AWS Big Data Blog
Category: Advanced (300)

Automating data classification in Amazon SageMaker Catalog using an AI agent
If you’re struggling with manual data classification in your organization, the new Amazon SageMaker Catalog AI agent can automate this process for you. Most large organizations face challenges with the manual tagging of data assets, which doesn’t scale and is unreliable. In some cases, business terms aren’t applied consistently across teams. Different groups name and tag data assets based on local conventions. This creates a fragmented catalog where discovery becomes unreliable and governance teams spend more time normalizing metadata than governing. In this post, we show you how to implement this automated classification to help reduce the manual tagging effort and improve metadata consistency across your organization.
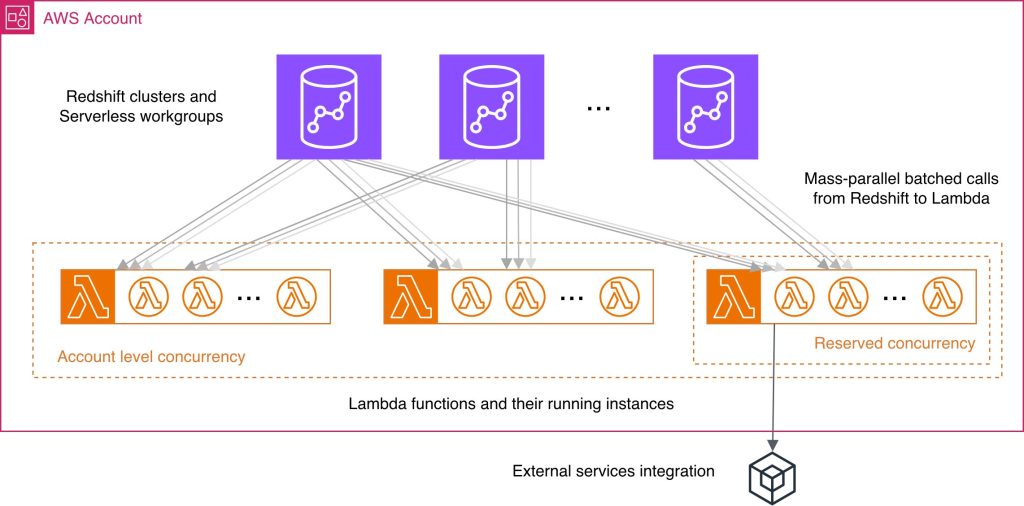
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.

