AWS Big Data Blog

How FanDuel Group secures personally identifiable information in a data lake using AWS Lake Formation
This post is co-written with Damian Grech from FanDuel FanDuel Group is an innovative sports-tech entertainment company that is changing the way consumers engage with their favorite sports, teams, and leagues. The premier gaming destination in the US, FanDuel Group consists of a portfolio of leading brands across gaming, sports betting, daily fantasy sports, advance-deposit […]

Setting up automated data quality workflows and alerts using AWS Glue DataBrew and AWS Lambda
Proper data management is critical to successful, data-driven decision-making. An increasingly large number of customers are adopting data lakes to realize deeper insights from big data. As part of this, you need clean and trusted data in order to gain insights that lead to improvements in your business. As the saying goes, garbage in is […]

Sharing Amazon Redshift data securely across Amazon Redshift clusters for workload isolation
Amazon Redshift data sharing allows for a secure and easy way to share live data for read purposes across Amazon Redshift clusters. Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. It allows […]

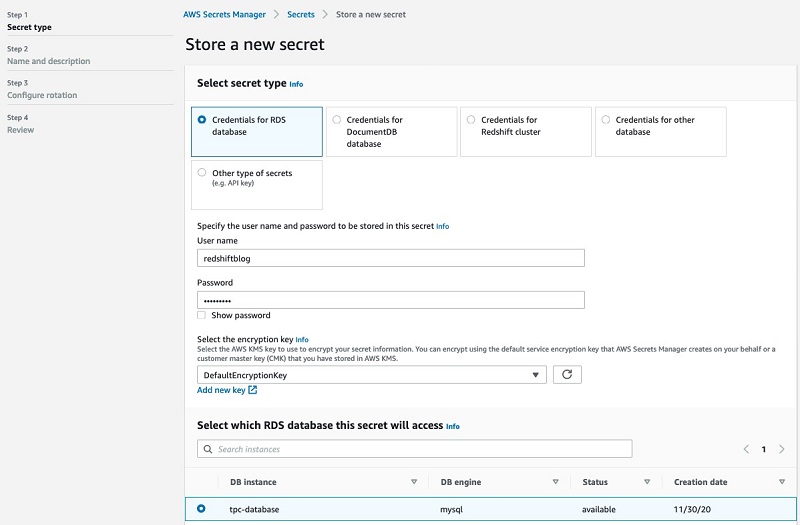
Accelerating Amazon Redshift federated query to Amazon Aurora MySQL with AWS CloudFormation
Amazon Redshift federated query allows you to combine data from one or more Amazon Relational Database Service (Amazon RDS) for MySQL and Amazon Aurora MySQL databases with data already in Amazon Redshift. You can also combine such data with data in an Amazon Simple Storage Service (Amazon S3) data lake. This post shows you how […]

New charts, formatting, and layout options in Amazon QuickSight
Amazon QuickSight is a fast, cloud-powered business intelligence (BI) service that makes it easy to create and deliver insights to everyone in your organization. In this post, we explore how authors of QuickSight dashboards can use some of the new chart types, layout options, and dashboard formatting controls to deliver dashboards that intuitively deliver insights […]

Boosting your data lake insights using the Amazon Athena Query Federation SDK
Today’s modern applications use multiple purpose-built database engines, including relational, key-value, document, and in-memory databases. This purpose-built approach improves the way applications use data by providing better performance and reducing cost. However, the approach raises some challenges for data teams that need to provide a holistic view on top of these database engines, and especially […]
Announcing Amazon Redshift federated querying to Amazon Aurora MySQL and Amazon RDS for MySQL
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in April 2020, we announced general availability for federated querying to Amazon Aurora PostgreSQL and Amazon Relational Database Service (Amazon RDS) […]
Building high-quality benchmark tests for Amazon Redshift using SQLWorkbench and psql
In the introductory post of this series, we discussed benchmarking benefits and best practices common across different open-source benchmarking tools. In this post, we discuss benchmarking Amazon Redshift with the SQLWorkbench and psql open-source tools. Let’s first start with a quick review of the introductory installment. When you use Amazon Redshift to scale compute and […]
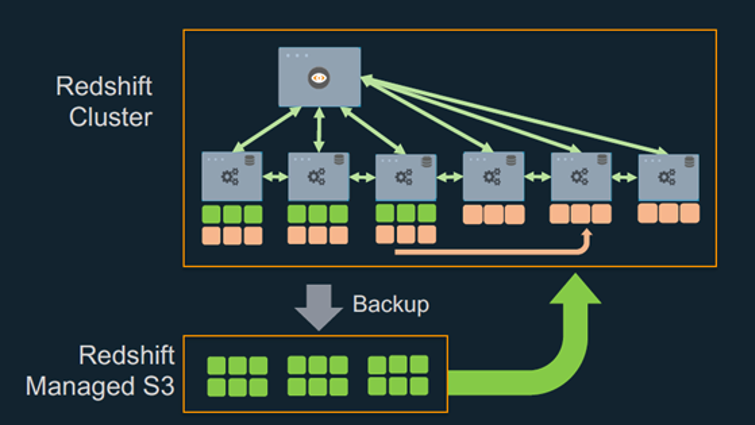
Getting the most out of your analytics stack with Amazon Redshift
Analytics environments today have seen an exponential growth in the volume of data being stored. In addition, analytics use cases have expanded, and data users want access to all their data as soon as possible. The challenge for IT organizations is how to scale your infrastructure, manage performance, and optimize for cost while meeting these […]

Working with timestamp with time zone in your Amazon S3-based data lake
With a data lake built on Amazon Simple Storage Service (Amazon S3), you can use the purpose-built analytics services for a range of use cases, from analyzing petabyte-scale datasets to querying the metadata of a single object. AWS analytics services support open file formats such as Parquet, ORC, JSON, Avro, CSV, and more, so it’s […]