AWS Big Data Blog
Bridging data silos: cross-bounded context querying with Vanguard’s Operational Read-only Data Store (ORDS) using Amazon Redshift
Are you modernizing your legacy batch processing systems? At Vanguard, we faced significant challenges with our legacy mainframe system that limited our ability to deliver modern, personalized customer experiences. Our centralized database architecture created performance bottlenecks and made it difficult to scale services independently for our millions of personal and institutional investors.
In this post, we show you how we modernized our data architecture using Amazon Redshift as our Operational Read-only Data Store (ORDS). You’ll learn how we transitioned to a cloud-native, domain-driven architecture while preserving critical batch processing capabilities. We show you how this solution enabled us to create logically isolated data domains while maintaining cross-domain analytics capabilities—all while adhering to the principles of bounded contexts and distributed data ownership.
Background and challenges
As financial needs continue to evolve, Vanguard is committed to delivering adaptable, top-notch experiences that foster long-lasting customer relationships. This commitment spans from enhancing the personal investor journey to bringing personalized mobile dashboards and connecting institutional clients with advanced advice offerings.
To elevate customer experience and drive digital transformation, Vanguard has embraced domain-driven design principles. This approach focuses on creating autonomous teams, fostering faster innovation, and building data mesh architecture. Central to this transformation is the Personal Investor team’s mainframe modernization effort, transitioning from a legacy system to a cloud-based, distributed data architecture organized around bounded contexts – distinct business domains that manage their own data. As part of this shift, each microservice now manages its own local data store using Amazon Aurora PostgreSQL-Compatible Edition or Amazon DynamoDB. This approach enables domain-level data ownership and operational autonomy.
Vanguard’s existing mainframe system, built on a centralized Db2 database, enables cross-domain data access and integration but also introduces several architectural challenges. Though batch processes can join data across multiple bounded contexts using SQL joins and database operations to integrate information from various sources, this tight coupling creates significant risks and operational issues.
Challenges with the centralized database approach include:
- Resource Contention: Processes from one domain can negatively impact other domains due to shared compute resources, leading to performance degradation across the system.
- Lack of Domain Isolation: Changes in one bounded context can have unintended ripple effects across other domains, increasing the risk of system-wide failures.
- Scalability Constraints: The centralized architecture creates bottlenecks as load increases, making it difficult to scale individual components independently.
- High Coupling: Tight integration between domains makes it challenging to modify or upgrade individual components without affecting the entire system.
- Limited Fault Tolerance: Issues in one domain can cascade across the entire system due to shared infrastructure and data dependencies.
To address these architectural challenges, we chose to use Amazon Redshift as our Operational Read-only Data Store (ORDS). The Amazon Redshift architecture has compute and storage separation, which enables us to create multi-cluster architectures with a separate endpoint for each domain with independent scaling of compute and storage resources. Our solution leverages the data sharing capabilities of Amazon Redshift to create logically isolated data domains while maintaining the ability to perform cross-domain analytics when needed.
Key benefits of the Amazon Redshift solution include:
- Resource Isolation: Each domain can be assigned dedicated Amazon Redshift compute resources, making sure one domain’s workload doesn’t impact others.
- Independent Scaling: Domains can scale their compute resources independently based on their specific needs.
- Controlled Data Sharing: Amazon Redshift’s data sharing feature enables secure and controlled cross-domain data access without tight coupling, maintaining clear domain boundaries.
Let’s explore the different solutions we evaluated before selecting ORDS with Amazon Redshift as our optimal approach.
Solutions explored
We implemented ORDS as our optimal solution after conducting a comprehensive evaluation of available options. This section outlines our decision-making process and examines the alternatives we considered during our assessment.
Operational Read-only Data Store (ORDS):
In our evaluation, we found that using Amazon Redshift for ORDS provides a powerful solution for handling data across different business areas. It excels at managing large volumes of data from multiple sources, providing fast access to replicated data for batch processes that require cross-bounded context data, and combining information using familiar SQL queries. The solution particularly shines in handling high-volume reads from our data sources.
