AWS Big Data Blog
Category: Analytics

ETL and ELT design patterns for lake house architecture using Amazon Redshift: Part 1
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks. Part 1 of this multi-post series discusses design best practices for building scalable ETL (extract, transform, load) and ELT (extract, […]
Matching patient records with the AWS Lake Formation FindMatches transform
Patient matching is a major obstacle in achieving healthcare interoperability. Mismatched patient records and inability to retrieve patient history can cause significant barriers to informed clinical decision-making and result in missed diagnoses or delayed treatments. Additionally, healthcare providers often invest in patient data deduplication, especially when the number of patient records is growing rapidly in […]

Retain more for less with UltraWarm for Amazon OpenSearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Machine-generated data powers solutions and causes problems. It’s indispensable for identifying operational issues in today’s modern software applications, yet you need flexible, scalable tools like Amazon OpenSearch Service to analyze it in real time. This log data is so valuable […]

Highlight the breadth of your data and analytics technical expertise with new AWS Certification beta
AWS offers the broadest set of analytic tools and engines that analyzes data using open formats and open standards. To validate expertise with AWS data analytics solutions, builders can now take the beta for the AWS Certified Data Analytics — Specialty certification. The AWS Certified Data Analytics — Specialty certification validates technical expertise with designing, […]

Extract, Transform and Load data into S3 data lake using CTAS and INSERT INTO statements in Amazon Athena
April 2024: This post was reviewed for accuracy. Amazon Athena is an interactive query service that makes it easy to analyze the data stored in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. You can reduce your per-query […]

Connect Amazon Athena to your Apache Hive Metastore and use user-defined functions
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. This post details the two new preview features that you can start using today: connecting […]
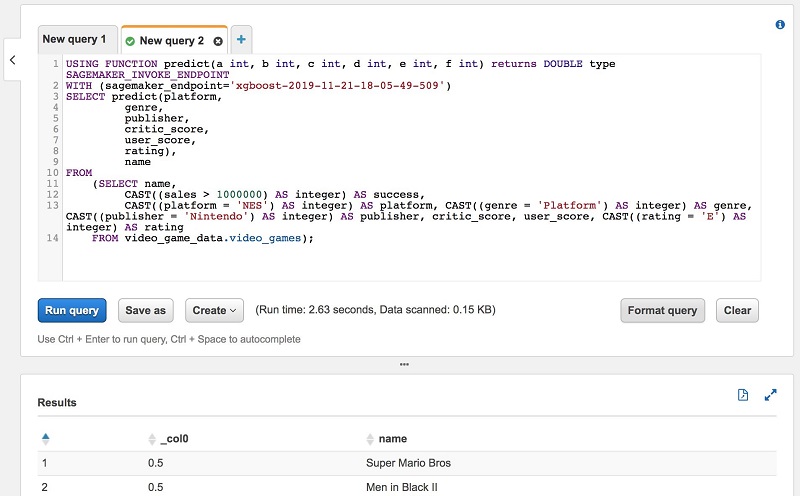
Prepare data for model-training and invoke machine learning models with Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Amazon Athena has announced a public preview of a new feature that provides an easy […]

Query any data source with Amazon Athena’s new federated query
April 2024: This post was reviewed for accuracy. Organizations today use data stores that are the best fit for the applications they build. For example, for an organization building a social network, a graph database such as Amazon Neptune is likely the best fit when compared to a relational database. Similarly, for workloads that require […]
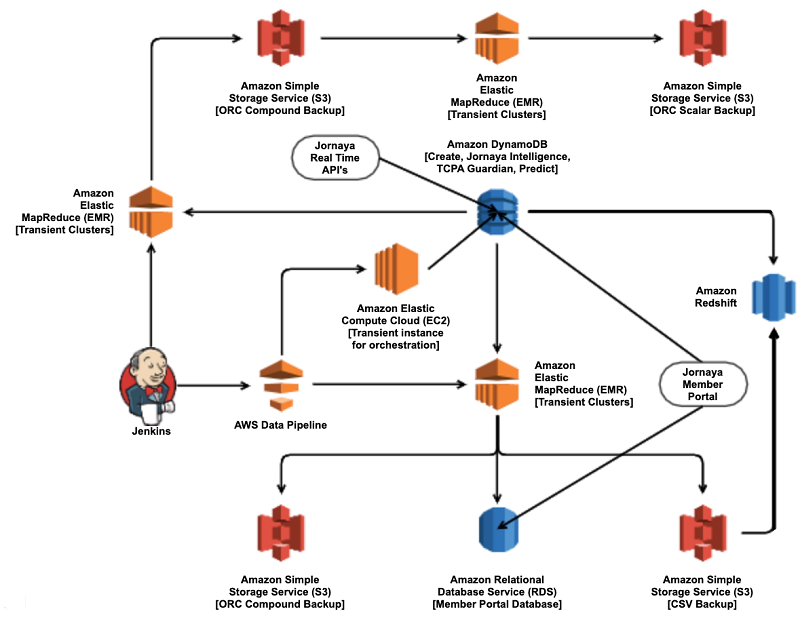
Simplify ETL data pipelines using Amazon Athena’s federated queries and user-defined functions
Amazon Athena recently added support for federated queries and user-defined functions (UDFs), both in Preview. See Query any data source with Amazon Athena’s new federated query for more details. Jornaya helps marketers intelligently connect consumers who are in the market for major life purchases such as homes, mortgages, cars, insurance, and education. Jornaya collects data […]

Highlight Critical Insights with Conditional Formatting in Amazon QuickSight
Amazon QuickSight now makes it easier for you to spot the highlights or low-lights in data through conditional formatting. With conditional formatting, you can specify customized text or background colors based on field values in the dataset, using solid or gradient colors. You can also display data values with the supported icons. Using color coding and […]