AWS Big Data Blog
Streamline Spark application development on Amazon EMR with the Data Solutions Framework on AWS
Today, organizations are heavily using Apache Spark for their big data processing needs. However, managing the entire development lifecycle of Spark applications—from local development to production deployment—can be complex and time-consuming. Managing the entire code base—including application code, infrastructure provisioning, and continuous integration and delivery (CI/CD) pipelines—is sometimes not fully automated and a shared responsibility across multiple teams, which slows down release cycles. This undifferentiated heavy lifting diverts valuable resources away from core business objectives: deriving value from data.
In this post, we explore how to use Amazon EMR, the AWS Cloud Development Kit (AWS CDK), and the Data Solutions Framework (DSF) on AWS to streamline the development process, from setting up a local development environment to deploying serverless Spark infrastructure, and implementing a CI/CD pipeline for automated testing and deployment.
By adopting this approach, developers gain full control over their code and the infrastructure responsible for running it, alleviating the need for cross-team dependency. Developers can customize the infrastructure to meet specific business needs and optimize performance. Additionally, they can customize CI/CD stages to facilitate comprehensive testing, using the self-mutation capability of AWS CDK Pipelines to automatically update and refine the deployment process. This level of control not only accelerates development cycles but also enhances the reliability and efficiency of the entire application lifecycle, so developers can focus more on innovation and less on manual infrastructure management.
Solution overview
The solution consists of the following key components:
- The local development environment to develop and test your Spark code locally
- The infrastructure as code (IaC) that will run your Spark application in AWS environments
- The CI/CD pipeline running end-to-end tests and deploying into the different AWS environments
In the following sections, we discuss how to set up these components.
Prerequisites
To set up this solution, you must have an AWS account with appropriate permissions, Docker and the AWS CDK CLI.
Set up the local development environment
Developing Spark applications locally can be a challenging task due to the need for a consistent and efficient environment that mirrors your production setup. With Amazon EMR, Docker, and the Amazon EMR toolkit extension for Visual Studio Code, you can quickly set up a local development environment for Spark applications, developing and testing Spark code locally, and seamlessly port it to the cloud.
The Amazon EMR toolkit for VS Code includes an “EMR: Create Local Spark Environment” command that generates a development container. This container is based on an Amazon EMR on Amazon EKS image corresponding to the Amazon EMR version you select. You can develop Spark and PySpark code locally, with full compatibility with your remote Amazon EMR environment. Additionally, the toolkit provides helpers to make it straightforward to connect to the AWS Cloud, including an Amazon EMR explorer, an AWS Glue Data Catalog explorer, and commands to run Amazon EMR Serverless jobs from VS Code.
To set up your local environment, complete the following steps:
- Install VS Code and the Amazon EMR Toolkit for VS Code.
- Install and launch Docker.
- Create a local Amazon EMR environment in your working directory using the command EMR: Create Local Spark Environment.
