AWS Big Data Blog
Power highly resilient use cases with Amazon Redshift
Amazon Redshift is the most popular and fastest cloud data warehouse, offering seamless integration with your data lake and other data sources, up to three times faster performance than any other cloud data warehouse, automated maintenance, separation of storage and compute, and up to 75% lower cost than any other cloud data warehouse. This post explores different architectures and use cases that focus on maximizing data availability, using Amazon Redshift as the core data warehouse platform.
In the modern data-driven organization, many data analytics use cases using Amazon Redshift have increasingly evolved to assume a critical business profile. Those use cases are now required to be highly resilient with little to no downtime. For example, analytical use cases that once relied solely on historical data and produced static forecasts are now expected to continuously weave real-time streaming and operational data into their ever-updating analytical forecasts. Machine learning (ML) use cases that relied on overnight batch jobs to extract customer churn predictions from extremely large datasets are now expected to perform those same customer churn predictions on demand using both historical and intraday datasets.
This post is part one of a series discussing high resiliency and availability with Amazon Redshift. In this post, we discuss a diverse set of popular analytical use cases that have traditionally or perhaps more recently assumed a critical business profile. The goal of this post is to show the art of the possible with high resiliency use cases. For each use case, we provide a brief description and explore the reasons for its critical business profile, and provide a reference architecture for implementing the use case following best practices. In the following section, we include a brief mention of some of the complimentary high resiliency features in Amazon Redshift as they apply for each use case.
In the final section of this post, we expand the scope to discuss high resiliency in a data ecosystem that uses Amazon Redshift. In particular, we discuss the Lake House Architecture in the high resiliency context.
Part two of this series (coming soon) provides a deeper look into the individual high resiliency and availability features of Amazon Redshift.
Now let’s explore some of the most popular use cases that have traditionally required high resiliency or have come to require high resiliency in the modern data-driven organization.
Data analytics as a service
Many analytical use cases focus on extracting value from data collected and produced by an organization to serve the organization’s internal business and operational goals. In many cases, however, the data collected and produced by an organization can itself be packaged and offered as a product to other organizations. More specifically, access to the data collected and produced along with analytical capabilities is typically offered as a paid service to other organizations. This is referred to as data analytics as a service (DaaS).
For example, consider a marketing agency that has amassed demographic information for a geographic location such as population by age, income, and family structure. Such demographic information often serves as a vital input for many organizations’ decisions to identify the ideal location for expansion, match their products with likely buyers, product offerings, and many other business needs. The marketing agency can offer access to this demographic information as a paid service to a multitude of retailers, healthcare providers, resorts, and more.
Some of the most critical aspects of DaaS offerings are ease of management, security, cost-efficiency, workload isolation, and high resiliency and availability. For example, the marketing agency offering the DaaS product needs the ability to easily refresh the demographic data on a regular cadence (ease of management), ensure paying customers are able to access only authorized data (security), minimize data duplication to avoid runaway costs and keep the DaaS competitively priced (cost-efficiency), ensure a consistent performance profile for paying customers (workload isolation), and ensure uninterrupted access to the paid service (high availability).
By housing the data in one or more Amazon Redshift clusters, organizations can use the service’s data sharing capabilities to make such DaaS patterns possible in an easily manageable, secure, cost-efficient, and workload-isolated manner. Paying customers are then able to access the data using the powerful search and aggregation capabilities of Amazon Redshift. The following architecture diagram illustrates a commonly used reference architecture for this scenario.

The following diagram illustrates another reference architecture that provides high resiliency and availability for internal and external consumers of the data.
