AWS News Blog
AWS Lake Formation – Now Generally Available

|
As soon as companies started to have data in digital format, it was possible for them to build a data warehouse, collecting data from their operational systems, such as Customer relationship management (CRM) and Enterprise resource planning (ERP) systems, and use this information to support their business decisions.
The reduction in costs of storage, together with an even greater reduction in complexity for managing large quantities of data, made possible by services such as Amazon S3, has allowed companies to retain more information, including raw data that is not structured, such as logs, images, video, and scanned documents.
This is the idea of a data lake: to store all your data in one, centralized repository, at any scale. We are seeing this approach with customers like Netflix, Zillow, NASDAQ, Yelp, iRobot, FINRA, and Lyft. They can run their analytics on this larger dataset, from simple aggregations to complex machine learning algorithms, to better discover patterns in their data and understand their business.
Last year at re:Invent we introduced in preview AWS Lake Formation, a service that makes it easy to ingest, clean, catalog, transform, and secure your data and make it available for analytics and machine learning. I am happy to share that Lake Formation is generally available today!
With Lake Formation you have a central console to manage your data lake, for example to configure the jobs that move data from multiple sources, such as databases and logs, to your data lake. Having such a large and diversified amount of data makes configuring the right access permission also critical. You can secure access to metadata in the Glue Data Catalog and data stored in S3 using a single set of granular data access policies defined in Lake Formation. These policies allow you to define table and column-level data access.
One thing I like the most of Lake Formation is that it works with your data already in S3! You can easily register your existing data with Lake Formation, and you don’t need to change existing processes loading your data to S3. Since data remains in your account, you have full control.
You can also use Glue ML Transforms to easily deduplicate your data. Deduplication is important to reduce the amount of storage you need, but also to make analyzing your data more efficient because you don’t have neither the overhead nor the possible confusion of looking at the same data twice. This problem is trivial if duplicate records can be identified by a unique key, but becomes very challenging when you have to do a “fuzzy match”. A similar approach can be used for record linkage, that is when you are looking for similar items in different tables, for example to do a “fuzzy join” of two databases that do not share a unique key.
In this way, implementing a data lake from scratch is much faster, and managing a data lake is much easier, making these technologies available to more customers.
Creating a Data Lake
Let’s build a data lake using the Lake Formation console. First I register the S3 buckets that are going to be part of my data lake. Then I create a database and grant permission to the IAM users and roles that I am going to use to manage my data lake. The database is registered in the Glue Data Catalog and holds the metadata required to analyze the raw data, such as the structure of the tables that are going to be automatically generated during data ingestion.
Managing permissions is one of the most complex tasks for a data lake. Consider for example the huge amount of data that can be part of it, the sensitive, mission-critical nature of some of the data, and the different structured, semi-structured, and unstructured formats in which data can reside. Lake Formation makes it easier with a central location where you can give IAM users, roles, groups, and Active Directory users (via federation) access to databases, tables, optionally allowing or denying access to specific columns within a table.
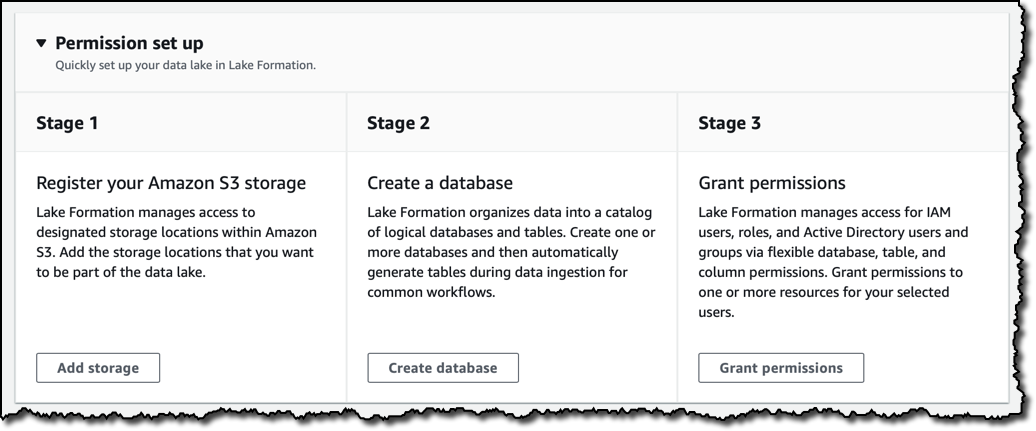
The Glue and Lake Formation Data Catalogs are one and the same to allow customers to migrate without having to move data. To allow this, the Data Catalog now supports a dual permissions model: the existing one based on IAM policies and the new one based on Lake Formation fine-grained permissions.
