AWS Big Data Blog
Simplify ETL data pipelines using Amazon Athena’s federated queries and user-defined functions
Amazon Athena recently added support for federated queries and user-defined functions (UDFs), both in Preview. See Query any data source with Amazon Athena’s new federated query for more details. Jornaya helps marketers intelligently connect consumers who are in the market for major life purchases such as homes, mortgages, cars, insurance, and education.
Jornaya collects data from a variety of data sources. Our main challenge is to clean and ingest this data into Amazon S3 to enable access for data analysts and data scientists.
Legacy ETL and analytics solution
In 2012, Jornaya moved from using from MySQL to Amazon DynamoDB for our real-time database. DynamoDB allowed a company of our size to receive the benefits of create, read, update, and delete (CRUD) operations with predictable low latency, high availability, and excellent data durability without the administrative burden of having to manage the database. This allowed our technology team to focus on solving business problems and rapidly building new products that we could bring to market.
Running analytical queries on NoSQL databases can be tough. We decided to extract data from DynamoDB and run queries on it. This was not simple.
Here are a few methods we use at Jornaya to get data from DynamoDB:
- Leveraging EMR: We temporarily provision additional read capacity with DynamoDB tables and create transient EMR clusters to read data from DynamoDB and write to Amazon S3.
- Our Jenkins jobs trigger pipelines that spin up a cluster, extract data using EMR, and use the Amazon Redshift copy command to load data into Amazon Redshift. This is an expensive process because we use excess read capacity. To lower EMR costs, we use spot instances.
- Enabling DynamoDB Streams: We use a homegrown Python AWS Lambda function named Dynahose to consume data from the stream and write it to a Amazon Kinesis Firehose delivery stream. We then configure the Kinesis Firehose delivery stream to write the data to an Amazon S3 location. Finally, we use another homegrown Python Lambda function named Partition to ensure that the partitions corresponding to the locations of the data written to Amazon S3 are added to the AWS Glue Data Catalog so that it can read using tools like AWS Glue, Amazon Redshift Spectrum, EMR, etc.
The process is shown in the following diagram.
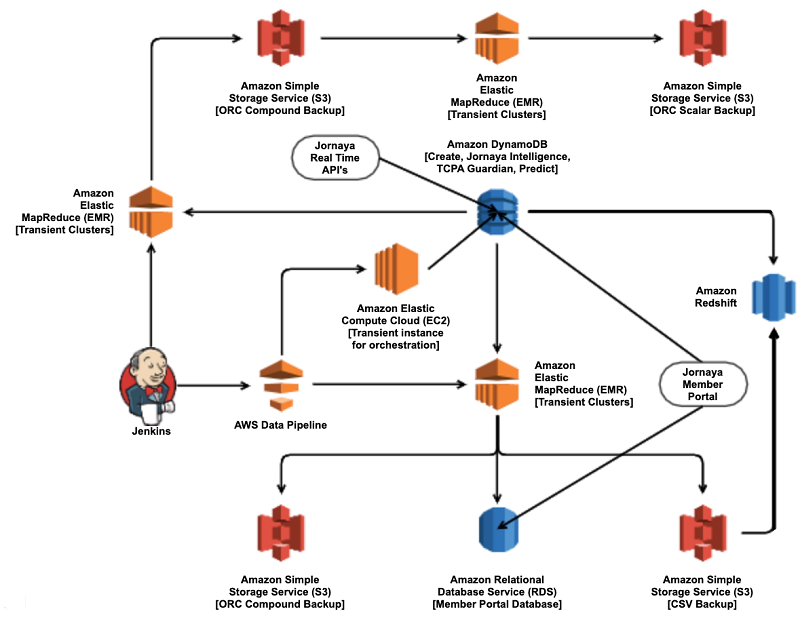
We go through such pipelines because we want to ask questions about our operational data in a natural way, using SQL.