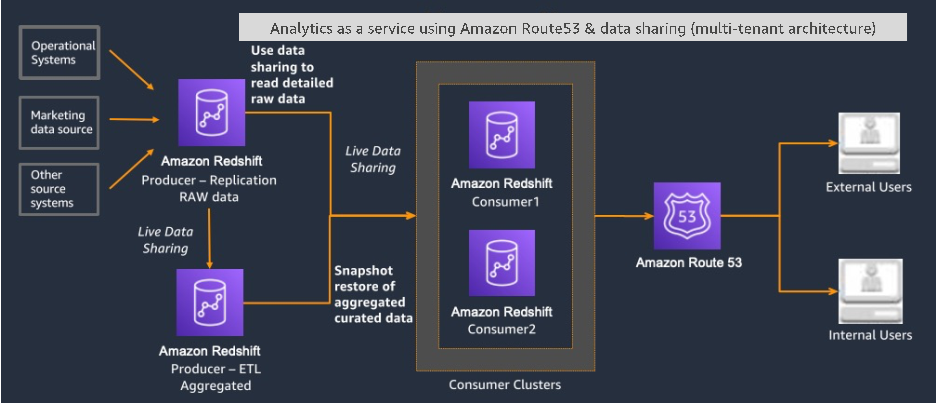
While an in-depth discussion of the data sharing capabilities in Amazon Redshift is beyond the scope of this post, refer to the following resources for more information:
- Implementing multi-tenant patterns in Amazon Redshift using data sharing
- Cross-Account Data Sharing for Amazon Redshift
- Announcing Amazon Redshift data sharing
- Create highly resilient and available architectures with Amazon Redshift (coming soon)
Fresh forecasts
As the power of the modern data ecosystem is unleashed, analytical workloads that traditionally yielded point-in-time reports based solely on historical datasets are evolving to incorporate data in real-time and produce on-demand analysis.
For example, event coordinators that may have had to rely solely on historical datasets to create analytical sales forecasts in business intelligence (BI) dashboards for upcoming events are now able to use Amazon Redshift federated queries to incorporate live ticket sales stored in operational data stores such as Amazon Aurora or Amazon Relational Database Service (Amazon RDS). With federated queries, event coordinators can now have their analytical workloads running on Amazon Redshift query and incorporate operational data such as live ticket sales stored in Aurora on demand so that BI dashboards reflect the most up-to-date ticket sales.
Setting up federated queries is achieved by creating external tables that reference the tables of interest in an RDS instance. The following reference architecture illustrates one straightforward way to achieve federated queries using two different versions of Aurora.
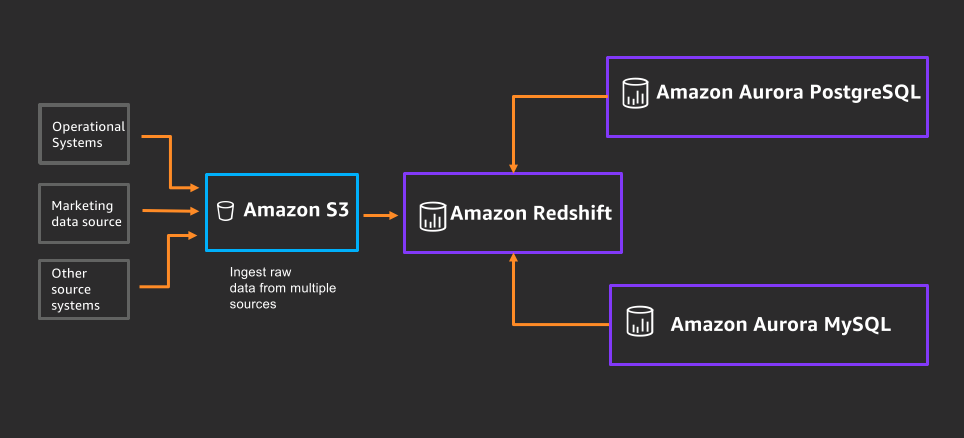
While an in-depth discussion of federated query capabilities in Amazon Redshift is beyond the scope of this post, refer to the following resources for more information:
- Best practices for Amazon Redshift Federated Query
- Build a Simplified ETL and Live Data Query Solution using Redshift Federated Query
- Accelerating Amazon Redshift federated query to Amazon Aurora MySQL with AWS CloudFormation
ML-based predictions
The multitude of ML-based predictive use cases and extensive analytical capabilities offered within the AWS ecosystem has placed ML in an ever-prominent and critical role within data-driven organizations. This could be retailers looking to predict customer churn, healthcare insurers looking to predict the number of claims in the next 30 days, financial services organizations working to detect fraud or managing their market risk and exposure, and more.