In this walkthrough I am using Lake Formation permissions and its recommended defaults. To take advantage of Lake Formation permissions, you need to explicitly configure your AWS account:
- If you never used the Glue Data Catalog before, you need to configure the Data Catalog to disable the grant “All To Everyone” settings for new databases and tables.
- If you have an existing Glue Data Catalog, you should upgrade Glue Data Permissions to the AWS Lake Formation Model. As a part of the upgrade process, you may need to update your existing automation tools, like scripts that create new databases or tables, to use the new permission model.
To simplify data ingestion, I can use blueprints that create the necessary workflows, crawlers and jobs on AWS Glue for common use cases. Workflows enable orchestration of your data loading workloads by building dependencies between Glue entities, such as triggers, crawlers and jobs, and allow you to track visually the status of the different nodes in the workflows on the console, making it easier to monitor progress and troubleshoot issues.
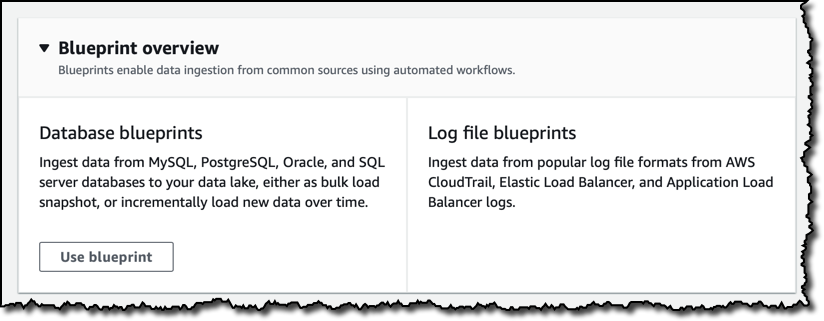
Database blueprints help load data from operational databases. For example, if you have an e-commerce website, you can ingest all your orders in your data lake. You can load a full snapshot from an existing database, or incrementally load new data. In case of an incremental load, you can select a table and one or more of its columns as bookmark keys (for example, a timestamp in your orders) to determine previously imported data.
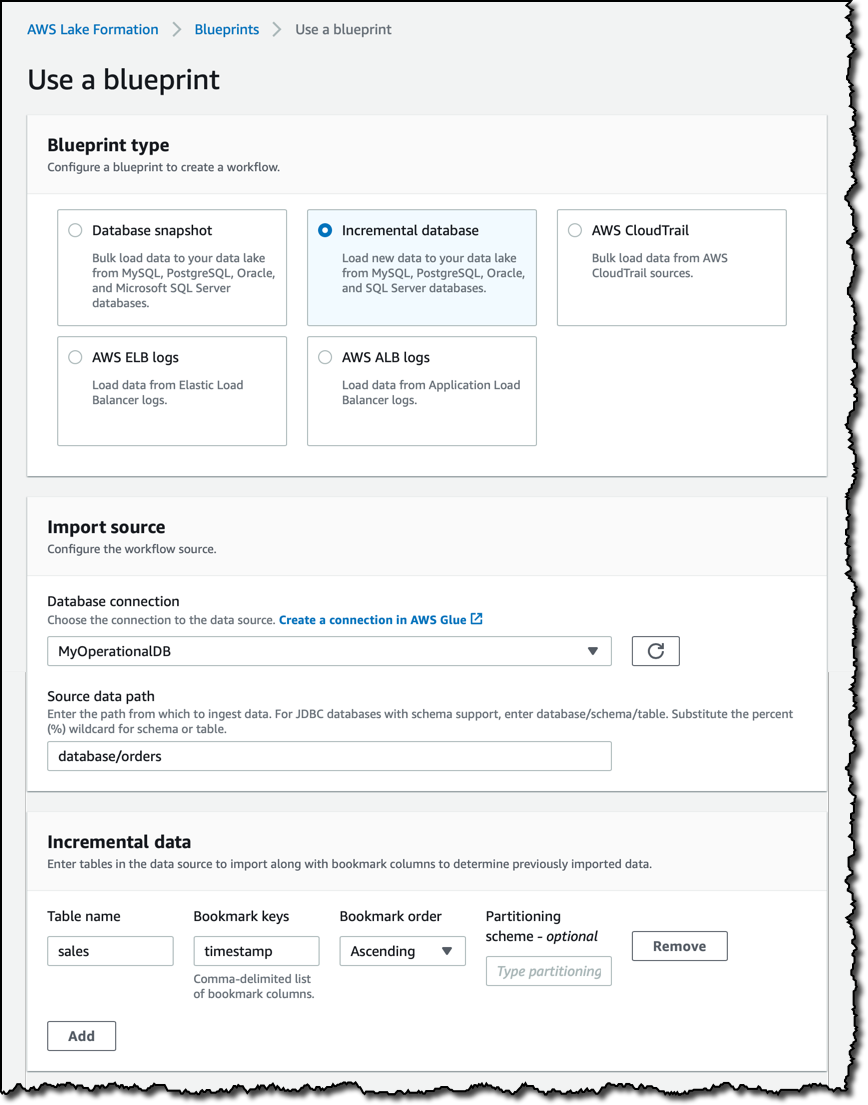
Log file blueprints simplify ingesting logging formats used by Application Load Balancers, Elastic Load Balancers, and AWS CloudTrail. Let’s see how that works more in depth.