Building a scalable, transactional data lake using dbt, Amazon EMR, and Apache Iceberg
Growing data volume, variety, and velocity has made it crucial for businesses to implement architectures that efficiently manage and analyze data, while maintaining data integrity and consistency. In this post, we show you a solution that combines Apache Iceberg, Data Build Tool (dbt), and Amazon EMR to create a scalable, ACID-compliant transactional data lake. You can use this data lake to process transactions and analyze data simultaneously while maintaining data accuracy and real-time insights for better decision-making.
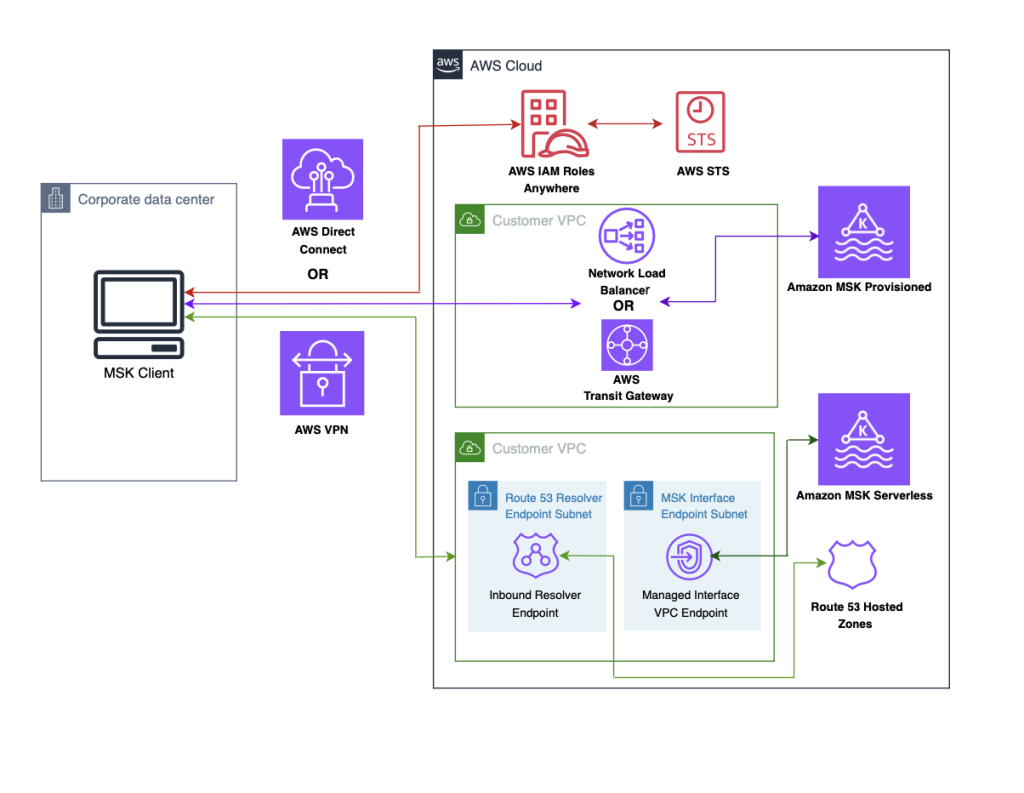
Securely connect Kafka clients running outside AWS to Amazon MSK with IAM Roles Anywhere
In this post, we demonstrate how to use AWS IAM Roles Anywhere to request temporary AWS security credentials, using x.509 certificates for client applications which enables secure interactions with an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster. The solution described in this post is compatible with both Amazon MSK Provisioned and Serverless clusters.

How Razorpay achieved 11% performance improvement and 21% cost reduction with Amazon EMR
In this post, we explore how Razorpay, India’s leading FinTech company, transformed their data platform by migrating from a third-party solution to Amazon EMR, unlocking improved performance and significant cost savings. We’ll walk through the architectural decisions that guided this migration, the implementation strategy, and the measurable benefits Razorpay achieved.

How Amplitude implemented natural language-powered analytics using Amazon OpenSearch Service as a vector database
Amplitude is a product and customer journey analytics platform. Our customers wanted to ask deep questions about their product usage. Ask Amplitude is an AI assistant that uses large language models (LLMs). It combines schema search and content search to provide a customized, accurate, low latency, natural language-based visualization experience to end customers. Amplitude’s search architecture evolved to scale, simplify, and cost-optimize for our customers, by implementing semantic search and Retrieval Augmented Generation (RAG) powered by Amazon OpenSearch Service. In this post, we walk you through Amplitude’s iterative architectural journey and explore how we address several critical challenges in building a scalable semantic search and analytics platform.