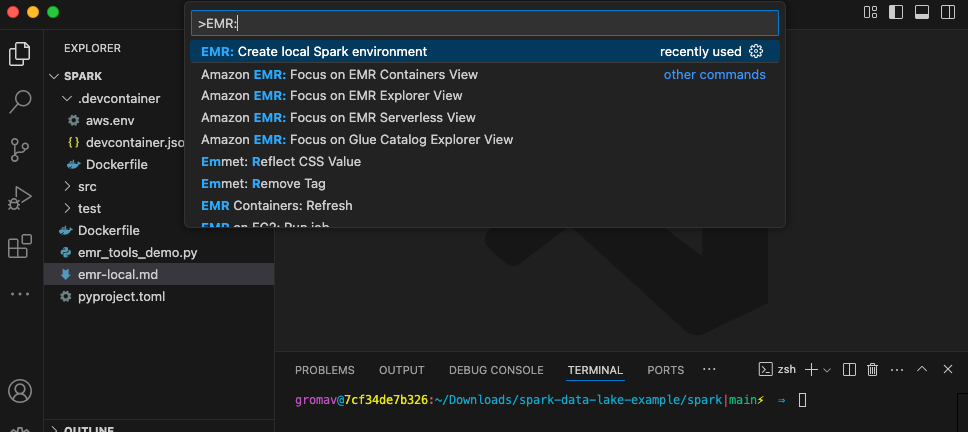
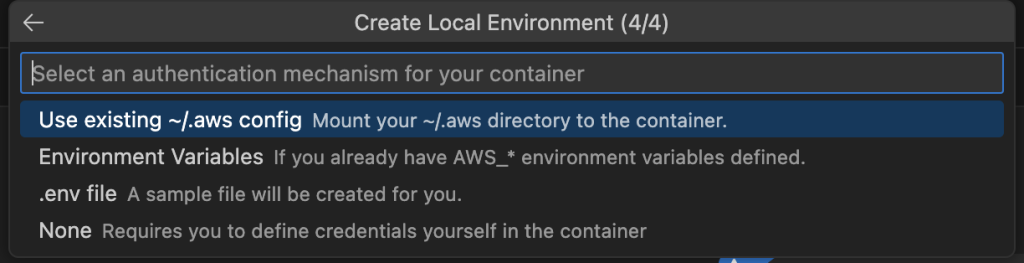
- Choose PySpark, Amazon EMR 7.5, and the AWS Region you want to use, and choose an authentication mechanism.
- Log in to Amazon ECR with your AWS credentials using the following command so you can download the Amazon EMR image:
- Now you can launch your dev container using the VS Code command Dev Containers: Rebuild and Reopen in container.
The container will install the latest operating system packages and run a local Spark history server on port 18080.
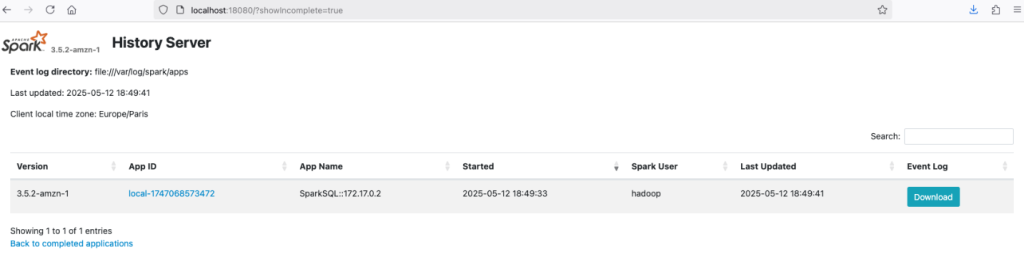
The container provides spark-shell, spark-sql, and pyspark from the terminal and a Jupyter Python kernel for connecting a Jupyter notebook to execute interactive Spark code.
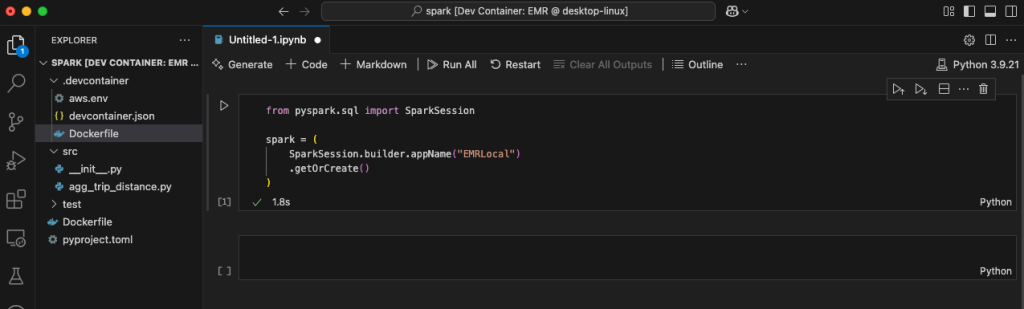
Using the Amazon EMR Toolkit, you can develop your Spark application and test it locally using Pytest—for example, to validate the business logic. You can also connect to other AWS accounts where you have your development environment.
Build the AWS CDK application with DSF on AWS
After you validate the business logic into your local Spark application, you can implement the infrastructure responsible for running your application. DSF provides AWS CDK L3 Constructs that simplify the creation of Spark-based data pipelines on EMR Serverless or Amazon EMR on EKS.