Security is always a top priority, and I want to be able to have a forensic log of all management operations across my account, so I choose the CloudTrail blueprint. As source, I select a trail collecting my CloudTrail logs from all regions into an S3 bucket. In this way, I’ll be able to query account activity across all my AWS infrastructure. This works similarly for a larger organization having multiple AWS accounts: they just need, when configuring the trail in the CloudTrial console, to apply the trail to their whole organization.
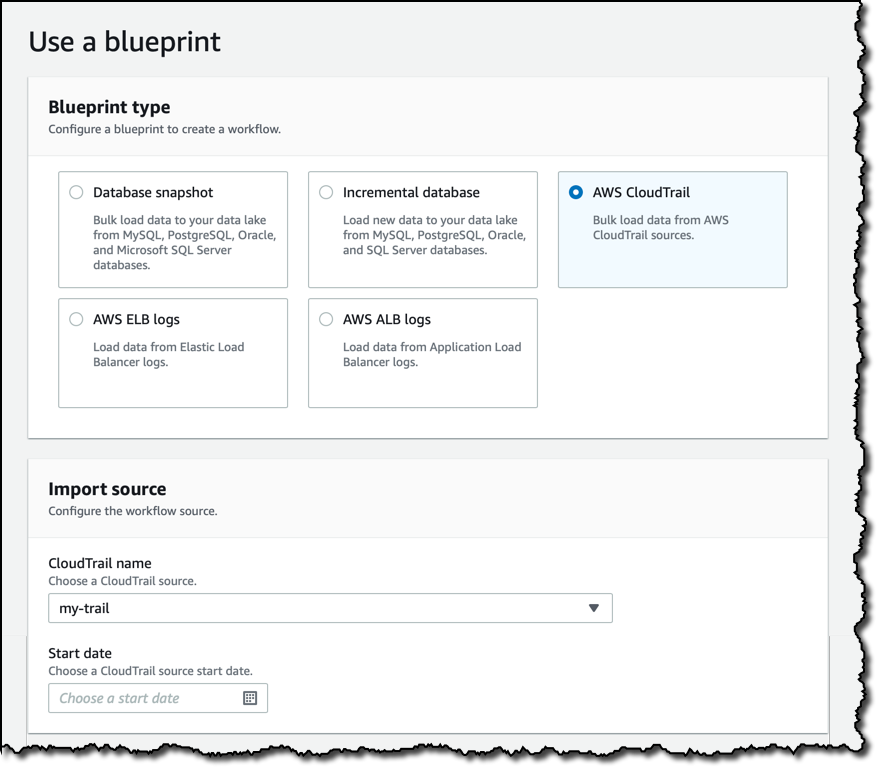
I then select the target database, and the S3 location for the data lake. As data format I use Parquet, a columnar storage format that will make querying the data faster and cheaper. The import frequency can be hourly to monthly, with the option to choose the day of the week and the time. For now, I want to run the workflow on demand. I can do that from the console or programmatically, for example using any AWS SDK or the AWS Command Line Interface (CLI).