Amazon Redshift ML provides seamless integration to Amazon SageMaker for training ML models as often as necessary using data stored in Amazon Redshift. Redshift ML also provides the ability to weave on-demand, ML-based predictions directly into Amazon Redshift analytical workloads. The ease with which ML predictions can now be used in Amazon Redshift has paved the path to analytical workloads or BI dashboards that either use or center around ML-based predictions, and that are relied on heavily by operations teams, business teams, and many other users.
For example, retailers may have traditionally relied on ML models that were trained in a periodic cadence, perhaps weekly or some other lengthy interval, to predict customer churn. A lot can change, however, during those training intervals, rendering the retailer’s ability to predict customer churn less effective. With Redshift ML, retailers are now able to train their ML models using their most recent data within Amazon Redshift and incorporate ML predictions directly in the Amazon Redshift analytical workloads used to power BI dashboards.
The following reference architecture demonstrates the use of Redshift ML functions in various analytical workloads. With ANSI SQL commands, you can use Amazon Redshift data to create and train an ML model (Amazon Redshift uses SageMaker) that is then made accessible through an Amazon Redshift function. That function can then be used in various analytical workloads.
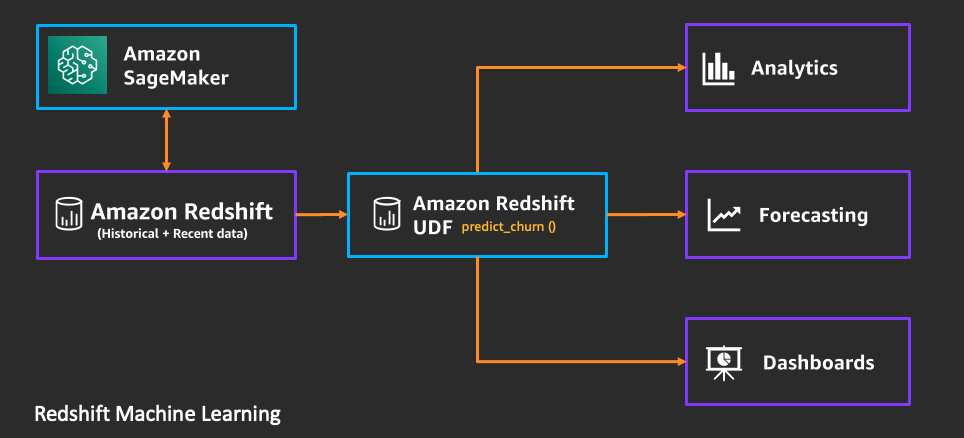
While an in-depth discussion of Redshift ML is beyond the scope of this post, refer to the following resources for more information:
- Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML
- Build regression models with Amazon Redshift ML
Production data for dev environments
Having access to high-quality test data is one of the most common challenges encountered in the development process. To maintain access to high-quality test data, developers must often overcome hurdles such as high administrative overhead for replicating data, increased costs from data duplication, prolonged downtime, and risk of losing development artifacts when refreshing test environments.
The data sharing feature enables Amazon Redshift development clusters to access high-quality production data directly from an Amazon Redshift production or pre-production cluster in a straightforward, secure, and cost-efficient approach that achieves a highly resilient posture.