DSF provides the capability to package your local PySpark application, including the Python dependencies, into artifacts that can consumed by EMR Serverless jobs. The PySparkApplicationPackage is a construct that uses a Dockerfile to perform the packaging of dependencies into a Python virtual environment archive and then upload the archive and the PySpark entrypoint file into a secured Amazon Simple Storage Service (Amazon S3) bucket. The following diagram illustrates this architecture.
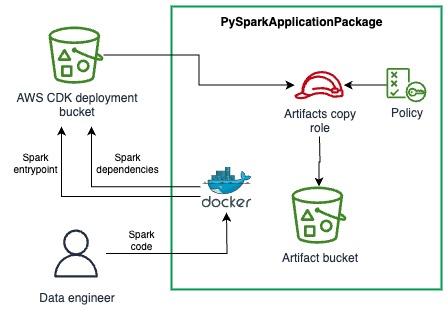
See the following example code:
You just need to provide the paths for the following:
- The PySpark entrypoint. This is the main Python script of your Spark application.
- The Dockerfile containing the logic for packaging a virtual environment into an archive.
- The path of the resulting archive in the container file system.
DSF provides helpers to connect the application package to the EMR Serverless job. The PySparkApplicationPackage construct exposes properties that can directly be used into the SparkEmrServerlessJob construct parameters. This construct simplifies the configuration of a batch job using an AWS Step Functions state machine. The following diagram illustrates this architecture.
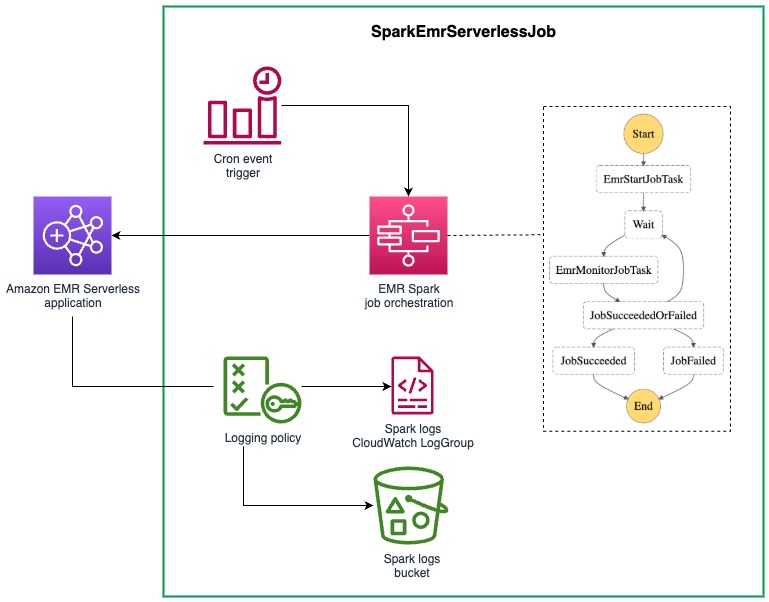
The following code is an example of an EMR Serverless job:
Note the two parameters of SparkEmrServerlessJob that are provided by PySparkApplicationPackage:
- entrypoint_uri, which is the S3 URI of the entrypoint file
- spark_venv_conf, which contains the Spark submit parameters for using the Python virtual environment
DSF also provides a SparkEmrServerlessRuntime to simplify the creation of the EMR Serverless application responsible for running the job.
Deploy the Spark application using CI/CD
The final step is to implement a CI/CD pipeline that can test your Spark code and promote from dev/test/stage and then to production. DSF provides a L3 Construct that simplifies the creation of the CI/CD pipeline for your Spark applications. DSF’s implementation of the Spark CI/CD pipeline construct uses the AWS CDK built-in pipeline functionality. One of the key capabilities when using an AWS CDK pipeline is its self-mutating capability. It can update itself whenever you change its definition, avoiding the traditional chicken-and-egg problem of pipeline updates and helping developers fully control their CI/CD pipeline.
