we store the transactions, the longer we can “wait” for an interaction to take place, and the better for our business and our clients, too.
Challenge #1: Cost
The challenge is: What kind of database can store billions of records per day, with at least a 30-day retention capacity (attribution window), be accessed by key-value, and all by spending as little as possible?
The answer is…none! Based on our research, all the available options that met the technical requirements were way out of our budget.
So…how to solve it? Here is when creativity and the combination of different AWS services comes into place.
We started to analyze the time dispersion of the events trying to find some clues. The interesting thing we spotted was that 90% of what we call “post-bid events” (impression, click, install, etc.) happened within one hour after the auction took place.
That means that we can process 90% of post-bid events by storing just one hour of bids.
Under our current workload, in one hour we participate in approximately 3.7 billion auctions generating 100 million bid records of an average 600 bytes each. This adds up to 55 gigabytes per hour, an easier amount of data to process.
Instead of thinking about one single database to store all the bid requests, we decided to split bids into two different categories:
- Hot Bid: A request that took place within the last hour (small amount and frequently accessed)
- Cold Bid: A request that took place more than our hour ago (huge amount and infrequently accessed)
Amazon ElastiCache (Redis OSS) is the best option to store 55 GB of data in memory, which gives us the ability to query in a key-value way with the lowest possible latency.
Hot Bids flow

- Every new bid is a hot bid by definition so it’s going to be stored in the hot bids Redis OSS cluster.
- At the moment of the user interaction with the ad, the Smadex tracker component receives an HTTPS notification, including the bid request UUID that originated it.
- Based on the date of occurrence extracted from the received UUID, the tracker component can determine if it’s looking for a hot bid or not. If it’s a hot bid, the tracker reads it directly from Redis performing a key-value lookup query.
It’s been easy so far but what to do with the other 29 days and 23 hours we need to store?
Challenge #2: Performance
As we previously mentioned, cold bids are a huge infrequently accessed number of records with only 10% of post-bid events pointing to them. That sounds like a good use case for an inexpensive and slower data store like Amazon S3.
Thanks to the S3 low-cost storage prices combined with the ability to query S3 objects directly using Amazon Athena, we were able to optimize our costs by storing and querying cold bids by implementing a serverless architecture.
Cold Bids Flow
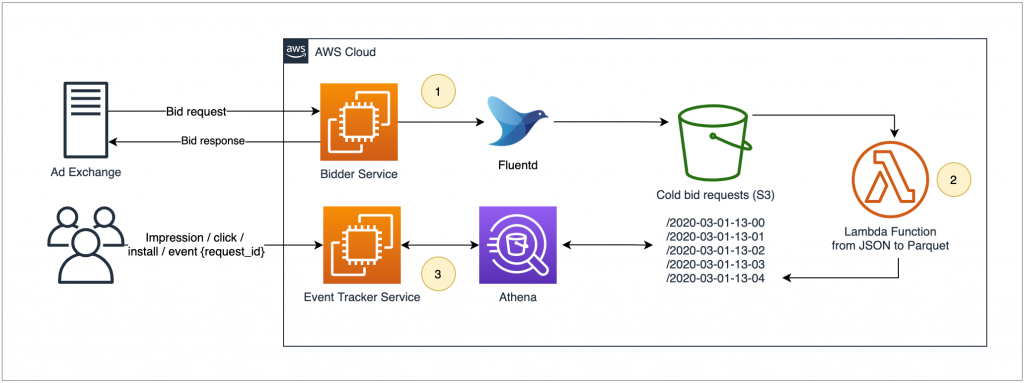
- Incoming bids are buffered by Fluentd and flushed to S3 every one minute in JSON format. Every single file flushed to S3 contains all the bids processed by a specific EC2 instance for one minute.
- An AWS Lambda function is automatically triggered on every new PutObject event from S3. This function transforms the JSON records to Parquet format and will save it back the S3 bucket, but this time into a specific partition folder based on file creation timestamp.
- As seen on the hot bids flow, the tracker component will determine if it’s looking for a hot or a cold bid based on the extracted timestamp of the request UUID. In this case, the cold bid will be retrieved by running an Amazon Athena look-up query leveraging the use of partitions and Parquet format to reduce as much as possible the latency and data that needs to be scanned.
Conclusion
Thanks to this combined approach using different technologies and a variety of AWS services we were able to extend our attribution window from 30 to 90 days while reducing the infrastructure costs by 45%.