AWS Big Data Blog
How Pagely implemented a serverless data lake in AWS to facilitate customer support analytics
Pagely is an AWS Advanced Technology Partner providing managed WordPress hosting services. Our customers continuously push us to improve visibility into usage, billing, and service performance. To better serve these customers, the service team requires an efficient way to access the logs created by the application servers.
Historically, we relied on a shell script that gathered basic statistics on demand. When processing the logs for our largest customer, it took more than 8 hours to produce one report using an unoptimized process running on an Amazon EC2 instance—sometimes crashing due to resource limitations. Instead of putting more effort into fixing a legacy process, we decided it was time to implement a proper analytics platform.
All of our customer logs are stored in Amazon S3 as compressed JSON files. We use Amazon Athena to run SQL queries directly against these logs. This approach is great because there is no need for us to prepare the data. We simply define the table and query away. Although JSON is a supported format for Amazon Athena, it is not the most efficient format for use with regards to performance and cost. JSON files must be read in their entirety, even if you are only returning one or two fields from each row of data, resulting in scanning more data than is required. Additionally, the inefficiencies of processing JSON cause longer query times.
Querying the logs of our largest customers was not ideal with Athena, as we ran into the 30-minute query timeout limit. This limit can be increased, but the query was already taking longer than we wanted.
In this post, we discuss how Pagely worked with Beyondsoft, an AWS Advanced Consulting Partner, to use ConvergDB, an open-source tool developed by Beyondsoft, to build a DevOps-centric data pipeline. This pipeline uses AWS Glue to transform application logs into optimized tables that can be queried quickly and cost effectively using Amazon Athena.
Engaging Beyondsoft
We knew that we needed to do something to make our data easily accessible to our engineers with as little overhead as possible. We wanted to get the data into a more optimal file format to reduce query times. Being a lean shop, we didn’t have the bandwidth to dive into the technologies. To bridge the gap, we engaged Beyondsoft to determine the best solution to optimize and better manage our data lake.
What is ConvergDB?
ConvergDB is open-source software for the creation and management of data lakes. Users define the structure of the source and target tables and map them to concrete cloud resources. Then ConvergDB creates all of the scripts used to build and manage the necessary resources in AWS. The scripts created by ConvergDB are deployed through the use of HashiCorp Terraform, an open-source tool for managing infrastructure as code.
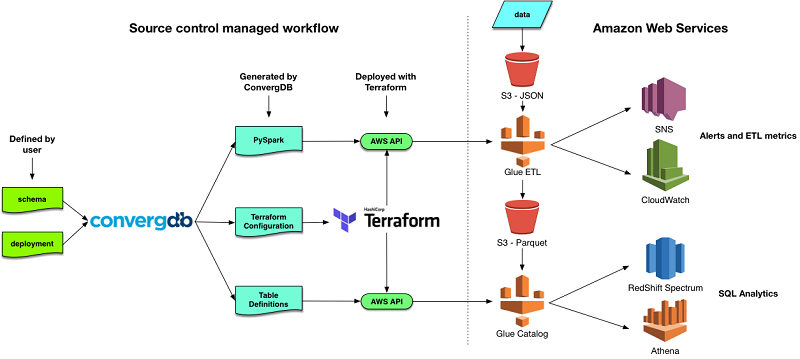
With ConvergDB, we can define our data lake with metadata to drive the table-creation and ETL (extract, transform, and load) processes. The schema files are used to define tables, including field-level SQL expressions that are used to transform the incoming data as it is being loaded. These expressions are used to derive calculated fields, in addition to the fields that are used for data partitioning.
After the schema is defined, the deployment file allows us to place the tables into an ETL job that is used to manage them. The ETL job schedule is specified in the deployment file and in optional fields such as the target S3 bucket and number of AWS Glue DPUs to use at runtime.
ConvergDB is a command line binary and does not need to be installed on a server. All of the artifacts are files that can be managed using source control. The ConvergDB binary takes in all the configuration files and then outputs a Terraform configuration containing all the artifacts necessary to deploy the data lake. These artifacts can be ETL scripts, table and database definitions, and IAM policies necessary to run the jobs. They can also include Amazon SNS notification topics, and even an Amazon CloudWatch dashboard showing the volume of data processed by ConvergDB ETL jobs.
Speed bumps
No implementation goes perfectly. In the following sections, Jeremy Winters, a Beyondsoft engineer, explains the problems we ran into and how they were addressed.
Partitioning and columnar formats
Two of the key best practices for structuring data for SQL analytic queries in Amazon S3 are partitioning and columnar file structure.
Partitioning is the process of splitting data into different prefixes or folders on S3 with a naming convention that’s most suitable to efficient retrieval of data. This allows Athena to skip over data that is not relevant to the particular query that is being executed.
Apache Parquet is a columnar format popular with tools in the Hadoop ecosystem. Parquet stores the columns of the data in separate, contiguous regions in the file. Directed by metadata footers, tools like Athena read only the sections of the file that are needed to fulfill the query. This process helps eliminate a large portion of I/O and network data transfer.
Reducing I/O through partitioning and Parquet files not only increases query performance, but it dramatically reduces the cost of using Athena.
For more information about best practices for data lake optimization, see the blog post Top 10 Performance Tuning Tips for Amazon Athena.
Small files problem
A classic issue encountered with Hadoop ecosystem tools is known as the “small files problem.” Processing a large number of small files creates a lot of overhead for the system, causing job execution times to skyrocket and potentially fail. Pagely had approximately 4 TB of history across 30 million files. Of these files, 29.5 million represented only 1.2 TB of the data in S3.