When the pipeline runs, it follows a carefully orchestrated sequence. First, it retrieves your code from your repository and synthesizes it into AWS CloudFormation templates. Before doing anything else, it examines these templates to see if you’ve made any changes to the pipeline’s own structure. If the pipeline detects that its definition has changed, it will pause its normal operation and update itself first. After the pipeline has updated itself, it will continue with its regular stages, such as deploying your application.
DSF provides an opinionated implementation of CDK Pipelines for Spark applications, where the PySpark code is automatically unit tested using Pytest and where the configuration is simplified. You only need to configure four components:
- The CI/CD stages (testing, staging, production, and so on). This includes the AWS account ID and Region where these environments reside in.
- The AWS CDK stack that is deployed in each environment.
- (Optional) The integration test script that you want to run against the deployed stack.
- The SparkEmrCICDPipeline AWS CDK construct.
The following diagram illustrates how everything works together.
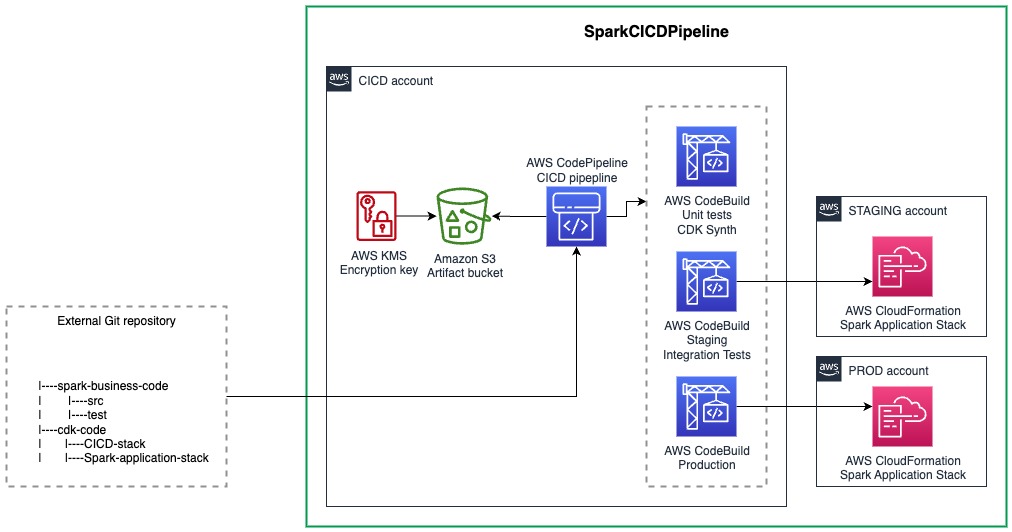
Let’s dive into each of these components.
Define cross-account deployment and CI/CD stages
With the SparkEmrCICDPipeline construct, you can deploy your Spark application stack across different AWS accounts. For example, you can have a separate account for your CI/CD processes and different accounts for your staging and production environments.To set this up, first bootstrap the various AWS accounts (staging, production, and so on):
This step sets up the necessary resources in the environment accounts and creates a trust relationship between those accounts and the CI/CD account where the pipeline will run.Next, choose between two options to define the environments (both options require the relevant configuration in the cdk.context.json file.The first option is to use pre-defined environments, which is defined as follows:
Alternatively, you can use user-defined environments, which is defined as follows:
Customize the stack to be deployed
Now that the environments have been bootstrapped and configured, let’s look at the actual stack that contains the resources that will be deployed in the various environments. Two classes must be implemented:
- A class that extends the stack – This is where the resources that are going to be deployed in each of the environments are defined. This can be a normal AWS CDK stack, but it can be deployed in another AWS account depending on the environment configuration defined in the previous section.
- A class that extends ApplicationStackFactory – This is DSF specific, and makes it possible to configure and then return the stack that is created.
The following code shows a full example:
ApplicationStackFactory supports customization of the stack before returning the initialized object to be deployed by the CI/CD pipeline. You can customize your stack behavior by passing the current stage to your stack. For example, you can skip scheduling the Spark application in the integration tests stage because the integration tests trigger it manually as part of the CI/CD pipeline. For the production stage, the scheduling facilitates automatic execution of the Spark application.