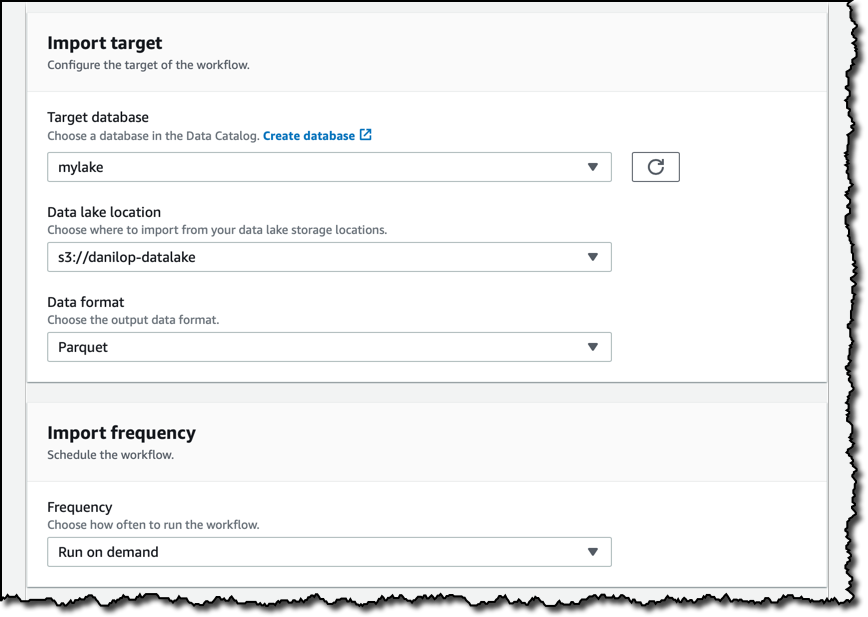
Finally, I give the workflow a name, the IAM role to use during execution, and a prefix for the tables that will be automatically created by this workflow.
I start the workflow from the Lake Formation console and select to view the workflow graph. This opens the AWS Glue console, where I can visually see the steps of the workflow and monitor the progress of this run.

When the workflow is completed a new table is available in my data lake database. The source data remain as logs in the S3 bucket output of CloudTrail, but now I have them consolidated, in Parquet format and partitioned by date, in my data lake S3 location. To optimize costs, I can set up an S3 lifecycle policy that automatically expires data in the source S3 bucket after a safe amount of time has passed.
Securing Access to the Data Lake
Lake Formation provides secure and granular access to data stores in the data lake, via a new grant/revoke permissions model that augments IAM policies. It is simple to set up these permissions, for example using the console:

I simply select the IAM user or role I want to grant access to. Then I select the database and optionally the tables and the columns I want to provide access to. It is also possible to select which type of access to provide. For this demo, simple select permissions are sufficient.
Accessing the Data Lake
Now I can query the data using tools like Amazon Athena or Amazon Redshift. For example, I open the query editor in the Athena console. First, I want to use my new data lake to look into which source IP addresses are most common in my AWS Account activity:
SELECT sourceipaddress, count(*)
FROM my_trail_cloudtrail
GROUP BY sourceipaddress
ORDER BY 2 DESC;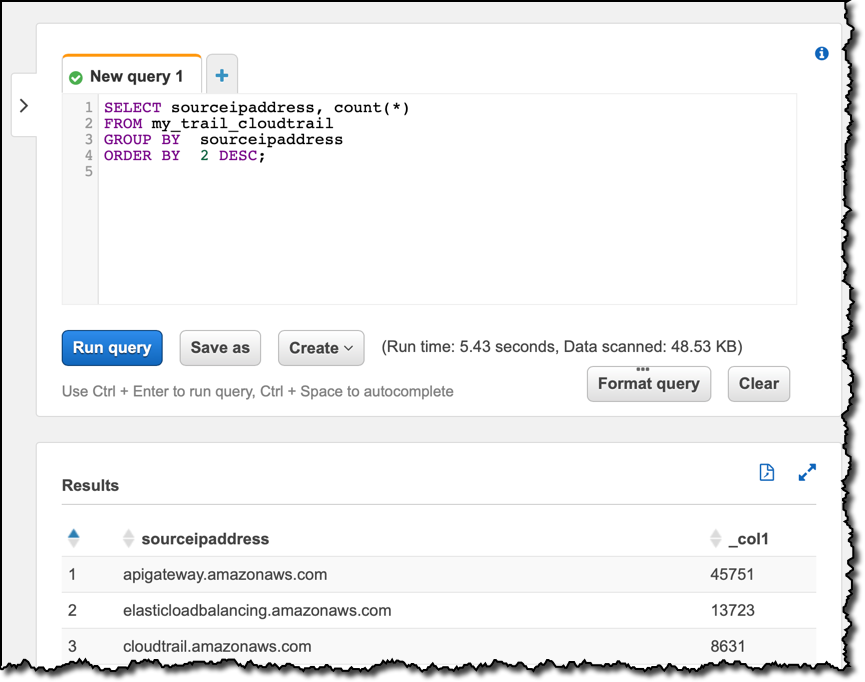
Looking at the result of the query, you can see which are the AWS API endpoints that I use the most. Then, I’d like to check which user identity types are used. That is an information stored in JSON format inside one of the columns. I can use some of the JSON functions available with Amazon Athena to get that information in my SQL statements:
SELECT json_extract_scalar(useridentity, '$.type'), count(*)
FROM "mylake"."my_trail_cloudtrail"
GROUP BY json_extract_scalar(useridentity, '$.type')
ORDER BY 2 DESC;
Most of the times, AWS services are the ones creating activities in my trail. These queries are just an example, but give me quickly a deeper insight in what is happening in my AWS account.
