AWS Big Data Blog
Author: Melody Yang

RocksDB 101: Optimizing stateful streaming in Apache Spark with Amazon EMR and AWS Glue
This post explores RocksDB’s key features and demonstrates its implementation using Spark on Amazon EMR and AWS Glue, providing you with the knowledge you need to scale your real-time data processing capabilities.

Amazon EMR on EKS widens the performance gap: Run Apache Spark workloads 5.37 times faster and at 4.3 times lower cost
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast […]
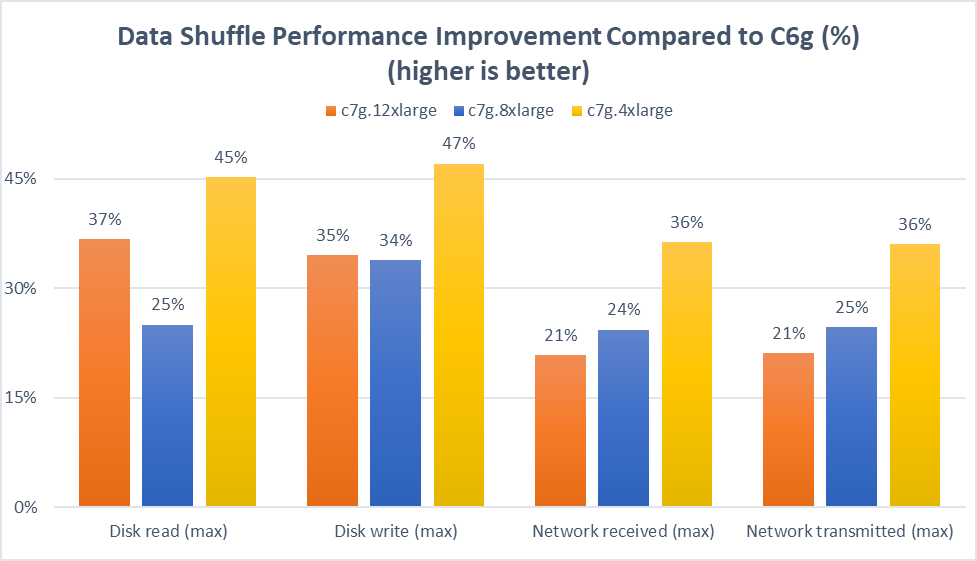
Amazon EMR on EKS gets up to 19% performance boost running on AWS Graviton3 Processors vs. Graviton2
Amazon EMR on EKS is a deployment option that enables you to run Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) easily. It allows you to innovate faster with the latest Apache Spark on Kubernetes architecture while benefiting from the performance-optimized Spark runtime powered by Amazon EMR. This deployment option elects Amazon EKS as […]

Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads
Amazon EMR on Amazon EKS is a deployment option offered by Amazon EMR that enables you to run Apache Spark applications on Amazon Elastic Kubernetes Service (Amazon EKS) in a cost-effective manner. It uses the EMR runtime for Apache Spark to increase performance so that your jobs run faster and cost less. In our benchmark […]

Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS
Increasingly, a business’s success depends on its agility in transforming data into actionable insights, which requires efficient and automated data processes. In the previous post – Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, we described a common productivity issue in a modern data architecture. To address the challenge, we demonstrated how to utilize a declarative approach as the key enabler to improve efficiency, which resulted in a faster time to value for businesses. Generally speaking, managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with open-source or in-house build frameworks to achieve the same productivity goal.

Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS
Today, the most successful and fastest growing companies are generally data-driven organizations. Taking advantage of data is pivotal to answering many pressing business problems; however, this can prove to be overwhelming and difficult to manage due to data’s increasing diversity, scale, and complexity. One of the most popular technologies that businesses use to overcome these […]