Advantages:
- Works well in a relational database
- Excels at real-time access to data from multiple business areas
- Improves performance of batch jobs dealing with large data volumes
- Stores data in familiar table format, accessible via SQL
- Enforces clear data ownership, with each business area responsible for its data
- Offers scalable architecture that reduces the risk of single point of failure
Disadvantages:
- Requires additional data validation during loading processes to maintain data uniqueness
- Needs careful management of primary key constraints since Amazon Redshift optimizes for analytical performance
- May require additional monitoring and controls compared to traditional RDBMS systems
Here are the other solutions we evaluated:
Bulk APIs:
We found that Bulk APIs provides an approach for handling large volumes of data.
Advantages:
- Near real time access to bulk data through a single request
- Autonomous teams have control over access patterns
- Efficient batch processing of large datasets with multi-record retrieval
Disadvantages:
- Each product team needs to create their own bulk API
- If you need data from different areas, you must combine it yourself
- The team providing the API must make sure it can handle large amounts of requests
- You might need to use multiple APIs to get all the data you want
- If you’re getting data in chunks (pagination), you might miss some information if it changes between requests
While Bulk APIs offer powerful capabilities, we found they require substantial team coordination and careful implementation to be effective.
Data Lake:
Our evaluation showed that data lakes can effectively combine information from different parts of our business. They excel at processing large amounts of data at once, providing search capabilities through unified data formats, and managing large volumes of diverse and complex data.
Advantages:
- Handles massive data volumes efficiently
- Supports multiple data formats and structures
- Enables complex analytics and data science workloads
- Provides cost-effective storage solutions
- Accommodates both structured and unstructured data
Disadvantages:
- May not provide real-time, high-speed data access
- Requires additional effort with complex data structures, especially those with many interconnected parts
- Needs specific strategies to organize data in a simple, flat structure
- Demands significant data governance and management
- Requires specialized skills for effective implementation
While data lakes excel at big-picture analysis of large datasets, they weren’t optimal for our real-time data needs and complex data relationships.
S3 Export/Exchange:
In our analysis, we found that S3 Export/Exchange provides a method for sharing data between different business areas using file storage. This approach effectively handles large volumes of data and allows straightforward filtering of information using data frames.
Advantages:
- Provides simple, cost-effective data storage
- Supports high-volume data transfers
- Enables straightforward data filtering capabilities
- Offers flexible access control
- Facilitates cross-region data sharing
Disadvantages:
- Not suitable for real-time data needs
- Requires extra processing to convert data into usable table format
- Demands significant data preparation effort
- Lacks immediate data consistency
- Needs additional tools for data transformation
While S3 Export/Exchange works well for sharing large datasets between teams, it didn’t meet our requirements for quick, real-time access or immediately usable data formats.
The following table provides a high-level comparison of the different data integration solutions we considered for our modernization efforts. It outlines where each solution is most appropriate to use and when it might not be the best choice:
| Solution | Bulk APIs | Data Lake | ORDS | S3 Export/Exchange |
| When to use | Real-time operational data is needed
Fetching specific data subsets |
Processing large amounts of data at once
Many bounded context |
Near real-time access across multiple bounded contexts
Large volume batch processing |
Few bounded contextsHandling large volumes of data
Point-in-time export is sufficient |
| When not to use | Many bounded contexts involved | Real-time data access needed
Structured, transactional data processing |
Within a single bounded context | Real-time data needs
Many bounded contexts |
Table 1: Data Integration Solutions Comparison
Based on our comparison, we found ORDS to be the optimal solution for our needs, particularly when our batch processes require access to data from multiple bounded contexts in real-time. Our implementation efficiently handles large volumes of data, significantly improving the performance of our batch jobs. We chose ORDS because it stores data in a familiar table format, accessible via SQL, making it simple and efficient for our teams to use.
The architecture also aligns with our domain-driven design principles by enforcing clear data ownership, where each bounded context maintains responsibility for its own data management. This approach provides us with both scalability and reliability, reducing the risk of a single point of failure.
Amazon Redshift: Powering Vanguard’s ORDS Solution
Amazon Redshift serves as the backbone of our ORDS implementation, offering several crucial features that support our modernization goals:
Data Sharing
Our solution leveraged the robust data sharing capabilities of Amazon Redshift, available on both Server-based Redshift RA3 instances and Redshift Serverless options. This functionality provided us with instant, secure, and live data access without copies, maintaining transactional consistency across our environment. The flexibility of same account, cross-account, and cross-Region data sharing has been particularly valuable for our distributed architecture.
