AWS Big Data Blog
Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
Amazon Kinesis Data Firehose is the easiest way to capture and stream data into a data lake built on Amazon S3. This data can be anything—from AWS service logs like AWS CloudTrail log files, Amazon VPC Flow Logs, Application Load Balancer logs, and others. It can also be IoT events, game events, and much more. To efficiently query this data, a time-consuming ETL (extract, transform, and load) process is required to massage and convert the data to an optimal file format, which increases the time to insight. This situation is less than ideal, especially for real-time data that loses its value over time.
To solve this common challenge, Kinesis Data Firehose can now save data to Amazon S3 in Apache Parquet or Apache ORC format. These are optimized columnar formats that are highly recommended for best performance and cost-savings when querying data in S3. This feature directly benefits you if you use Amazon Athena, Amazon Redshift, AWS Glue, Amazon EMR, or any other big data tools that are available from the AWS Partner Network and through the open-source community.
Amazon Connect is a simple-to-use, cloud-based contact center service that makes it easy for any business to provide a great customer experience at a lower cost than common alternatives. Its open platform design enables easy integration with other systems. One of those systems is Amazon Kinesis—in particular, Kinesis Data Streams and Kinesis Data Firehose.
What’s really exciting is that you can now save events from Amazon Connect to S3 in Apache Parquet format. You can then perform analytics using Amazon Athena and Amazon Redshift Spectrum in real time, taking advantage of this key performance and cost optimization. Of course, Amazon Connect is only one example. This new capability opens the door for a great deal of opportunity, especially as organizations continue to build their data lakes.
Amazon Connect includes an array of analytics views in the Administrator dashboard. But you might want to run other types of analysis. In this post, I describe how to set up a data stream from Amazon Connect through Kinesis Data Streams and Kinesis Data Firehose and out to S3, and then perform analytics using Athena and Amazon Redshift Spectrum. I focus primarily on the Kinesis Data Firehose support for Parquet and its integration with the AWS Glue Data Catalog, Amazon Athena, and Amazon Redshift.
Solution overview
Here is how the solution is laid out:

The following sections walk you through each of these steps to set up the pipeline.
1. Define the schema
When Kinesis Data Firehose processes incoming events and converts the data to Parquet, it needs to know which schema to apply. The reason is that many times, incoming events contain all or some of the expected fields based on which values the producers are advertising. A typical process is to normalize the schema during a batch ETL job so that you end up with a consistent schema that can easily be understood and queried. Doing this introduces latency due to the nature of the batch process. To overcome this issue, Kinesis Data Firehose requires the schema to be defined in advance.
To see the available columns and structures, see Amazon Connect Agent Event Streams. For the purpose of simplicity, I opted to make all the columns of type String rather than create the nested structures. But you can definitely do that if you want.
The simplest way to define the schema is to create a table in the Amazon Athena console. Open the Athena console, and paste the following create table statement, substituting your own S3 bucket and prefix for where your event data will be stored. A Data Catalog database is a logical container that holds the different tables that you can create. The default database name shown here should already exist. If it doesn’t, you can create it or use another database that you’ve already created.
That’s all you have to do to prepare the schema for Kinesis Data Firehose.
2. Define the data streams
Next, you need to define the Kinesis data streams that will be used to stream the Amazon Connect events. Open the Kinesis Data Streams console and create two streams. You can configure them with only one shard each because you don’t have a lot of data right now.
3. Define the Kinesis Data Firehose delivery stream for Parquet
Let’s configure the Data Firehose delivery stream using the data stream as the source and Amazon S3 as the output. Start by opening the Kinesis Data Firehose console and creating a new data delivery stream. Give it a name, and associate it with the Kinesis data stream that you created in Step 2.
As shown in the following screenshot, enable Record format conversion (1) and choose Apache Parquet (2). As you can see, Apache ORC is also supported. Scroll down and provide the AWS Glue Data Catalog database name (3) and table names (4) that you created in Step 1. Choose Next.

To make things easier, the output S3 bucket and prefix fields are automatically populated using the values that you defined in the LOCATION parameter of the create table statement from Step 1. Pretty cool. Additionally, you have the option to save the raw events into another location as defined in the Source record S3 backup section. Don’t forget to add a trailing forward slash “ / “ so that Data Firehose creates the date partitions inside that prefix.

