AWS Big Data Blog
Improve Amazon Athena query performance using AWS Glue Data Catalog partition indexes
The AWS Glue Data Catalog provides partition indexes to accelerate queries on highly partitioned tables. In the post Improve query performance using AWS Glue partition indexes, we demonstrated how partition indexes reduce the time it takes to fetch partition information during the planning phase of queries run on Amazon EMR, Amazon Redshift Spectrum, and AWS Glue extract, transform, and load (ETL) jobs.
We’re pleased to announce Amazon Athena support for AWS Glue Data Catalog partition indexes. You can use the same indexes configured for Amazon EMR, Redshift Spectrum, and AWS Glue ETL jobs with Athena to reduce query planning times for highly partitioned tables, which is common in most data lakes on Amazon Simple Storage Service (Amazon S3).
In this post, we describe how to set up partition indexes and perform a few sample queries to demonstrate the performance improvement on Athena queries.
Set up resources with AWS CloudFormation
To help you get started quickly, we provide an AWS CloudFormation template, the same template we used in a previous post. You can review and customize it to suit your needs. Some of the resources this stack deploys incur costs when in use.
The CloudFormation template generates the following resources:
- AWS Identity and Access Management (IAM) users, roles, and policies
- AWS Glue Data Catalog database, tables, and partitions
If you’re using AWS Lake Formation permissions, you need to make sure that the IAM user or role running AWS CloudFormation has the required permissions to create a database on the AWS Glue Data Catalog.
The tables created by the CloudFormation template use sample data located in an S3 public bucket. The data is partitioned by the columns year, month, day, and hour. There are 367,920 partition folders in total, and each folder has a single file in JSON format that contains an event similar to the following:
To create your resources, complete the following steps:
- Sign in to the AWS CloudFormation console.
- Choose Launch Stack:

- Choose Next.
- For DatabaseName, leave as the default.
- Choose Next.
- On the next page, choose Next.
- Review the details on the final page and select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create.
Stack creation can take up to 5 minutes. When the stack is complete, you have two Data Catalog tables: table_with_index and table_without_index. Both tables point to the same S3 bucket, as mentioned previously, which holds data for more than 42 years (1980–2021) in 367,920 partitions. Each partition folder includes a data.json file containing the event data. In the following sections, we demonstrate how the partition indexes improve query performance with these tables using an example that represents large datasets in a data lake.
