AWS Big Data Blog

Analyze Security, Compliance, and Operational Activity Using AWS CloudTrail and Amazon Athena
As organizations move their workloads to the cloud, audit logs provide a wealth of information on the operations, governance, and security of assets and resources. As the complexity of the workloads increases, so does the volume of audit logs being generated. It becomes increasingly difficult for organizations to analyze and understand what is happening in […]
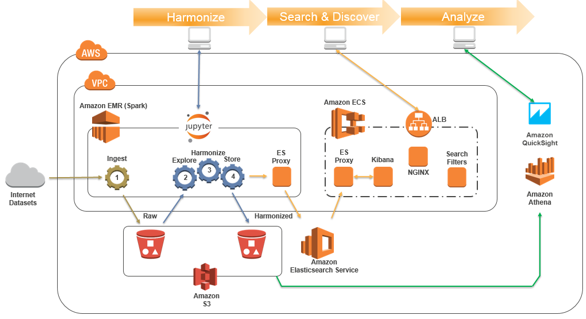
Harmonize, Search, and Analyze Loosely Coupled Datasets on AWS
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. You have come up with an exciting hypothesis, and now you are keen to find and analyze as much data as possible to prove (or refute) it. There are many datasets that might be applicable, but they have been created […]

Scheduled Refresh for SPICE Data Sets on Amazon QuickSight
Jose Kunnackal is a Senior Product Manager for Amazon Quicksight This blog post has been translated into Japanese. In November 2016, we launched Amazon QuickSight, a cloud-powered, business analytics service that lets you quickly and easily visualize your data. QuickSight uses SPICE (Super-fast, Parallel, In-Memory Calculation Engine), a fully managed data store that enables blazing […]
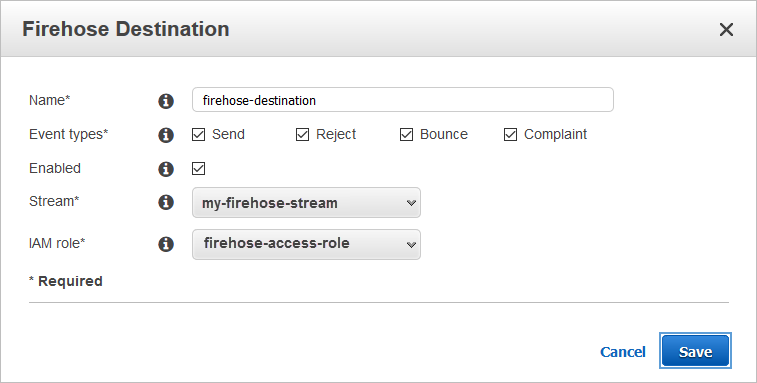
Create Tables in Amazon Athena from Nested JSON and Mappings Using JSONSerDe
July 2024: This post was reviewed and updated for accuracy. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Most systems use Java Script Object Notation (JSON) to log event information. Although it’s efficient and flexible, deriving information from JSON is […]

AWS Big Data is Coming to HIMSS!
The AWS Big Data team is coming to HIMSS, the industry-leading conference for professionals in the field of healthcare technology. The conference brings together more than 40,000 health IT professionals, clinicians, administrators, and vendors to talk about the latest innovations in health technology. Because transitioning healthcare to the cloud is at the forefront of this […]

Migrate External Table Definitions from a Hive Metastore to Amazon Athena
For customers who use Hive external tables on Amazon EMR, or any flavor of Hadoop, a key challenge is how to effectively migrate an existing Hive metastore to Amazon Athena, an interactive query service that directly analyzes data stored in Amazon S3. With Athena, there are no clusters to manage and tune, and no infrastructure to […]

Implement Serverless Log Analytics Using Amazon Kinesis Analytics
Applications log a large amount of data that—when analyzed in real time—provides significant insight into your applications. Real-time log analysis can be used to ensure security compliance, troubleshoot operation events, identify application usage patterns, and much more. Ingesting and analyzing this data in real time can be accomplished by using a variety of open source […]

Month in Review: January 2017
Another month of big data solutions on the Big Data Blog! Take a look at our summaries below and learn, comment, and share. Thank you for reading! NEW POSTS Decreasing Game Churn: How Upopa used ironSource Atom and Amazon ML to Engage Users Ever wondered what it takes to keep a user from leaving your […]

Secure Amazon EMR with Encryption
In the last few years, there has been a rapid rise in enterprises adopting the Apache Hadoop ecosystem for critical workloads that process sensitive or highly confidential data. Due to the highly critical nature of the workloads, the enterprises implement certain organization/industry wide policies and certain regulatory or compliance policies. Such policy requirements are designed […]
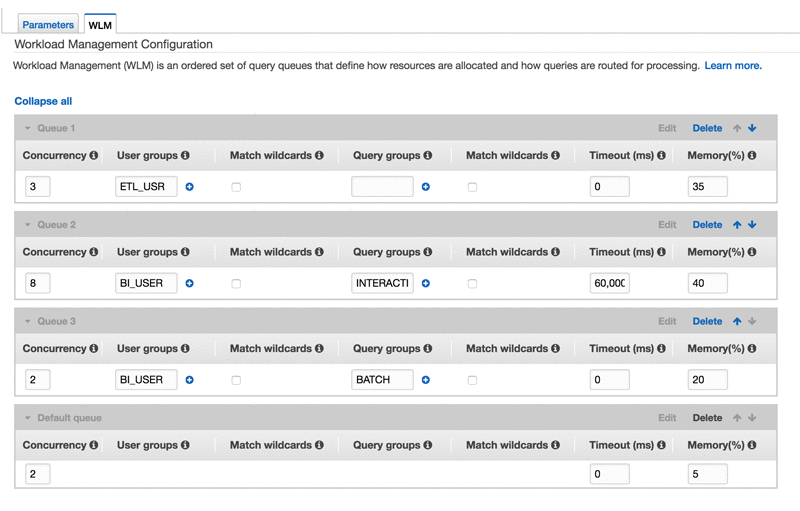
Run Mixed Workloads with Amazon Redshift Workload Management
This blog post has been translated into Japanese. Mixed workloads run batch and interactive workloads (short-running and long-running queries or reports) concurrently to support business needs or demand. Typically, managing and configuring mixed workloads requires a thorough understanding of access patterns, how the system resources are being used and performance requirements. It’s common for mixed […]