For example, you can establish a data share on the Amazon Redshift production cluster that securely exposes only the schemas, tables, or views appropriate for development environments. The Amazon Redshift development cluster can then use that data share to query the high-quality production data directly where it is persisted on Amazon Simple Storage Service (Amazon S3), without impacting the Amazon Redshift production cluster’s compute capacity. Because the development cluster uses its own compute capacity, the production cluster’s high resiliency and availability posture is insulated from long-running experimental or development workloads. Likewise, development workloads are insulated from competing for compute resources on the production cluster.
In addition, querying the high-quality production data via the production cluster’s data share avoids unnecessary data duplication that can lead to higher storage costs. As the production data changes, the development cluster automatically gains access to the latest high-quality production data.
Finally, for development features that require schema changes, developers are free to create custom schemas on the development cluster that are based on the high-quality production data. Because the production data is decoupled from the development cluster, the custom schemas are located only on the development cluster, and the production data is not impacted in any way.
Let’s explore two example reference architectures that you can use for this use case.
Production data for dev environments using current-generation Amazon Redshift instance types
With the native Amazon Redshift data sharing available with the current generation of Amazon Redshift instance types (RA3), we can use a relatively straightforward architecture to enable dev environments with the freshest high-quality production data.
In the following architecture diagram, the production cluster takes on the role of a producer cluster, because it’s the cluster producing the data of interest. The development clusters take on the role of the consumer cluster because they’re the clusters interested in accessing the produced data. Note that the producer and consumer roles are merely labels to clarify the different role of each cluster, and not a formal designation within Amazon Redshift.

Production data for dev environments using previous-generation Amazon Redshift instance types
When we discussed this use case, we relied entirely on the native data sharing capability in Amazon Redshift. However, if you’re using the previous generation Amazon Redshift instance types of dense compute (DC) and dense storage (DS) nodes in your production environments, you should employ a slightly different implementation of this use case, because native Amazon Redshift data sharing is available only for the current generation of Amazon Redshift instance types (RA3).
First, we use a snapshot of the dense compute or dense storage production cluster to restore the production environment to a new RA3 cluster that has the latest production data. Let’s call this cluster the dev-read cluster to emphasize that this cluster is only for read-only purposes and doesn’t exhibit any data modifications. In addition, we can stand up a second RA3 cluster that simply serves as a sandbox for developers with data shares established to the dev-read cluster. Let’s call this cluster the dev-write cluster, because its main purpose is to serve as a read/write sandbox for developers and broader development work.
The following diagram illustrates this setup.
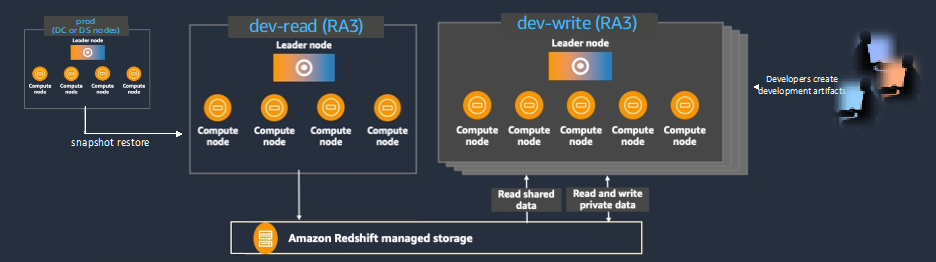
One of the key benefits of having a separate dev-read and dev-write cluster is that the dev-read cluster can be swapped out with a new RA3 cluster containing fresher production data, without wiping out all of the potential development artifacts created by developers (stored procedures for debugging, modified schemas, elevated privileges, and so on). This resiliency is a crucial benefit for many development teams that might otherwise significantly delay refreshing their development data simply because they don’t want to lose their testing and debugging artifacts or broader development settings.
For example, if the development team wants to refresh the production data in the dev-read cluster on the first of every month, then every month you could rename the current dev-read cluster to dev-read-old, and use the latest production snapshot to create a new dev-read RA3 cluster. You also have to reestablish the data share setup between the dev-write and dev-read clusters along with the dev-read cluster swap, but this task can be automated fairly easily and quickly using a number of approaches.