High Performance
We’ve achieved significant performance improvements through Amazon Redshift’s efficient query processing and data retrieval capabilities. The system effectively handles our complex data needs while maintaining robust performance across various workloads and data volumes.
Multi-Availability Zone Support
Our implementation benefited from Amazon Redshift’s Multi-AZ support, which maintains high availability and reliability for our critical operations. This feature minimizes downtime without requiring extensive setup and significantly reduces our risk of data loss.
Familiar Interface
The relational environment of Amazon Redshift, similar traditional databases like Amazon RDS and IBM Db2, has enabled a smooth transition for our teams. This familiarity has accelerated adoption and improved productivity, as our teams can leverage their existing SQL expertise. By centralizing data from multiple business areas in ORDS using Amazon Redshift, we maintain consistent, efficient, and secure data access across our product teams. This setup is particularly valuable for our batch processing that requires data from various parts of the business, offering us a blend of performance, reliability, and ease of use.
Operational Read-only Data Store (ORDS) using Amazon Redshift
Here’s how our ORDS architecture implements Amazon Redshift data sharing to solve these challenges:
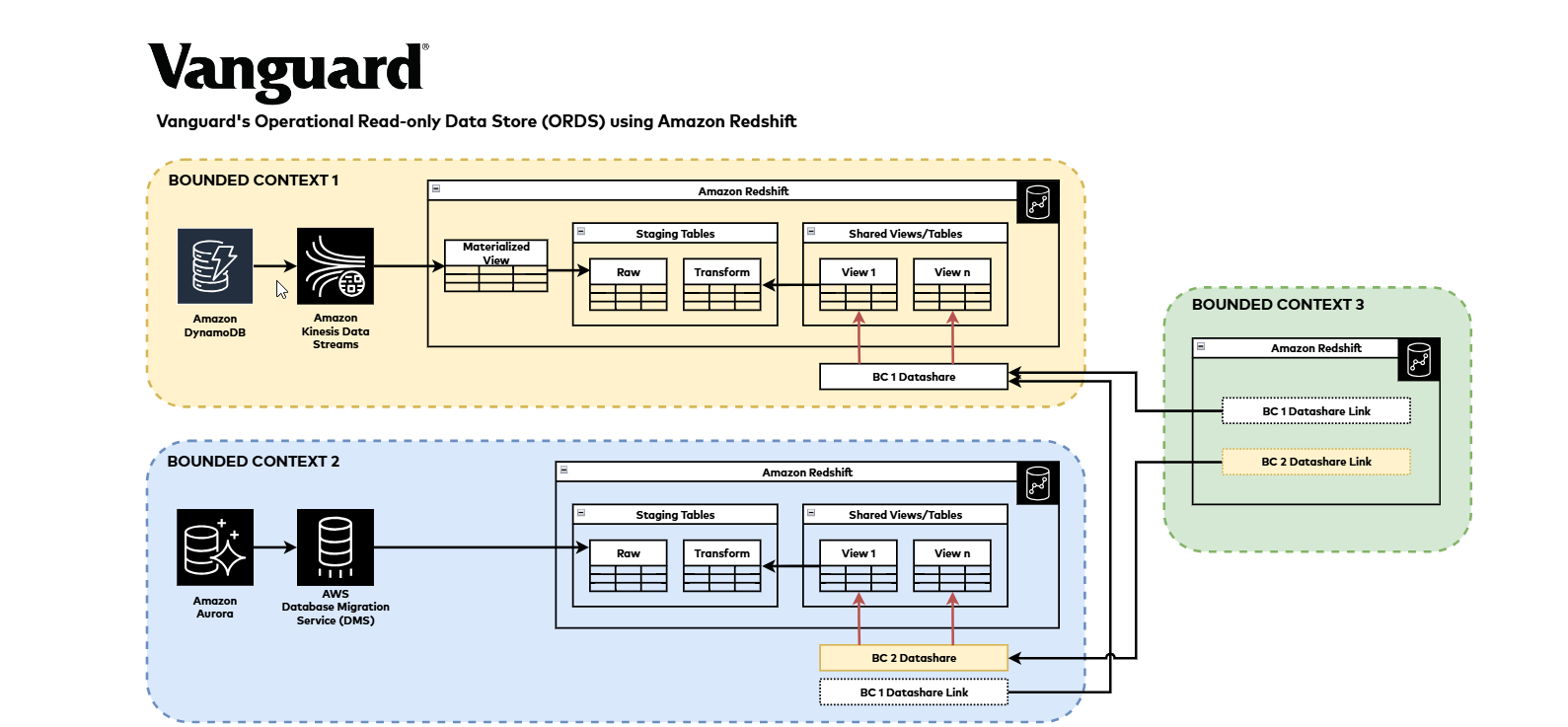
Figure 1: Vanguard’s ORDS Architecture using Amazon Redshift Data Sharing
Amazon Redshift Ingestion Pattern:
We utilized Amazon Redshift’s zero-ETL functionality to integrate data and enable real-time analytics directly on operational data, which helped reduce complexity and maintenance overhead. To complement this capability and to fulfill our comprehensive compliance requirements that necessitate complete transaction replication, we implemented additional data ingestion pipelines.
