AWS Big Data Blog

Automating EMR workloads using AWS Step Functions
Amazon EMR allows you to process vast amounts of data quickly and cost-effectively at scale. Using open-source tools such as Apache Spark, Apache Hive, and Presto, and coupled with the scalable storage of Amazon Simple Storage Service (Amazon S3), Amazon EMR gives analytical teams the engines and elasticity to run petabyte-scale analysis for a fraction […]

Event-driven refresh of SPICE datasets in Amazon QuickSight
Businesses are increasingly harnessing data to improve their business outcomes. To enable this transformation to a data-driven business, customers are bringing together data from structured and unstructured sources into a data lake. Then they use business intelligence (BI) tools, such as Amazon QuickSight, to unlock insights from this data. To provide fast access to datasets, […]

Using administrative dashboards for a centralized view of Amazon QuickSight objects
“Security is job 0” is the primary maxim of all endeavors undertaken at AWS. Amazon QuickSight, the fast-growing, cloud-native business intelligence (BI) platform from AWS, allows security controls in a variety of means, including web browsers and API calls. These controls apply to various functions, such as user management, authorization, authentication, and data governance. This […]

Automating Index State Management for Amazon ES
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. When it comes to time-series data, it’s more common to access new data over existing data, such as the last 4 hours or 1 day. Often, application teams are tasked with maintaining multiple indexes for diverse data workloads, which brings […]

Migrating IBM Netezza to Amazon Redshift using the AWS Schema Conversion Tool
The post How to migrate a large data warehouse from IBM Netezza to Amazon Redshift with no downtime described a high-level strategy to move from an on-premises Netezza data warehouse to Amazon Redshift. In this post, we explain how a large European Enterprise customer implemented a Netezza migration strategy spanning multiple environments, using the AWS […]
Federating Amazon Redshift access from OneLogin
December 2022: This post was reviewed and updated for accuracy. You can use federation to access AWS accounts using credentials from a corporate directory, utilizing open standards such as SAML, to exchange identity and security information between an identity provider (IdP) and an application. With this integration, you manage user identities to AWS resources centrally […]
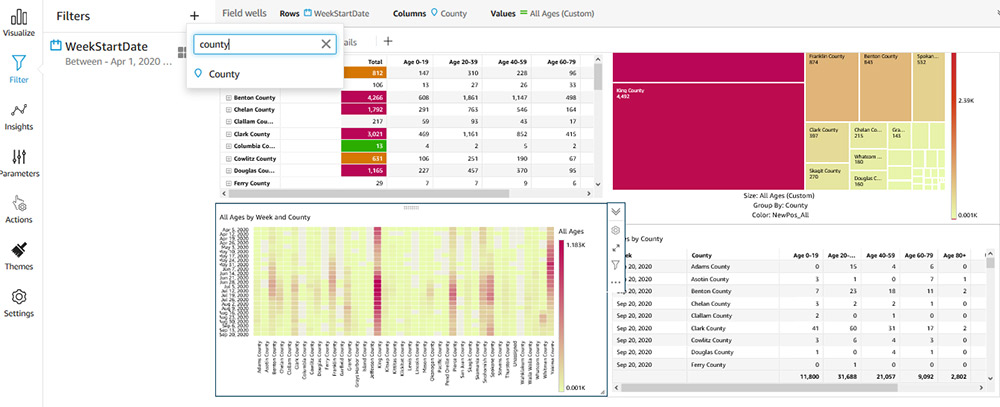
Amazon QuickSight adds support for on-sheet filter controls
Amazon QuickSight now supports easy and intuitive filter controls that you can place beside visuals on dashboards, allowing readers to quickly slice and dice data in the context of its visual representation. You can create these filter controls from existing or new filters with a single click, and configure them to support different operations, such […]

Building high-quality benchmark tests for Redshift using open-source tools: Best practices
Amazon Redshift is the most popular and fastest cloud data warehouse, offering seamless integration with your data lake, up to three times faster performance than any other cloud data warehouse, and up to 75% lower cost than any other cloud data warehouse. When you use Amazon Redshift to scale compute and storage independently, a need […]

Automating deployment of Amazon Redshift ETL jobs with AWS CodeBuild, AWS Batch, and DBT
This post was last reviewed and updated June, 2022 to update the code and service used on the AWS CloudFormation template. Data has become an essential part of every business, and its volume, velocity, and variety continue to increase. This has resulted in more complex ETL jobs with interdependencies between each other. There is also […]
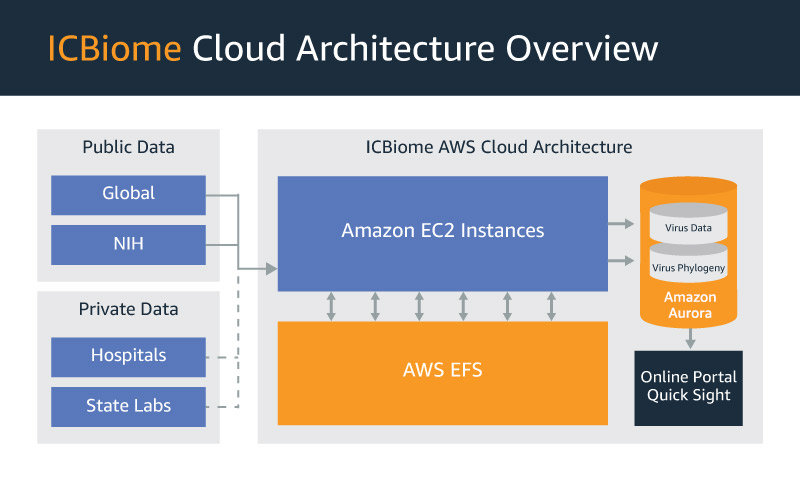
ICBiome uses Amazon QuickSight to empower hospitals in dealing with harmful pathogens
In response to the COVID-19 pandemic, hospitals and healthcare organizations are increasingly employing genetic sequencing to screen, track, and contain harmful pathogens. ICBiome is a startup that has been working on this problem for several years, creating innovative data analytics products using AWS to help hospitals and researchers address both community-associated and hospital-acquired infections. Building […]