AWS Big Data Blog

Bill.com uses Amazon QuickSight to enable users with secure and governed enterprise BI
Bill.com is a leading provider of cloud-based software that simplifies, digitizes, and automates back-office financial processes for small and mid-size businesses. Bill.com helps businesses streamline their financial workflow, generate and process invoices, stream approvals, send and receive payments, sync with their accounting systems, and manage their cash. It connects businesses from all industries, ranging from […]
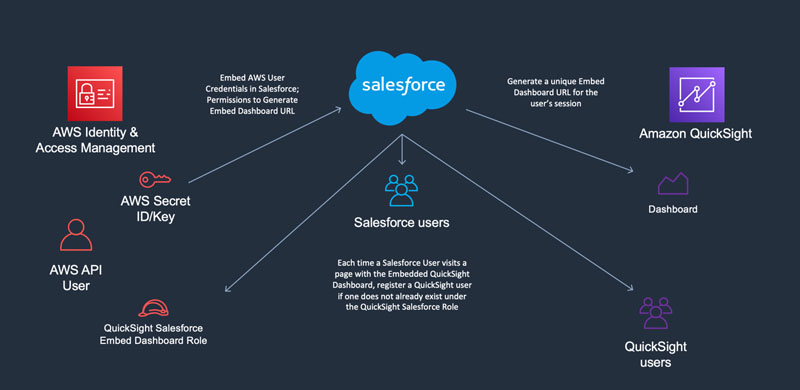
Embed Amazon QuickSight dashboards in Salesforce
January 2023: This post was reviewed and updated for accuracy. Amazon QuickSight is a fast, cloud-powered, business intelligence (BI) service that makes it easy to deliver insights to everyone in your organization. With the QuickSight Enterprise edition, you can also embed the QuickSight dashboard into a webpage or your custom application. Salesforce is an AWS […]

Build Slowly Changing Dimensions Type 2 (SCD2) with Apache Spark and Apache Hudi on Amazon EMR
April 2024: This post was reviewed for accuracy. Organizations across the globe are striving to improve the scalability and cost efficiency of the data warehouse. Offloading data and data processing from a data warehouse to a data lake empowers companies to introduce new use cases like ad hoc data analysis and AI and machine learning […]
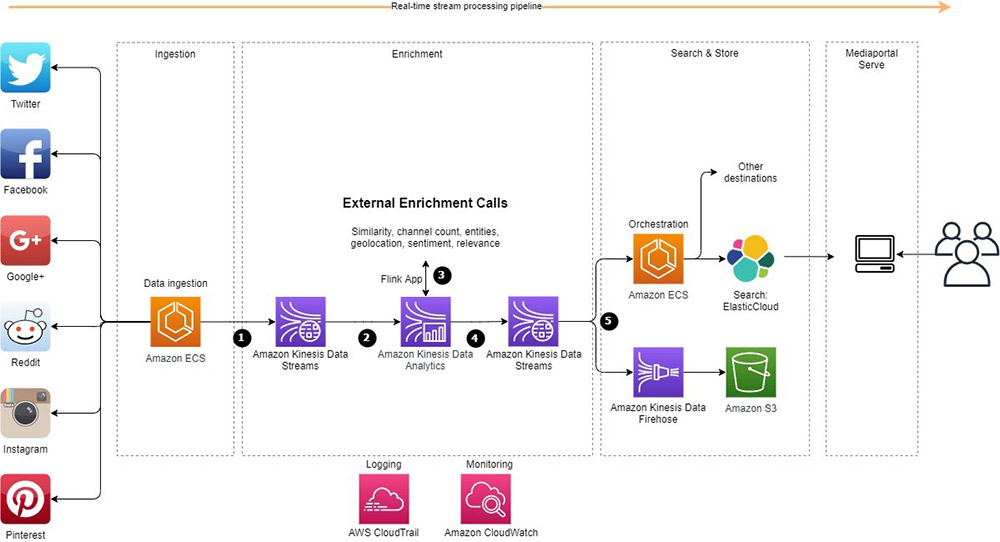
How Isentia improves customer experience by modernizing their real-time media monitoring and intelligence platform with Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This is a blog post co-written by Karl Platz at Isentia. In their own words, “Isentia is the leading media monitoring, intelligence and insights solution provider in […]

Build seamless data streaming pipelines with Amazon Kinesis Data Streams and Amazon Data Firehose for Amazon DynamoDB tables
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. The global wearables market […]

Migrate data into Amazon ES using remote reindex
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Amazon OpenSearch Service recently launched support for remote reindexing. This feature adds the ability to copy data to an Amazon OpenSearch Service domain from self-managed Elasticsearch running on-premises, self-managed on Amazon Elastic Compute Cloud (Amazon EC2) on AWS, or another […]

Enable private access to Amazon Redshift from your client applications in another VPC
November 2023: This post was reviewed and updated to include configurations and options for Amazon Redshift Serverless. You can now use an Amazon Redshift-managed VPC endpoint (powered by AWS PrivateLink) to connect to your private Amazon Redshift cluster with the RA3-instance type or Amazon Redshift Serverless within your virtual private cloud (VPC). With an Amazon […]

Extract multidimensional data from Microsoft SQL Server Analysis Services using AWS Glue
AWS Glue is fully managed service that makes it easier for you to extract, transform, and load (ETL) data for analytics. You can easily create ETL jobs to connect to backend data sources. There are several natively supported data sources, but what if you need to extract data from an unsupported data source? What if […]
Migrate terabytes of data quickly from Google Cloud to Amazon S3 with AWS Glue Connector for Google BigQuery
This blog post was last updated July, 2022 to update the new version of the connector and details on how to push down queries to Google BigQuery. The cloud is often seen as advantageous for data lakes because of better security, faster time to deployment, better availability, more frequent feature and functionality updates, more elasticity, […]

Doing data preparation using on-premises PostgreSQL databases with AWS Glue DataBrew
Today, with AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, and Amazon Aurora and Amazon Relational Database Service (Amazon RDS) databases. Customers can choose from over 250 […]