To analyze this issue, we enabled S3 inventory reporting on the source data bucket. The report is delivered daily in an ORC (optimized row columnar) format. From there, it is very easy to create an Athena table to analyze the bucket contents using SQL.
We used Athena to identify S3 prefixes that were “hot spots,” that is, those having a large number of small files. We identified 14,000 prefixes with less than 1 GB of data that we could consolidate. So… 29.5 million files consolidated into 14,000 files.
The following query is a way to identify small-file hot spots. The GROUP BY expression can be suited to your data. The example shows a way of grouping by the first “folder” in the bucket.
The results show prefixes in your object paths that can and should be consolidated. Anything less than 1 GB with more than eight files can then be consolidated into a single object, replacing the originals.

After the hot spots are identified, the small files must be consolidated. The results in the preceding image show that files with a prefix of 14184 total 33.7 MB spread across 502 files. To reduce the overhead of this many small files, we combine all of the files into a single file. Our files use gzip compression, which allows for combining them through simple concatenation, as opposed to decompressing, concatenating the raw JSON data, and then recompressing. There are many ways to achieve this, such as the Linux cat command, which is shown in the following example:
You can run these commands on any gzip files, and then test that the resulting file is a valid gzip by using the -d flag, which decompresses the file for you. For some use cases, you can use the Amazon S3 Multipart Copy API, but this approach requires that your small files be at least 5 MB in size.
For the Pagely dataset, we wrote a shell script to pull down all the files with a given prefix, concatenate them into a single gzip, upload the concatenated file, validate the upload, and then delete the smaller files. This script was run using AWS Fargate containers, each of which would handle a single prefix. The details of this process would be a blog post on its own, but using a service like AWS Batch can make a job like this easier to manage. The total cost of concatenating all of the small historical files was $27.
Historical data
Daily data volumes for Pagely logs are in the tens of gigabytes per day, easily handled by the smallest AWS Glue configuration. Transforming the 4 TB of compressed (~28 TB uncompressed) historical data was a bit more challenging.
ConvergDB batches the data into smaller chunks. In the case of a very long-running historical transformation job failing, only the last batch is lost, resulting in around one hour of compute being lost. ConvergDB uses its own state-tracking mechanism to communicate the failure to the next run of the job, which cleans up any mess before trying to process the batch again. Batching is an automatic feature of the ETL job created by ConvergDB, based upon the size of the AWS Glue cluster.
Post-deployment at Pagely
Running our legacy report for a medium-size application (several gigabytes in S3) took 91 seconds. Now that our data lake is in production, the same report for a medium-size application takes 5 seconds with Athena—an 18x performance gain. Our largest dataset (~1 TB in S3) fails with our legacy process. It’s also not sufficiently performant when querying the raw JSON directly with Athena. However, the new Parquet-based tables using Athena complete the analysis in 24 seconds.
| Legacy process | Athena with JSON | Athena with Parquet | |
| Medium customer | 1 minute, 31 seconds | 1 minute | 6 seconds |
| Largest customer | > 8 hours | > 30 minutes | 24 seconds |
Although these numbers are obviously important, the biggest advantage is that now we don’t have to worry about performance and cost, and the engineers can focus on solving problems. Just 15 minutes of writing queries, and the entire team now has access to new data. I was able to upgrade the legacy process with queries dispatched to Athena through the AWS SDK. This process can now run on any lightweight machine (like my laptop) while Athena does the heavy lifting.
About Pagely
Pagely, in their own words: Pagely is an AWS Advanced Technology, SaaS, and Public Sector Partner providing managed WordPress hosting. We service enterprise-level customers like BMC, UNICEF, Northwestern University, and the City of Boston, offering flexibility in our solutions and the industries best expert-only, tier-less support. Pagely uses a proprietary tech stack that accelerates WordPress sites through the use of our own ARES™ Web Application gateway, PressCACHE™ and PressCDN™ technologies, and open source tools such as Redis and NGINX.
About Beyondsoft Consulting, Inc.
Beyondsoft Consulting, Inc., in their own words: Beyondsoft Consulting, Inc. is an Amazon Web Services Advanced Consulting Partner with delivery centers across the US and Asia. Beyondsoft delivers IT solutions and services to leading technology companies and enterprises across many verticals. Our team of highly skilled professionals, coupled with our focus on customer success, truly separate us as a preferred AWS Partner for many of our clients.
Beyondsoft Amazon Partner Page
If you have questions or suggestions, please comment below.
Additional Reading
If you found this post useful, be sure to check out Build a Data Lake Foundation with AWS Glue and Amazon S3 and Work with partitioned data in AWS Glue.
About the Authors
 Joshua Eichorn is CTO of Pagely. An engineering leader with experience leading small and large teams. As an individual contributor, manager, and director he has done it all, from writing line one on a new application to a 6 month rewrite of a massive site. Josh loves solving new challenges and building great products.
Joshua Eichorn is CTO of Pagely. An engineering leader with experience leading small and large teams. As an individual contributor, manager, and director he has done it all, from writing line one on a new application to a 6 month rewrite of a massive site. Josh loves solving new challenges and building great products.
 Jeremy Winters is the creator of ConvergDB, and has been working in Business Intelligence across a variety of industries for 18 years, with the past 8 years being focused on building data lakes, data warehouses, and other applications in AWS.
Jeremy Winters is the creator of ConvergDB, and has been working in Business Intelligence across a variety of industries for 18 years, with the past 8 years being focused on building data lakes, data warehouses, and other applications in AWS.