Think of what could be a similar impact for your business! Using database and logs blueprints, you can quickly create workflows to ingest data from multiple sources within your organization, set the right permission at column level of who can have access to any information collected, clean and prepare your data using machine learning transforms, and correlate and visualize the information using tools like Amazon Athena, Amazon Redshift, and Amazon QuickSight.
Customizing Data Access with Column-Level Permissions
In order to follow data privacy guidelines and compliance, the mission-critical data stored in a data lake requires to create custom views for different stakeholders inside the company. Let’s compare the visibility of two IAM users in my AWS account, one that has full permissions on a table, and one that has only select access to a subset of the columns of the same table.
I already have a user with full access to the table containing my CloudTrail data, it’s called danilop. I create a new limitedview IAM user and I give it access to the Athena console. In the Lake Formation console, I only give this new user select permissions on three of the columns.
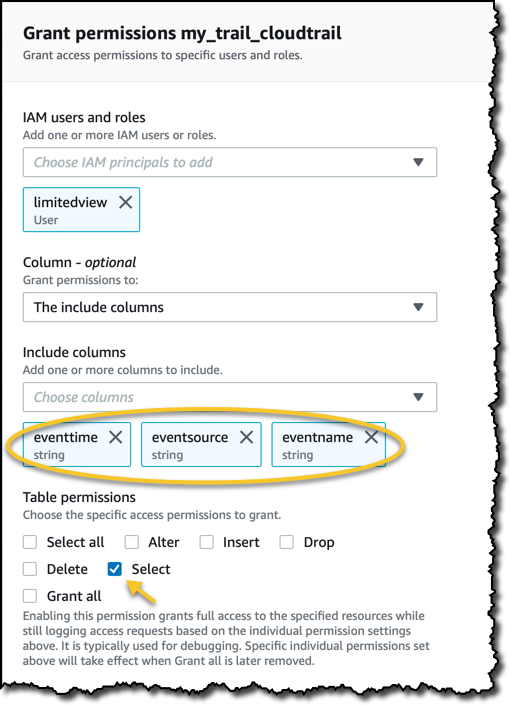
To verify the different access to the data in the table, I log in with one user at a time and go to the Athena console. On the left I can explore which tables and columns the logged-in user can see in the Glue Data Catalog. Here’s a comparison for the two users, side-by-side:
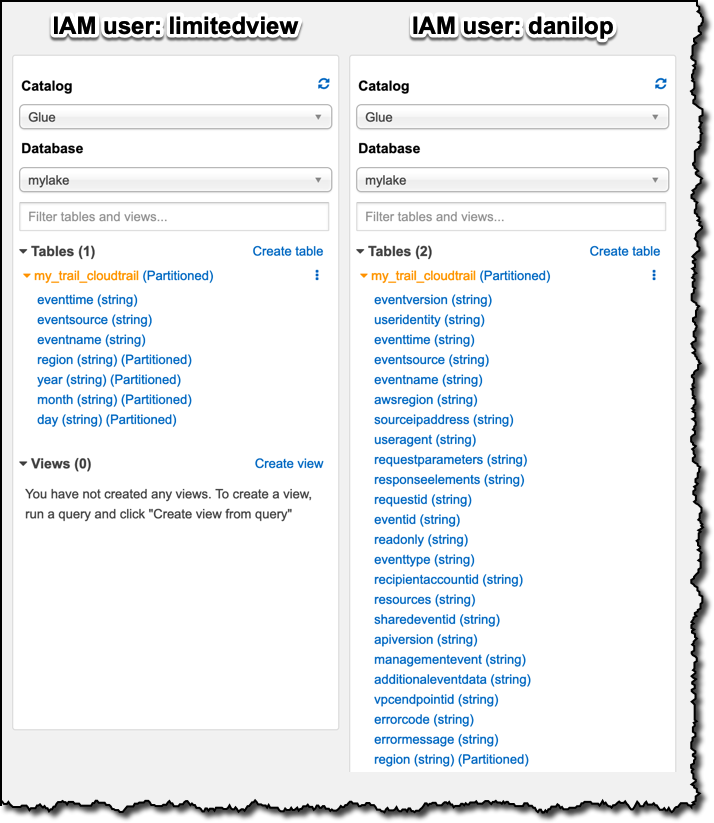
The limited user has access only to the three columns that I explicitly configured, and to the four columns used for partitioning the table, whose access is required to see any data. When I query the table in the Athena console with a select * SQL statement, logged in as the limitedview user, I only see data from those seven columns: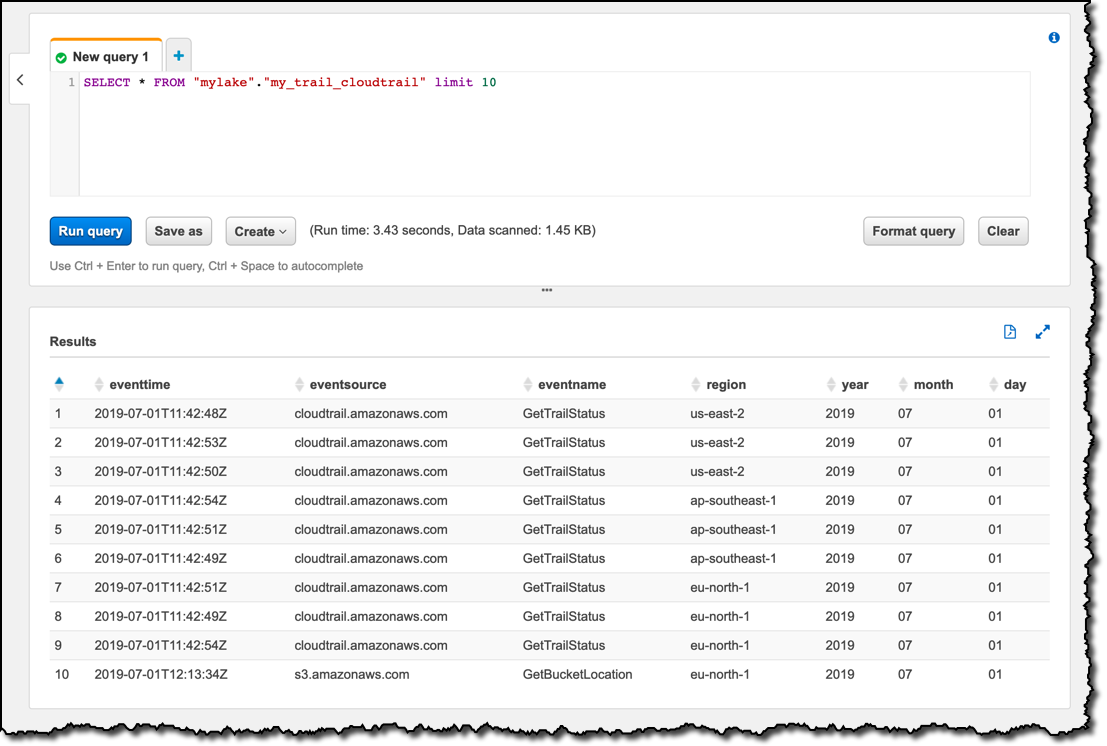
Available Now
There is no additional cost in using AWS Lake Formation, you pay for the use of the underlying services such as Amazon S3 and AWS Glue. One of the core benefits of Lake Formation are the security policies it is introducing. Previously you had to use separate policies to secure data and metadata access, and these policies only allowed table-level access. Now you can give access to each user, from a central location, only to the the columns they need to use.
AWS Lake Formation is now available in US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo). Redshift integration with Lake Formation requires Redshift cluster version 1.0.8610 or higher, your clusters should have been automatically updated by the time you read this. Support for Apache Spark with Amazon EMR is in public beta.
I only scratched the surface of what you can do with Lake Formation. Building and managing a data lake for your business is now much easier, let me know how you are using these new capabilities!
— Danilo