AWS Big Data Blog

Process data with varying data ingestion frequencies using AWS Glue job bookmarks
We often have data processing requirements in which we need to merge multiple datasets with varying data ingestion frequencies. Some of these datasets are ingested one time in full, received infrequently, and always used in their entirety, whereas other datasets are incremental, received at certain intervals, and joined with the full datasets to generate output. To address this requirement, this post demonstrates how to build an extract, transform, and load (ETL) pipeline using AWS Glue.

Extend your Amazon Redshift Data Warehouse to your Data Lake
Amazon Redshift is a fast, fully managed, cloud-native data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence tools. Many companies today are using Amazon Redshift to analyze data and perform various transformations on the data. However, as data continues to grow and become […]

Access web interfaces securely on Amazon EMR launched in a private subnet using an Application Load Balancer
Amazon EMR web interfaces are hosted on the master node of an EMR cluster. When you launch an EMR cluster in a private subnet, the EMR master node doesn’t have a public DNS record. The web interfaces hosted in a private subnet aren’t easily accessible outside the subnet. You can use an Application Load Balancer (ALB), launched in a public subnet, as an HTTPS proxy to access EMR web interfaces over the internet without requiring SSH tunneling through a bastion host. This approach greatly simplifies accessing EMR web interfaces. This post outlines how to use an ALB to securely access EMR web interfaces over the internet for an EMR cluster launched in a private subnet.
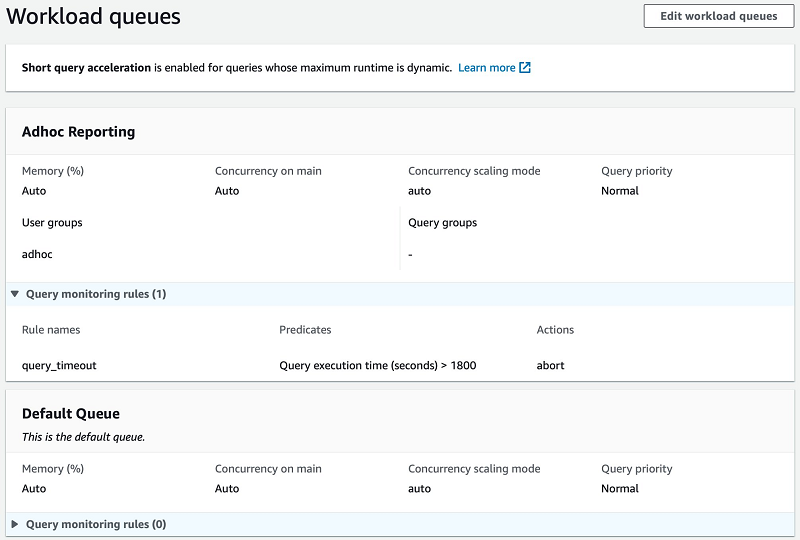
Best practices for Amazon Redshift Federated Query
This post discusses 10 best practices to help you maximize the benefits of Federated Query when you have large federated data sets, when your federated queries retrieve large volumes of data, or when you have many Redshift users accessing federated data sets. These techniques are not necessary for general usage of Federated Query. They are intended for advanced users who want to make the most of this exciting feature.