Set up partition indexes
You can create up to three partition indexes per table for new and existing tables. If you want to create a new table with partition indexes, you can include a list of PartitionIndex objects with the CreateTable API call. To add a partition index to an existing table, use the CreatePartitionIndex API call. You can also perform these actions from the AWS Glue console.
Let’s configure a new partition index for the table table_with_index we created with the CloudFormation template.
- On the AWS Glue console, choose Tables.
- Choose the table
table_with_index. - Choose Partitions and indices.
- Choose Add new index.
- For Index name, enter
year-month-day-hour. - For Selected keys from schema, select year, month, day, and hour. Make that you choose each column in this order, and confirm that Partition key for each column is correctly configured as follows:
year: Partition (0)month: Partition (1)day: Partition (2)hour: Partition (3)
- Choose Add index.
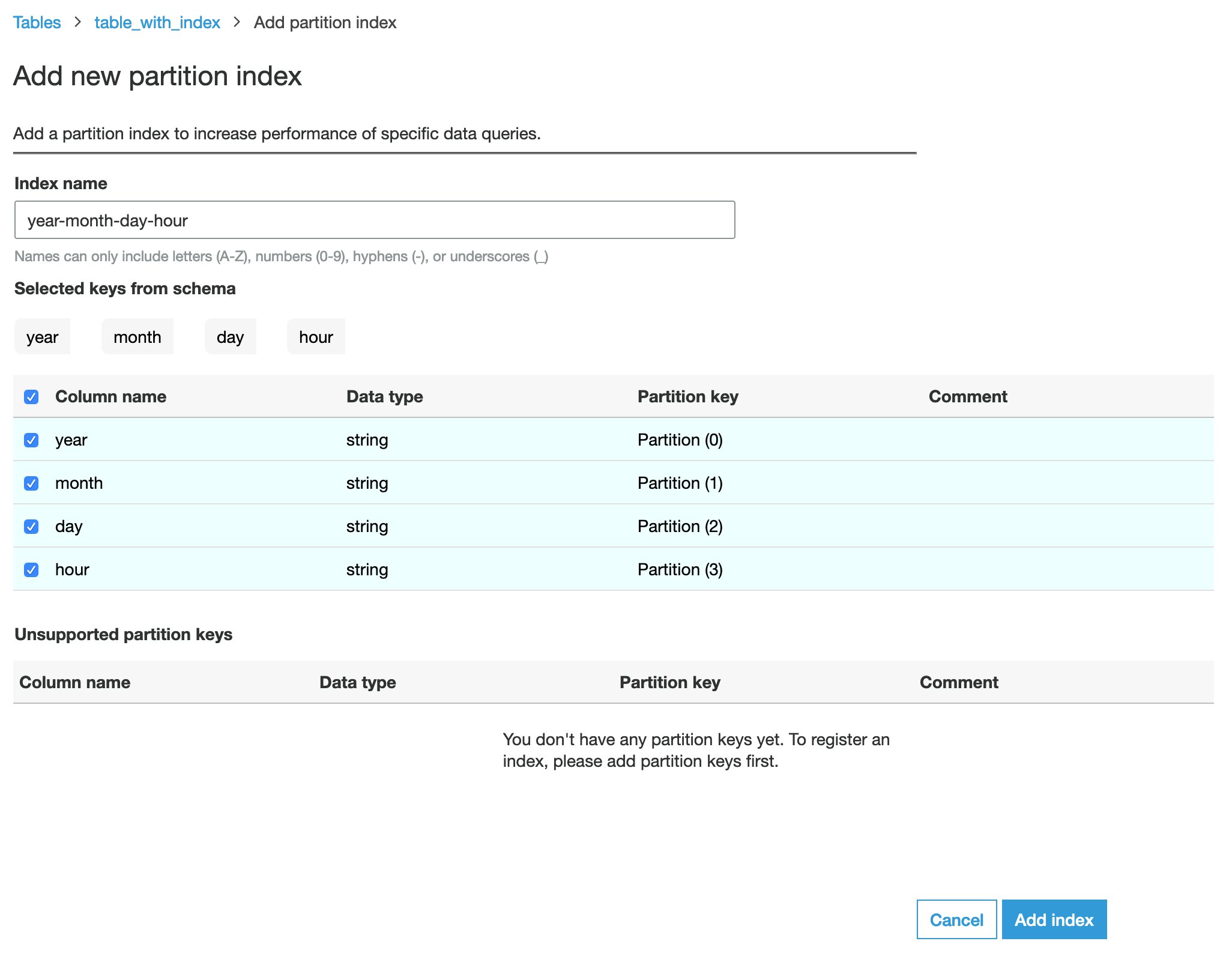
The Status column of the newly created partition index shows as Creating. We need to wait for the partition index to be Active before it can be used by query engines. It should take about 1 hour to process and build the index for 367,920 partitions.

When the partition index is ready for table_with_index, you can use it when querying with Athena. For table_without_index, you should expect to see no change in query latency because no partition indexes were configured.
Enable partition filtering
To enable partition filtering in Athena, you need to update the table properties as follows:
- On the AWS Glue console, choose Tables.
- Choose the table
table_with_index. - Choose Edit table.
- Under Table properties, add the following:
- Key –
partition_filtering.enabled - Value –
true
- Key –
- Choose Apply.

Alternatively, you can set this parameter by running an ALTER TABLE SET PROPERTIES query in Athena:
Query tables using Athena
Now that your table has filtering enabled for Athena, let’s query both tables to see the performance differences.
First, query the table without using the partition index. In the Athena query editor, enter the following query:
The following screenshot shows the query took 44.9 seconds.

Next, query the table with using the partition index. You need to use the columns that are configured for the indexes in the WHERE clause to gain these performance benefits. Run the following query:
The following screenshot shows the query took just 1.3 seconds to complete, which is significantly faster than the table without indexes.
