AWS Big Data Blog
Category: Amazon EC2

Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container
Mar 2025: This post was written for AWS Glue 3.0 and 4.0. For AWS Glue 5.0, visit Develop and test AWS Glue 5.0 jobs locally using a Docker container. Apr 2023: This post was reviewed and updated with enhanced support for Glue 4.0 Streaming jobs. Jan 2023: This post was reviewed and updated with enhanced […]

Estimate Amazon EC2 Spot Instance cost savings with AWS Glue DataBrew, AWS Glue, and Amazon QuickSight
AWS provides many ways to optimize your workloads and save on costs. For example, services like AWS Cost Explorer and AWS Trusted Advisor provide cost savings recommendations to help you optimize your AWS environments. However, you may also want to estimate cost savings when comparing Amazon Elastic Compute Cloud (Amazon EC2) Spot to On-Demand Instances. […]
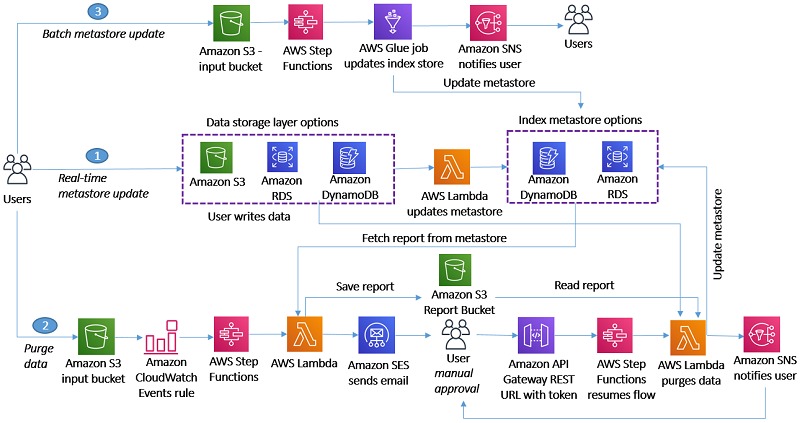
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]

Power from wind: Open data on AWS
Data that describe processes in a spatial context are everywhere in our day-to-day lives and they dominate big data problems. Map data, for instance, whether describing networks of roads or remote sensing data from satellites, get us where we need to go. Atmospheric data from simulations and sensors underlie our weather forecasts and climate models. […]
Best Practices for Running Apache Cassandra on Amazon EC2
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case.