Another key benefit is that the dev-read cluster doesn’t exhibit any load beyond the initial snapshot restoration, so it can be a simple two-node ra3.xlplus cluster to minimize cost, while the dev-write cluster can be more appropriately sized for development workloads. In other words, there is minimal additional cost with this setup vs. using single development cluster.
While an in-depth discussion of Amazon Redshift’s data sharing capabilities is beyond the scope of this post, refer to the following resources for more information:
- Sharing Amazon Redshift data securely across Amazon Redshift clusters for workload isolation
- Announcing Amazon Redshift data sharing
- Create highly resilient and available architectures with Amazon Redshift (coming soon)
Streaming data analytics
With integration between the Amazon Kinesis family of services and Amazon Redshift, you have an easy and reliable way to load streaming data into data lakes as well as analytics services. Amazon Kinesis Data Firehose micro-batches real-time streaming messages and loads those micro-batches into the designated table within Amazon Redshift. With a few clicks on the Kinesis Data Firehose console, you can create a delivery stream that can ingest streaming data from hundreds of sources to multiple destinations, including Amazon Redshift. Should there be any interruptions in publishing streaming messages to Amazon Redshift, Kinesis Data Firehose automatically attempts multiple retries, and you can configure and customize that retry behavior.
You can also configure Amazon Kinesis Data Streams to convert the incoming data to open formats like Apache Parquet and ORC before data is delivered to Amazon Redshift for optimal query performance. You can even dynamically partition your streaming data using well-defined keys like customer_id or transaction_id. Kinesis Data Firehose groups data by these keys and delivers into key-unique S3 prefixes, making it easier for you to perform high-performance, cost-efficient analytics in Amazon S3 using Amazon Redshift and other AWS services.
The following reference architecture shows one of the straightforward approaches to integrating Kinesis Data Firehose and Amazon Redshift.
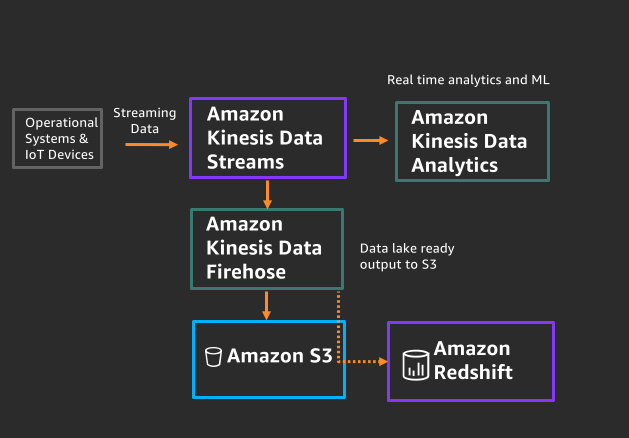
While an in-depth discussion of Kinesis Data Firehose and integration with Amazon Redshift are beyond the scope of this post, refer to the following resources for more information:
Change data capture
While Amazon Redshift federated query enables Amazon Redshift to directly query data stored in an operational data store such as Aurora, there are also times when it helps for some of that operational data to be entirely replicated to Amazon Redshift for a multitude of other analytical use cases, such as data refinement.
After an initial replication from the operational data store to Amazon Redshift, ongoing change data capture (CDC) replications are required to keep Amazon Redshift updated with subsequent changes that occurred on the operational data store.
With AWS Database Migration Service (AWS DMS), you can automatically replicate changes in an operational data store such as Aurora to Amazon Redshift in a straightforward, cost-efficient, secure, and highly resilient and available approach. As data changes on the operational data store, AWS DMS automatically replicates those changes to the designated table on Amazon Redshift.
The following reference architecture illustrates the straightforward use of AWS DMS to replicate changes in an operational data store such as Amazon Aurora, Oracle, SQL Server, etc. to Amazon Redshift and other destinations such as Amazon S3.