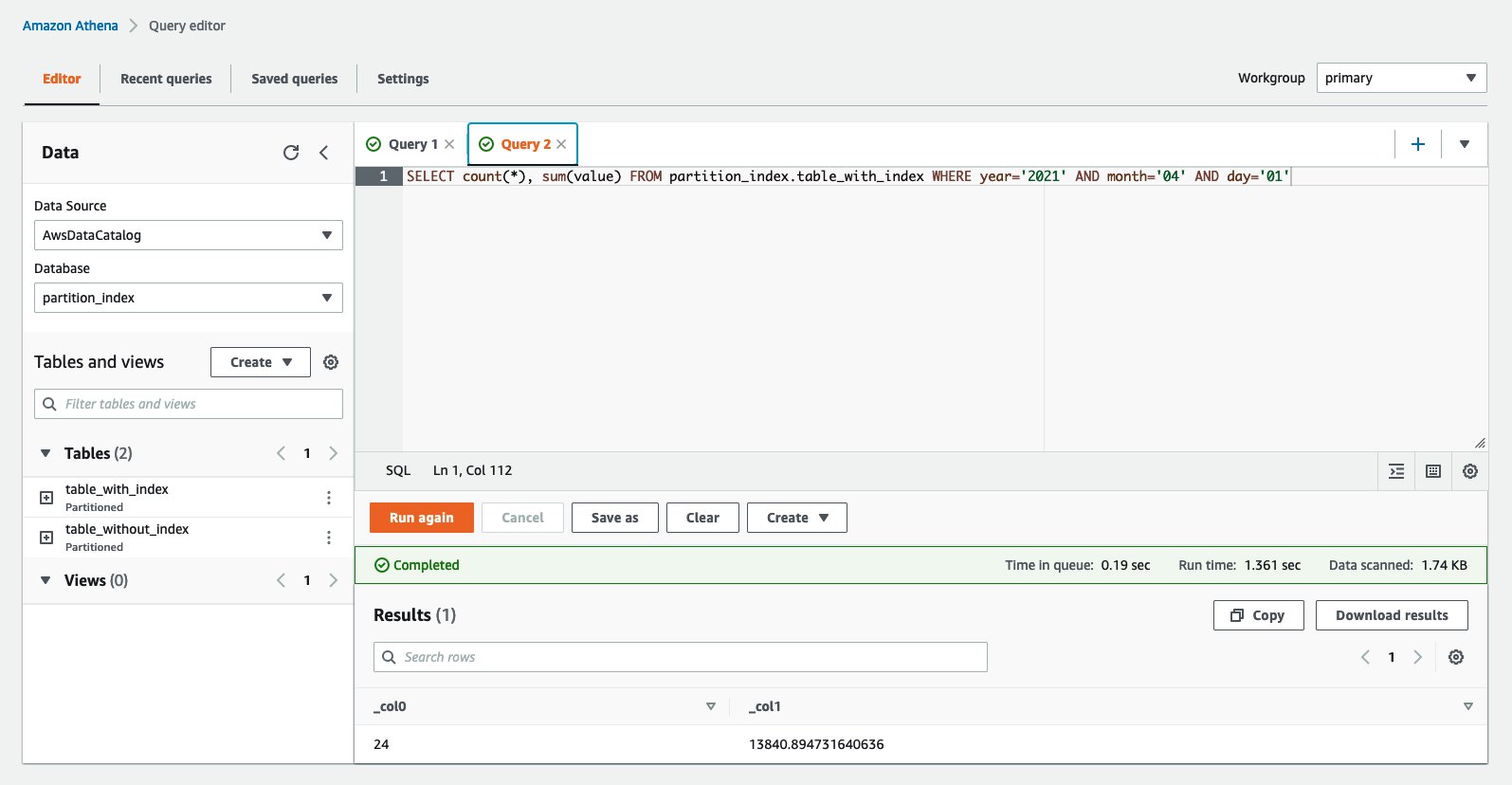
Query planning is the phase where the table and partition metadata are fetched from the AWS Glue Data Catalog. With partition indexes enabled, retrieving only the partitions required by the query can be done more efficiently and therefore quicker. Let’s retrieve the execution details of each query by using the AWS Command Line Interface (AWS CLI) to compare planning statistics.
The following is the query execution details for the query that ran against a table without partition indexes:
The following is the query execution details for a query that ran against a table with partition indexes:
QueryPlanningTimeInMillis represents the number of milliseconds that Athena took to plan the query processing flow. This includes the time spent retrieving table partitions from the data source. Because the query engine performs the query planning, the query planning time is a subset of engine processing time.
Comparing the stats for both queries, we can see that QueryPlanningTimeInMillis is significantly lower in the query using partition indexes. It went from 44 seconds to 0.3 seconds when using partition indexes. The improvement in query planning resulted in a faster overall query runtime, going from 45 seconds to 1.3 seconds—a 35 times greater performance improvement.
Clean up
Now to the final step, cleaning up the resources:
- Delete the CloudFormation stack.
- Confirm both tables have been deleted from the AWS Glue Data Catalog.
Conclusion
At AWS, we strive to improve the performance of our services and our customers’ experience. The AWS Glue Data Catalog is a fully managed, Apache Hive compatible metastore that enables a wide range of big data, analytics, and machine learning services, like Athena, Amazon EMR, Redshift Spectrum, and AWS Glue ETL, to access data in the data lake. Athena customers can now further reduce query latency by enabling partition indexes for your tables in Amazon S3. Using partition indexes can improve the efficiency of retrieving metadata for highly partitioned tables ranging in the tens and hundreds of thousands and millions of partitions.
You can learn more about AWS Glue Data Catalog partition indexes in Working with Partition Indexes, and more about Athena best practices in Best Practices When Using Athena with AWS Glue.
About the Author
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data platforms, diving deep into distributed big data software like Apache Spark, building reusable software artifacts for data lakes, and sharing the knowledge in AWS Big Data blog posts. In his spare time, he enjoys having and watching killifish, hermit crabs, and grubs with his children.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data platforms, diving deep into distributed big data software like Apache Spark, building reusable software artifacts for data lakes, and sharing the knowledge in AWS Big Data blog posts. In his spare time, he enjoys having and watching killifish, hermit crabs, and grubs with his children.