AWS Big Data Blog
Preprocessing Data in Amazon Kinesis Analytics with AWS Lambda
Many customers use Amazon Kinesis to ingest, analyze, and persist their streaming data. One of the easiest ways to gain real-time insights into your streaming data is to use Kinesis Analytics. It enables you to query the data in your stream or build entire streaming applications using SQL. Customers use Kinesis Analytics for things like filtering, aggregation, and anomaly detection.
Kinesis Analytics now gives you the option to preprocess your data with AWS Lambda. This gives you a great deal of flexibility in defining what data gets analyzed by your Kinesis Analytics application. You can also define how that data is structured before it is queried by your SQL.
In this post, I discuss some common use cases for preprocessing, and walk you through an example to help highlight its applicability.
Common use cases
There are many reasons why you might choose to preprocess data before starting your analysis. Because you build your preprocessing logic with Lambda, your preprocessor can do anything supported by Lambda. However, there are some specific use cases that lend themselves well to preprocessing, such as data enrichment and data transformation.
Enrichment
In some scenarios, you may need to enhance your streaming data with additional information, before you perform your SQL analysis. Kinesis Analytics gives you the ability to use data from Amazon S3 in your Kinesis Analytics application, using the Reference Data feature. However, you cannot use other data sources from within your SQL query.
To add dynamic data to your streaming data, you can preprocess with a Lambda function, and retrieve the data from the data store of your choosing. For example, consider a scenario where you’re streaming some data about users of your application, including their IP address. You want to do some real-time analysis on the geographic locations of your customers. In this example, your preprocessing Lambda function uses your data source for geolocation information to retrieve the user’s city, state or province, and country, based on the IP address that was included in the streaming record. You then enrich the record with that information and now your SQL query can use those attributes in its aggregation.
Transformation
Because Kinesis Analytics uses SQL to analyze your data, the structure of your streaming records must be mapped to a schema. If your records are JSON or CSV, Kinesis Analytics automatically creates a schema. However, if your JSON records contain complex nested arrays, you may need to customize how the record structure is mapped to a flattened schema. Further, Kinesis Analytics is unable to automatically parse formats such as GZIP, protobuf, or Avro.
If your input records are unstructured text, Kinesis Analytics creates a schema, but it consists of a single column representing your entire record. To remedy these complexities, use Lambda to transform and convert your streaming data so that it more easily maps to a schema that can be queried by the SQL in your Kinesis Analytics application.
Assume that you’re streaming raw Apache access log data from a web fleet to a Kinesis stream, and you want to use Kinesis Analytics to detect anomalies in your HTTP response codes. In this example, you want to detect when your stream contains an unusually large number of 500 response codes. This may indicate that something has gone wrong somewhere in your application, and as a result, Apache is returning 500 responses to clients. This is typically not a good customer experience.
An example Apache access log record looks like this:
Although its structure is well-defined, it is not JSON or CSV, so it doesn’t map to a defined schema in Kinesis Analytics. To use Kinesis Analytics with raw Apache log records, you can transform them to JSON or CSV with a preprocessing Lambda function. For example, you can convert it to a simple JSON documents that easily maps to a schema:
Architecture
To illustrate where the preprocessing step takes place within Kinesis Analytics, take a high-level look at the architecture.
Kinesis Analytics continuously reads data from your Kinesis stream or Kinesis Firehose delivery stream. For each batch of records that it retrieves, the Lambda processor subsystem manages how each batch gets passed to your Lambda function. Your function receives a list of records as input. Within your function, you iterate through the list and apply your business logic to accomplish your preprocessing requirements (such as data transformation).
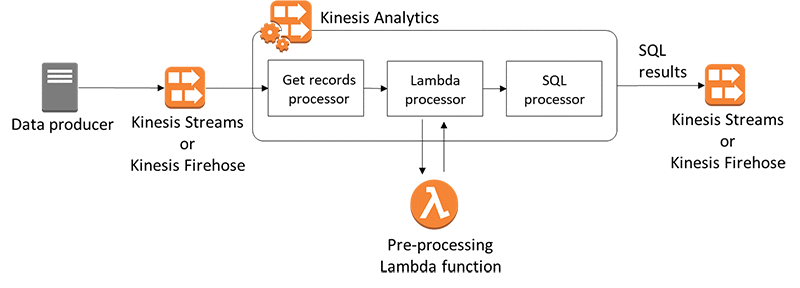
The input model to your preprocessing function varies slightly, depending on whether the data was received from a stream or delivery stream.
If the source is Kinesis Firehose, the input model is:
If the source is Kinesis Streams, the input data contains a few extra attributes specific to streams:
As you can see, the records attribute is an array of record objects. In your Lambda function, you iterate through each element of the array. Each element’s data attribute contains the base64-encoded record that was retrieved from your input stream or delivery stream. Your function is required to return the modified batch of records using the following model:
For each input record, the output must contain a corresponding record with the same recordId value. The result attribute for each record varies, depending on the logic that you applied in your function. The acceptable values for result are Ok, Dropped, and ProcessingFailed. If the result is Ok, then the value returned in the data attribute continues in the pipeline to the SQL processor. By setting the value of result to Dropped, you can filter out unwanted records.
If your preprocessing function determines that it cannot process a particular record, it can set result to ProcessingFailed, and Kinesis Analytics writes the original record to its error stream. You can access the contents of the error stream to review failed records and take appropriate action.
The Lambda processor in Kinesis Analytics also manages failures and retries of your Lambda function. In cases where your Lambda function returns a result of ProcessingFailed, Kinesis Analytics writes the original input records to its error stream. Therefore, it’s important that you configure a destination for the error stream in your Kinesis Analytics application. By configuring a destination, such as a delivery stream with an S3 destination, all failed records get delivered to a bucket in S3 for later debugging and analysis.
Example Lambda function
Now that you understand some common preprocessing scenarios, and you know where preprocessing fits in the sequence of your Kinesis Analytics application, put it all together into an example Lambda function.
Assume that a data producer is compressing JSON records before sending them to a Kinesis stream or a Kinesis Firehose delivery stream. You want to use Kinesis Analytics to analyze these compressed records. Before you can use SQL to perform the analysis, you must first decompress each input record so that it’s represented as decompressed JSON. This enables it to map to the schema you’ve created in the Kinesis Analytics application. The function below, written in Node.js, receives a list of records, decompresses each, and returns the complete list of decompressed records:
Notice how the function sets the result to ProcessingFailed for any record that fails to decompress. In this scenario, Kinesis Analytics writes that failed record to its error stream.
Conclusion
The ability to preprocess your streaming data with Lambda enables you to use Kinesis Analytics to analyze a limitless variety of data. To help you get started, we’ve created several Lambda blueprints in both Python and Node.js. The decompression example used earlier has also been included as a blueprint. The Lambda blueprints can be found in the AWS Lambda Management Console.
To learn more about pre-processing your streaming data, see the Kinesis Analytics documentation.
Additional Reading
Learn how to build a visualization and monitoring dashboard for IoT data with Amazon Kinesis Analytics and Amazon Quicksight.

About the Author
 Allan MacInnis is a Solutions Architect at Amazon Web Services. He works with our customers to help them build streaming data solutions using Amazon Kinesis. In his spare time, he enjoys mountain biking and spending time with his family.
Allan MacInnis is a Solutions Architect at Amazon Web Services. He works with our customers to help them build streaming data solutions using Amazon Kinesis. In his spare time, he enjoys mountain biking and spending time with his family.