AWS Big Data Blog

Author: Saurabh Shrivastava
Saurabh Shrivastava is a partner solutions architect and big data specialist working with global systems integrators. He works with AWS partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family outdoors and traveling to new destinations to discover new cultures
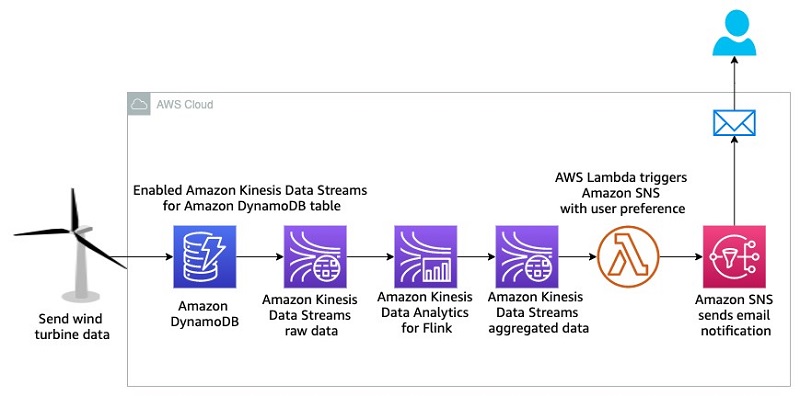
Building a real-time notification system with Amazon Kinesis Data Streams for Amazon DynamoDB and Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and Internet of Things (IoT) data so that you can develop […]

Build and automate a serverless data lake using an AWS Glue trigger for the Data Catalog and ETL jobs
September 2022: This post was reviewed and updated with latest screenshots and instructions. Today, data is flowing from everywhere, whether it is unstructured data from resources like IoT sensors, application logs, and clickstreams, or structured data from transaction applications, relational databases, and spreadsheets. Data has become a crucial part of every business. This has resulted […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.