Using Amazon Athena to simplify ETL workflows and enable quicker analytics
Athena, a fully managed serverless interactive service for querying data in Amazon S3 using SQL, has been rapidly adopted by multiple departments across our organization. For our use case, we did not require an always-on EMR cluster waiting for an analytics query. Athena’s serverless nature is perfect for our use case. Along the way we discovered that we could use Athena to run extract, transform, and load (ETL) jobs.
However, Athena is a lot more than an interactive service for querying data in Amazon S3. We also found Athena to be a robust, powerful, reliable, scalable, and cost-effective ETL tool. The ability to schedule SQL statements, along with support for Create Table As Select (CTAS) and INSERT INTO statements, helped us accelerate our ETL workloads.
Before Athena, business users in our organization had to rely on engineering resources build pipelines. The release of Athena changed that in a big way. Athena enabled software engineers and data scientists to work with data that would have otherwise been inaccessible or required help from data engineers.
With the addition of query federation and UDFs to Athena, Jornaya has been able to replace many of our unstable data pipelines with Athena to extract and transform data from DynamoDB and write it to Amazon S3. The product and engineering teams at Jornaya noticed our reduced ETL failure rates. The finance department took note of lower EMR and DynamoDB costs, and the members of our on-call rotation (as well as their spouses) have been able to enjoy uninterrupted sleep.
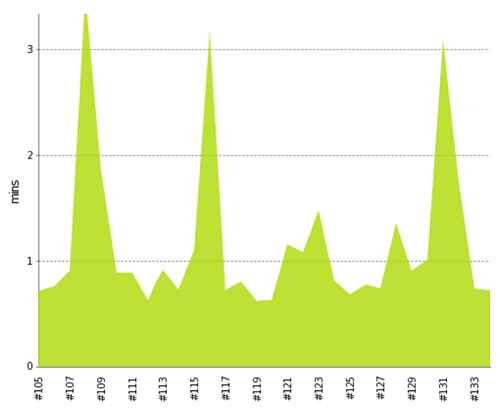
For instance, the build history of one ETL pipeline using EMR looked like this (the history of ETL pipeline executions is shown in this chart with the job execution id on the x-axis and the execution time in minutes on the y-axis):

After migrating this pipeline to Athena and using federated queries to query DynamoDB, we were able to access data sources with ease that we simply could not previously with queries like the following:
We achieved a much more performant process with a build history shown in the following diagram:
Conclusion
Using one SQL query, we were able to process data from DynamoDB, convert that data to Parquet, apply Snappy compression, create the correct partitions in our AWS Glue Data Catalog, and ingest data to Amazon S3. Our ETL process execution time was reduced from hours to minutes, the cost was significantly lowered, and the new process is simpler and much more reliable. The new process using Athena for ETL is also future-proof due to extensibility. In case we need to import a dataset from another purpose-built data store that does not have a ready data source connector, we can simply use the data source connector SDK to write our own connector and deploy it in Production—a one-time effort that will cost us barely one day.
Additionally, Athena federated queries have empowered Jornaya to run queries that connect data from not just different data sources, but from different data paradigms! We can run a single query that seamlessly links data from a NoSQL datastore, an RDS RDBMS, and an Amazon S3 data lake.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
 Manny Wald is the technical co-founder at Jornaya. He holds multiple patents and is passionate about the power of the cloud, big data and AI to accelerate the rate at which companies can bring products to market to solve real-world problems. He has a background in BI, application development, data warehousing, web services, and building tools to manage transactional and analytical information. Additionally, Manny created the internet’s first weekly hip hop turntablism mix show, is admitted to practice law at the state and federal levels, and plays basketball whenever he gets the chance.
Manny Wald is the technical co-founder at Jornaya. He holds multiple patents and is passionate about the power of the cloud, big data and AI to accelerate the rate at which companies can bring products to market to solve real-world problems. He has a background in BI, application development, data warehousing, web services, and building tools to manage transactional and analytical information. Additionally, Manny created the internet’s first weekly hip hop turntablism mix show, is admitted to practice law at the state and federal levels, and plays basketball whenever he gets the chance.
 Janak Agarwal is a product manager for Athena at AWS.
Janak Agarwal is a product manager for Athena at AWS.