AWS Big Data Blog

Author: Asser Moustafa
Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas, USA. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.

How Getir unleashed data democratization using a data mesh architecture with Amazon Redshift
In this post, we explain how ultrafast delivery pioneer, Getir, unleashed the power of data democratization on a large scale through their data mesh architecture using Amazon Redshift. We start by introducing Getir and their vision—to seamlessly, securely, and efficiently share business data across different teams within the organization for BI, extract, transform, and load (ETL), and other use cases. We’ll then explore how Amazon Redshift data sharing powered the data mesh architecture that allowed Getir to achieve this transformative vision.

Power enterprise-grade Data Vaults with Amazon Redshift – Part 1
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than other cloud data warehouses. As with all AWS […]
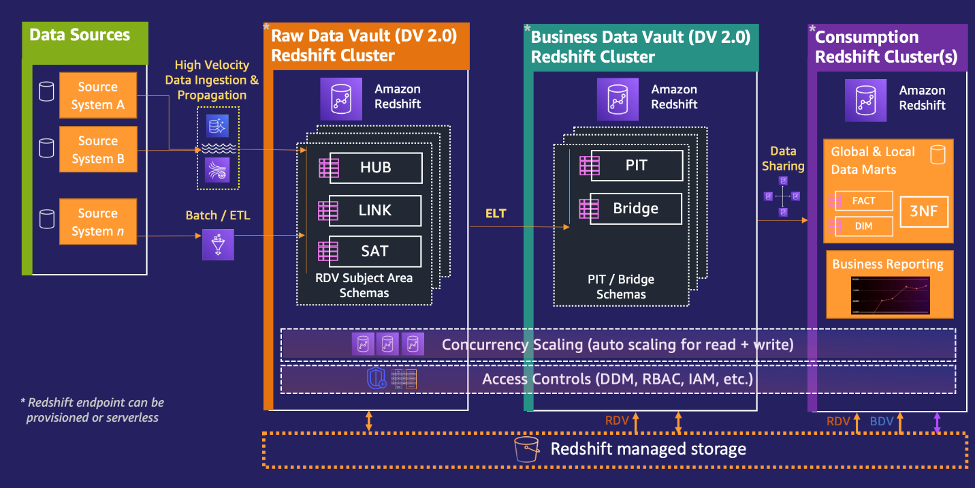
Power enterprise-grade Data Vaults with Amazon Redshift – Part 2
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than any other cloud data warehouses. As with all […]

Power highly resilient use cases with Amazon Redshift
Amazon Redshift is the most popular and fastest cloud data warehouse, offering seamless integration with your data lake and other data sources, up to three times faster performance than any other cloud data warehouse, automated maintenance, separation of storage and compute, and up to 75% lower cost than any other cloud data warehouse. This post […]

Building high-quality benchmark tests for Amazon Redshift using Apache JMeter
Updated April 2021 to offer more Apache JMeter tips, and highlight some capabilities in the newer version of Apache JMeter. In the introductory post of this series, we discussed benchmarking benefits and best practices common across different open-source benchmarking tools. As a reminder of why benchmarking is important, Amazon Redshift allows you to scale storage […]

Building high-quality benchmark tests for Amazon Redshift using SQLWorkbench and psql
In the introductory post of this series, we discussed benchmarking benefits and best practices common across different open-source benchmarking tools. In this post, we discuss benchmarking Amazon Redshift with the SQLWorkbench and psql open-source tools. Let’s first start with a quick review of the introductory installment. When you use Amazon Redshift to scale compute and […]

Building high-quality benchmark tests for Redshift using open-source tools: Best practices
Amazon Redshift is the most popular and fastest cloud data warehouse, offering seamless integration with your data lake, up to three times faster performance than any other cloud data warehouse, and up to 75% lower cost than any other cloud data warehouse. When you use Amazon Redshift to scale compute and storage independently, a need […]