On the next page, in the S3 buffer conditions section, there is a note about configuring a large buffer size. The Parquet file format is highly efficient in how it stores and compresses data. Increasing the buffer size allows you to pack more rows into each output file, which is preferred and gives you the most benefit from Parquet.

Compression using Snappy is automatically enabled for both Parquet and ORC. You can modify the compression algorithm by using the Kinesis Data Firehose API and update the OutputFormatConfiguration.
Be sure to also enable Amazon CloudWatch Logs so that you can debug any issues that you might run into.
Lastly, finalize the creation of the Firehose delivery stream, and continue on to the next section.
4. Set up the Amazon Connect contact center
After setting up the Kinesis pipeline, you now need to set up a simple contact center in Amazon Connect. The Getting Started page provides clear instructions on how to set up your environment, acquire a phone number, and create an agent to accept calls.
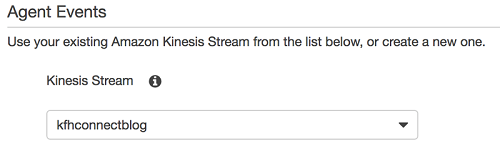
After setting up the contact center, in the Amazon Connect console, choose your Instance Alias, and then choose Data Streaming. Under Agent Event, choose the Kinesis data stream that you created in Step 2, and then choose Save.
At this point, your pipeline is complete. Agent events from Amazon Connect are generated as agents go about their day. Events are sent via Kinesis Data Streams to Kinesis Data Firehose, which converts the event data from JSON to Parquet and stores it in S3. Athena and Amazon Redshift Spectrum can simply query the data without any additional work.
So let’s generate some data. Go back into the Administrator console for your Amazon Connect contact center, and create an agent to handle incoming calls. In this example, I creatively named mine Agent One. After it is created, Agent One can get to work and log into their console and set their availability to Available so that they are ready to receive calls.

To make the data a bit more interesting, I also created a second agent, Agent Two. I then made some incoming and outgoing calls and caused some failures to occur, so I now have enough data available to analyze.
5. Analyze the data with Athena
Let’s open the Athena console and run some queries. One thing you’ll notice is that when we created the schema for the dataset, we defined some of the fields as Strings even though in the documentation they were complex structures. The reason for doing that was simply to show some of the flexibility of Athena to be able to parse JSON data. However, you can define nested structures in your table schema so that Kinesis Data Firehose applies the appropriate schema to the Parquet file.
Let’s run the first query to see which agents have logged into the system.
The query might look complex, but it’s fairly straightforward:
The query output looks something like this:

Here is another query that shows the sessions each of the agents engaged with. It tells us where they were incoming or outgoing, if they were completed, and where there were missed or failed calls.
The query output looks similar to the following:

6. Analyze the data with Amazon Redshift Spectrum
With Amazon Redshift Spectrum, you can query data directly in S3 using your existing Amazon Redshift data warehouse cluster. Because the data is already in Parquet format, Redshift Spectrum gets the same great benefits that Athena does.
Here is a simple query to show querying the same data from Amazon Redshift. Note that to do this, you need to first create an external schema in Amazon Redshift that points to the AWS Glue Data Catalog.
The following shows the query output:

Summary
In this post, I showed you how to use Kinesis Data Firehose to ingest and convert data to columnar file format, enabling real-time analysis using Athena and Amazon Redshift. This great feature enables a level of optimization in both cost and performance that you need when storing and analyzing large amounts of data. This feature is equally important if you are investing in building data lakes on AWS.
Additional Reading
If you found this post useful, be sure to check out Analyzing VPC Flow Logs with Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight and Work with partitioned data in AWS Glue.

About the Author
 Roy Hasson is a Global Business Development Manager for AWS Analytics. He works with customers around the globe to design solutions to meet their data processing, analytics and business intelligence needs. Roy is big Manchester United fan cheering his team on and hanging out with his family.
Roy Hasson is a Global Business Development Manager for AWS Analytics. He works with customers around the globe to design solutions to meet their data processing, analytics and business intelligence needs. Roy is big Manchester United fan cheering his team on and hanging out with his family.