Analyzing Google Analytics data with Amazon AppFlow and Amazon Athena
This post demonstrates how you can transfer Google Analytics data to Amazon S3 using Amazon AppFlow, and analyze it with Amazon Athena. You no longer need to build your own application to extract data from Google Analytics and other SaaS applications. Amazon AppFlow enables you to develop a fully automated data transfer and transformation workflow and an integrated query environment in one place.
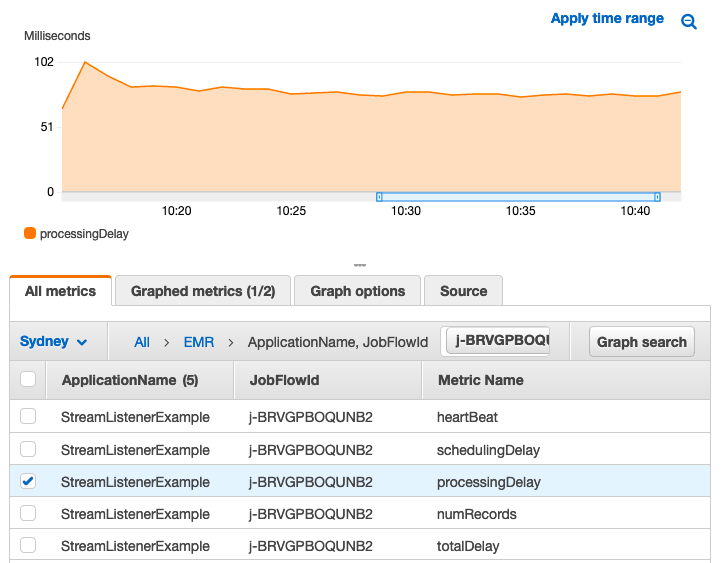
Monitor Spark streaming applications on Amazon EMR
This post demonstrates how to implement a simple SparkListener, monitor and observe Spark streaming applications, and set up some alerts. The post also shows how to use alerts to set up automatic scaling on Amazon EMR clusters, based on your CloudWatch custom metrics.

Setting up trust between ADFS and AWS and using Active Directory credentials to connect to Amazon Athena with ODBC driver
This post walks you through configuring ADFS 3.0 on a Windows Server 2012 R2 Amazon Elastic Compute Cloud (Amazon EC2) instance and setting up trust between ADFS 3.0 IdP and AWS through SAML 2.0. The post then demonstrates how to install the Athena OBDC driver on Amazon Linux EC2 instance (RHEL instance) and configure it to use ADFS for authentication.
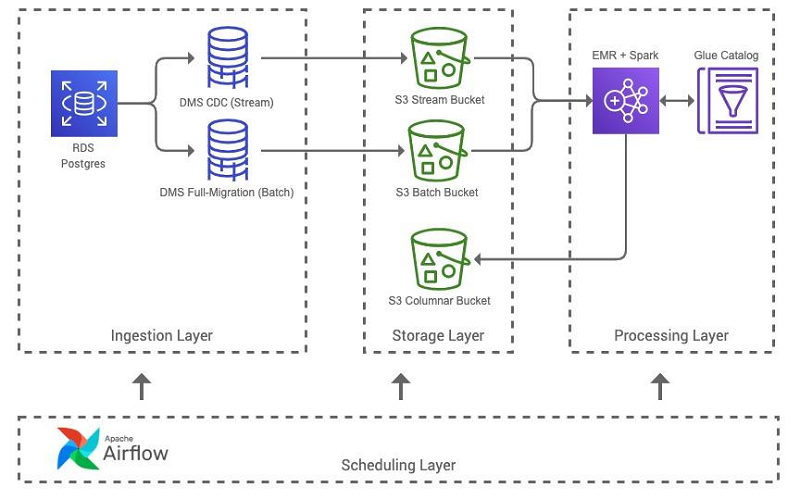
How Drop used the Amazon EMR runtime for Apache Spark to halve costs and get results 5.4 times faster
This post details how we designed and implemented our data lake’s batch ETL pipeline to use Amazon EMR, and the numerous ways we iterated on its architecture to reduce Apache Spark runtimes from hours to minutes and save over 50% on operational costs.

Using Random Cut Forests for real-time anomaly detection in Amazon OpenSearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Anomaly detection is a rich field of machine learning. Many mathematical and statistical techniques have been used to discover outliers in data, and as a result, many algorithms have been developed for performing anomaly detection in a computational setting. In […]

Running a high-performance SAS Grid Manager cluster on AWS with Amazon FSx for Lustre
SAS® is a software provider of data science and analytics used by enterprises and government organizations. SAS Grid is a highly available, fast processing analytics platform that offers centralized management that balances workloads across different compute nodes. This application suite is capable of data management, visual analytics, governance and security, forecasting and text mining, statistical […]