Set up production-ready monitoring for Amazon MSK using CloudWatch alarms
In this post, I show you how to implement effective monitoring for your Kafka clusters using Amazon MSK and Amazon CloudWatch. You’ll learn how to track critical metrics like broker health, resource utilization, and consumer lag, and set up automated alerts to prevent operational issues.
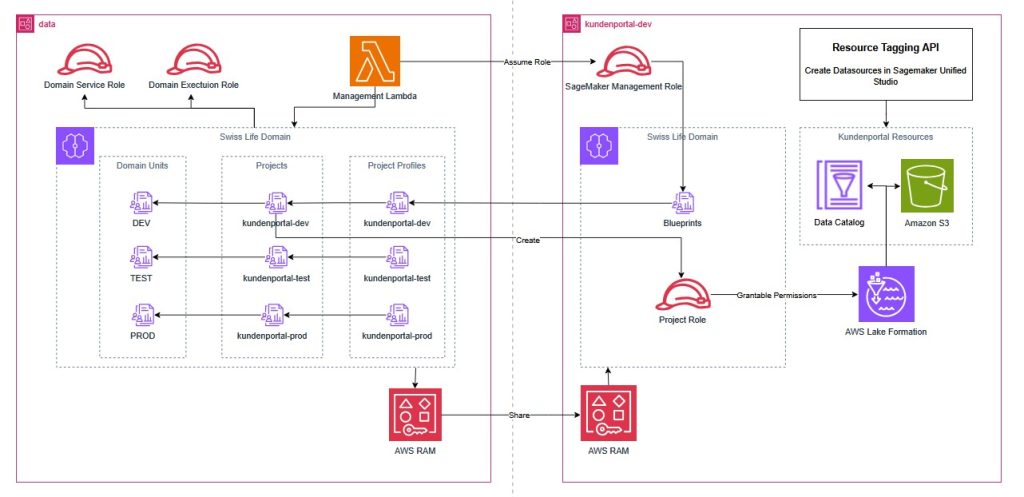
How Swiss Life Germany automated data governance and collaboration with Amazon SageMaker
Swiss Life Germany, a leading provider of customized pension products with over 100 years of experience, recently transitioned from legacy on-premises infrastructure to a modern cloud architecture. To enable secure data sharing and cross-departmental collaboration in this regulated environment, they implemented Amazon SageMaker with a custom Terraform pattern. This post demonstrates how Swiss Life Germany aligned SageMaker’s agility with their rigorous infrastructure as code standards, providing a blueprint for platform engineers and data architects in highly regulated enterprises.

Implement a data mesh pattern in Amazon SageMaker Catalog without changing applications
In this post, we walk through simulating a scenario based on data producer and data consumer that exists before Amazon SageMaker Catalog adoption. We use a sample dataset to simulate existing data and an existing application using an AWS Lambda function, then implement a data mesh pattern using Amazon SageMaker Catalog while keeping your current data repositories and consumer applications unchanged.
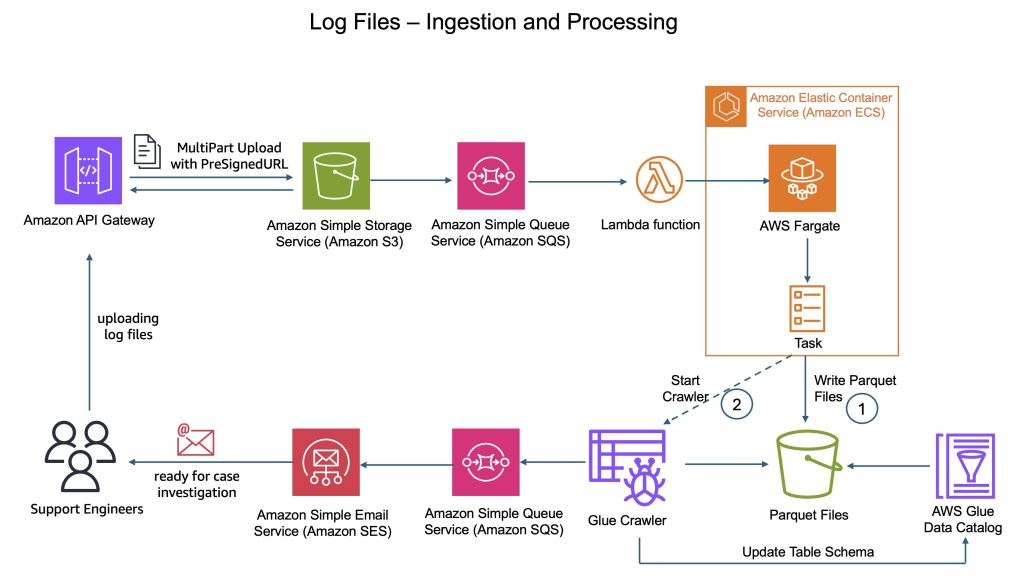
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.