Our data ingestion strategy for Amazon Redshift employs different AWS services depending on the source. For Amazon Aurora PostgreSQL databases, we use AWS Database Migration Service (AWS DMS) to directly replicate data into Amazon Redshift. For data from Amazon DynamoDB, we leverage Amazon Kinesis to stream the data into Amazon Redshift, where it lands in materialized views. These views are then further processed to generate tables for end-users.
This approach allows us to efficiently ingest data from our operational data stores while meeting both analytical needs and compliance requirements.
Amazon Redshift Data Sharing:
We used the Amazon Redshift’s data sharing feature to effectively decouple our data producers from consumers, allowing each group to operate within their own boundaries while maintaining a unified and simplified governed mechanism for data sharing.
Our implementation followed a clear process: once data is ingested and available in Amazon Redshift table format, we created views for consumers to access the data. We then established data shares and granted access to these views to consumer Amazon Redshift data warehouses for batch processing. In our environment with multiple bounded contexts, we’ve established a collaborative model where consumers work with various producer teams to access data from different data shares, each created per bounded context.
This access remained strictly read-only—when consumers need to update or write new data that falls outside their bounded context, they must use APIs or other designated mechanisms for such operations. This approach has proven effective for our organization, promoting clear data ownership and governance while enabling flexible data access across organizational boundaries. It simplified our data management and made sure each team can operate independently while still sharing data effectively.
Example: VG couple of cross bounded context
Disclaimer: This is provided for reference purposes only and does not represent a real example.
Let’s look at a practical example: our brokerage account statement generation process. This cross-bounded context batch process requires integrating data from multiple sources, accessing hundreds of tables and processing large volumes of data monthly. The challenge was to create an efficient, cost-effective solution that minimizes data replication while maintaining data accessibility.ORDS proved ideal for this use case, as it provides data from multiple bounded contexts without replication, offers near real-time access, and enables straightforward data aggregation using SQL-like queries in Amazon Redshift.
The following diagram shows how we implemented this solution:
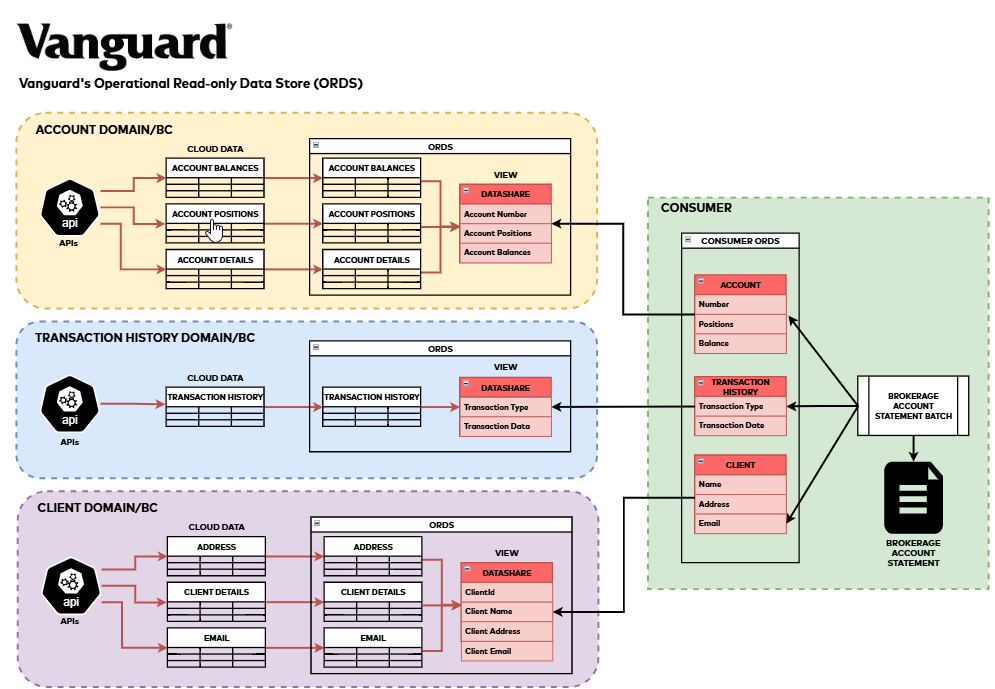
Figure 2: Cross-Bounded Context Example for Brokerage Account Statement Generation
We need the following bounded contexts to generate brokerage statements for millions of our clients.