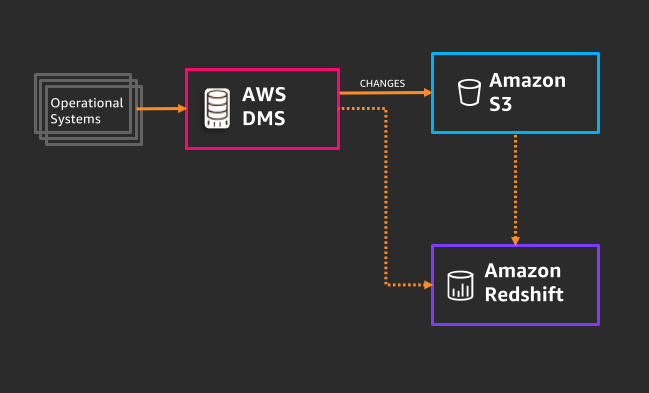
While an in-depth discussion of AWS DMS is beyond the scope of this post, refer to the following resources for more information:
- Converging Data Silos to Amazon Redshift Using AWS DMS
- How can I use Amazon Redshift as the target endpoint for my AWS DMS task?
Workload isolation
Sharing data can improve the agility of your organization by encouraging more connections and fostering collaboration, which allows teams to build upon the work of others rather than repeat already existing processes. Amazon Redshift does this by giving you instant, granular, and high-performance access to data across Amazon Redshift clusters without needing you to manually copy or move your data. You have live access to data so your users can see the most up-to-date and consistent information as it’s updated in Amazon Redshift clusters.
Amazon Redshift parallelizes queries across the different nodes of a cluster, but there may be circumstances when you want to allow more concurrent queries than one cluster can provide or provide workload separation. You can use data sharing to isolate your workloads, thereby minimizing the possibility that a deadlock situation in one workload impacts other workloads running on the same cluster.
The traditional approach to high resiliency and availability is to deploy two or more identical, independent, and parallel Amazon Redshift clusters. However, this design requires that all database updates be performed on all Amazon Redshift clusters. This introduces complexity in your overall architecture. In this section, we demonstrate how to use data sharing to design a highly resilient and available architecture with workload isolation.
The following diagram illustrates the high-level architecture for data sharing in Amazon Redshift.
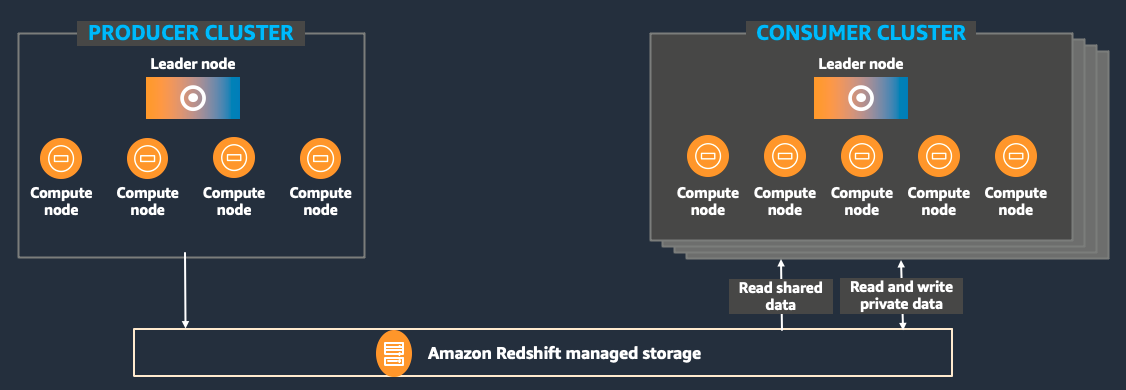
This architecture supports different kinds of business-critical workloads, such as using a central extract, transform, and load (ETL) cluster that shares data with multiple analytic or BI clusters. This approach provides BI workload isolation, so individual BI workloads don’t impact the performance of the ETL workloads and vice-versa. You can scale the individual Amazon Redshift cluster compute resources according to the workload-specific requirements of price and performance.
