AWS Big Data Blog
Author: Roy Hasson

Make data available for analysis in seconds with Upsolver low-code data pipelines, Amazon Redshift Streaming Ingestion, and Amazon Redshift Serverless
Amazon Redshift is the most widely used cloud data warehouse. Amazon Redshift makes it easy and cost-effective to perform analytics on vast amounts of data. Amazon Redshift launched Streaming Ingestion for Amazon Kinesis Data Streams, which enables you to load data into Amazon Redshift with low latency and without having to stage the data in […]

Analyze Google Analytics data using Upsolver, Amazon Athena, and Amazon QuickSight
In this post, we present a solution for analyzing Google Analytics data using Amazon Athena. We’re including a reference architecture built on moving hit-level data from Google Analytics to Amazon S3, performing joins and enrichments, and visualizing the data using Amazon Athena and Amazon QuickSight. Upsolver is used for data lake automation and orchestration, enabling customers to get started quickly.
Separate queries and managing costs using Amazon Athena workgroups
Amazon Athena is a serverless query engine for data on Amazon S3. Many customers use Athena to query application and service logs, schedule automated reports, and integrate with their applications, enabling new analytics-based capabilities. Different types of users rely on Athena, including business analysts, data scientists, security, and operations engineers. In this post, I show you how to use workgroups to separate workloads, control user access, and manage query usage and costs.
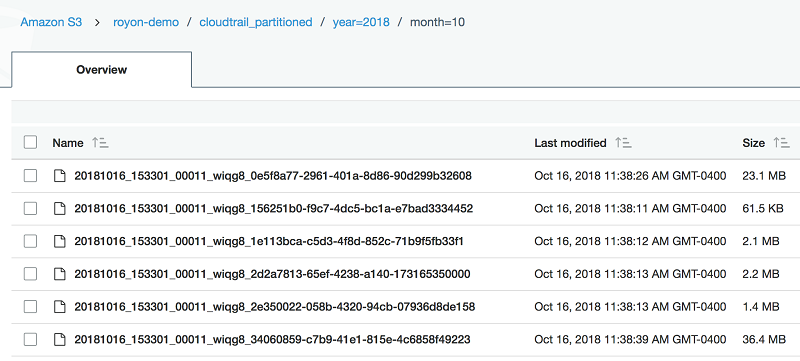
Use CTAS statements with Amazon Athena to reduce cost and improve performance
This blog post shows how to use the CREATE TABLE AS SELECT (CTAS statement) in Athena. It also shows how to automate the creation of unique tables that represent a subset of the AWS CloudTrail data. This helps us audit Amazon Athena usage.
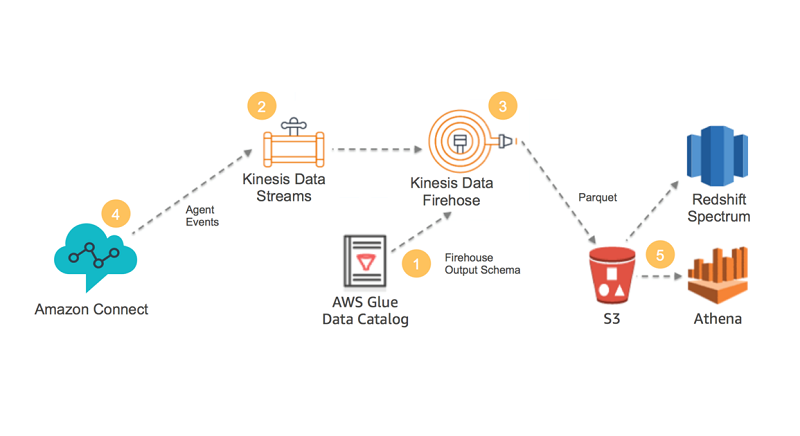
Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift
Kinesis Data Firehose can now save data to Amazon S3 in Apache Parquet or Apache ORC format. These are optimized columnar formats that are highly recommended for best performance and cost-savings when querying data in S3. This feature directly benefits you if you use Amazon Athena, Amazon Redshift, AWS Glue, Amazon EMR, or any other big data tools that are available from the AWS Partner Network and through the open-source community.

Genomic Analysis with Hail on Amazon EMR and Amazon Athena
For this task, we use Hail, an open source framework for exploring and analyzing genomic data that uses the Apache Spark framework. In this post, we use Amazon EMR to run Hail. We walk through the setup, configuration, and data processing. Finally, we generate an Apache Parquet–formatted variant dataset and explore it using Amazon Athena.