- Account:
- Details: Includes information about the client’s brokerage accounts, such as account numbers, types, and statuses.
- Holdings and Positions: Provides current holdings and positions within the account, detailing the securities owned, their quantities, and current market values.
- Balance Information: Contains the balance information of the account, including cash balances, margin balances, and total account value.
- Client Profile:
- Personal Information: Information about the client, such as their name, date of birth, and social security number.
- Contact Information: Includes the client’s email address, physical address, and phone numbers.
- Transaction History:
- Transaction Records: A comprehensive record of transactions associated with the account, including buys, sales, transfers, and dividends.
- Transaction Details: Each transaction record includes details such as transaction date, type, quantity, price, and associated fees.
- Historical Data: Historical data of transactions over time, providing a complete view of the account’s activity.
Through this architecture, we efficiently generate accurate and comprehensive brokerage account statements by consolidating data from these bounded contexts, meeting both our clients’ needs and regulatory requirements.
Business Outcome
Our journey with the Operational Read-only Data Store (ORDS) and Amazon Redshift has enhanced our client experience (CX) through improved data management and accessibility. By transitioning from our mainframe system to a cloud-based, domain-driven architecture, we have empowered our autonomous teams and established a resilient batch architecture.
This shift facilitates efficient cross-domain data access, maintains high-quality data consistency, and provides scalability. Our ORDS implementation, supported by Amazon Redshift, offers near-real-time access to large data volumes, guaranteeing high performance, reliability, and cost-effectiveness. This modernization effort aligns with our mission to deliver exceptional, personalized client experiences and sustain long-lasting client relationships.
Call to Action
If you are facing similar challenges with your batch processing systems, we encourage you to explore how an Operational Read-only Data Store (ORDS) can transform your data architecture. Start by assessing your current system’s limitations and identifying opportunities for improvement through domain-driven design and cloud-based solutions. Consider how this approach can help you manage large volumes of data from multiple sources, provide fast access to replicated data for batch processes, and support high-volume reads from various data sources.
Take the next step by conducting a proof of concept (POC) to evaluate ORDS effectiveness in achieving efficient cross-domain data access, improving the performance of batch jobs, and maintaining clear data ownership within your business domains. By implementing this solution, you can enhance your data management capabilities, reduce operational risks, and drive innovation within your organization. Embrace this opportunity to elevate your data architecture and deliver exceptional customer experiences.
Conclusion
Our transition to a cloud-native, domain-driven architecture with ORDS using Amazon Redshift has successfully transformed our batch processing capabilities in AWS cloud. This modernization effort has significantly enhanced the performance, reliability, and scalability of our batch operations while maintaining seamless data access and integration across different business domains.
The strategic adoption of ORDS has harnessed the potential of cross-domain data access in a distributed environment, providing us with a robust solution for real-time data access and efficient batch processing. This transformation has empowered us to better meet the demands of the digital age, delivering superior customer experiences and reinforcing our commitment to innovation in the financial services industry.
About the authors
© 2025 The Vanguard Group, Inc. All rights reserved.