Amazon Redshift Spectrum is a feature of Amazon Redshift that enables you to run queries against exabytes of unstructured data in Amazon S3, with no loading or ETL required. You can use your producer cluster to process the Amazon S3 data and unload the resulting dataset back to Amazon S3. Then set up as many Amazon Redshift consumer clusters as you need to query your Amazon S3 data lake, thereby providing high resiliency and availability, and limitless concurrency.
Highly available data ecosystem using Amazon Redshift
In this section, we delve a little deeper into the Lake House Architecture, which achieves a wide range of best practices while providing several high resiliency and availability benefits that complement Amazon Redshift.
In the modern data ecosystem, many data-driven organizations have achieved tremendous success employing a Lake House Architecture to process the ever-growing volume, velocity, and variety of data. In addition, the Lake House Architecture has helped those data-driven organizations achieve greater resiliency.
As the following diagram shows, the Lake House Architecture consists of a data lake serving as the single source of truth with different compute layers such as Amazon Redshift sitting atop the data lake (in effect building a house on the lake, hence the term “lake house”).
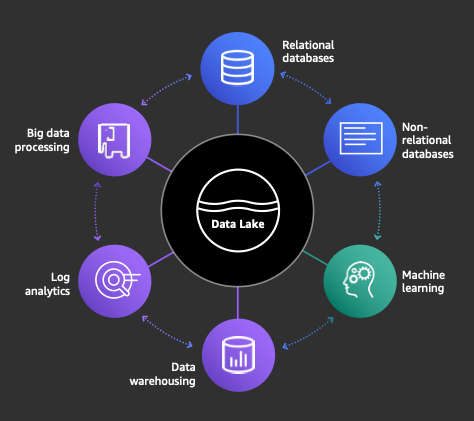
Organizations can use a data lake to maximize data availability by centrally storing the data in the durable Amazon S3 layer but obtain access from multiple AWS products. Separation of compute and storage offers several resiliency and availability advantages. A data lake provides these same advantages but from a heterogeneous set of services that can all access a common data layer. Using Amazon Redshift with a Lake House Architecture reinforces the lake house’s high resiliency and availability. Furthermore, with the seamless integration of Amazon Redshift with the S3 data lake, you can use Redshift Spectrum to run ANSI SQL queries within Amazon Redshift that directly reference external tables in the S3 data lake, as is often done with cold data (data that is infrequently accessed).
In addition, there are a multitude of straightforward services such as AWS Glue, AWS DMS, and AWS Lambda that you can use to load warm data (data that is frequently accessed) from an S3 data lake to Amazon Redshift for greater performance.
Conclusion
In this post, we explored several analytical use cases that require high resiliency and availability and provided an overview of the Amazon Redshift features that help fulfill those requirements. We also presented a few example reference architectures for those use cases as well as a data ecosystem reference architecture that provides a wide range of benefits and reinforces high resiliency and availability postures.
For further information on high resiliency and availability within Amazon Redshift or implementing the aforementioned use cases, we encourage you to reach out to your AWS Solutions Architect—we look forward to helping.
About the Authors
 Asser Moustafa is an Analytics Specialist Solutions Architect at AWS based out of Dallas, TX, USA. He advises customers in the Americas on their Amazon Redshift and data lake architectures and migrations, starting from the POC stage to actual production deployment and maintenance.
Asser Moustafa is an Analytics Specialist Solutions Architect at AWS based out of Dallas, TX, USA. He advises customers in the Americas on their Amazon Redshift and data lake architectures and migrations, starting from the POC stage to actual production deployment and maintenance.
 Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift. He is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift. He is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.