Write the integration test script
The integration test script is a bash script that is triggered after the main application stack has been deployed. Inputs to the bash script can come from the AWS CloudFormation outputs of the main application stack. These outputs are mapped into environment variables that the bash script can access directly.
In the Spark CI/CD example, the application stack uses the SparkEMRServerlessJob CDK construct. This construct uses a Step Functions state machine to manage the execution and monitoring of the Spark job. The following is an example integration test bash script that we use to test that the deployed stack can run the associated Spark job successfully:
The integration test scripts are executed within an AWS CodeBuild project. As part of the IntegrationTestStack, we’ve included a custom resource that periodically checks the status of the integration test script as it runs. Failure of the CodeBuild execution causes the parent pipeline (residing in the pipeline account) to fail. This helps teams only promote changes that pass all the required testing.
Bring all the components together
When you have your components ready, you can use the SparkEmrCICDPipeline to bring them together. See the following example code:
The following elements of the code are worth highlighting:
- With the integ_test_env parameter, you can define the environment variable mapping with the output of your application stack that’s defined in the application_stack_factory parameter
- The integ_test_permissions parameter specifies the AWS Identity and Access Management (IAM) permissions that are attached to the CodeBuild project where the integration test script runs in
- CDK Pipelines needs an AWS code connection Amazon Resource Name (ARN) to connect to your Git repository when you host your code
Now you can deploy the stack containing the CI/CD pipeline. This is a one-time operation because the CI/CD pipeline will dynamically be updated based on code changes that impact the CI/CD pipeline itself:
Then you can commit and push the code into the source code repository defined in the source parameter. This step triggers the pipeline and deploys the application in the configured environments. You can check the pipeline definition and status on the AWS CodePipeline console.
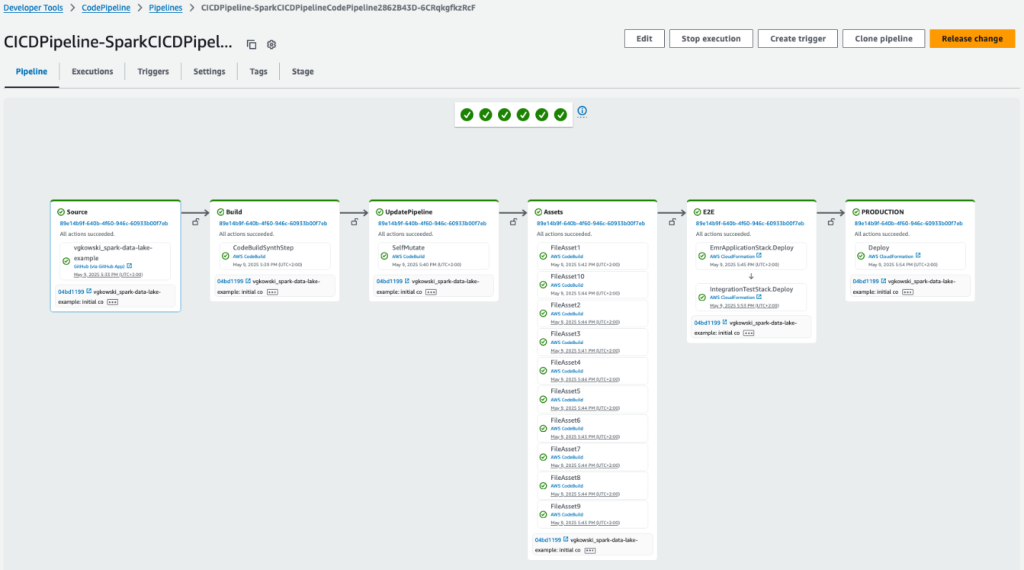
You can find the full example on the Data Solutions Framework GitHub repository.
Clean up
Follow the readme guide to delete the resources created by the solution.
Conclusion
By using Amazon EMR, the AWS CDK, DSF on AWS, and the Amazon EMR toolkit, developers can now streamline their Spark application development process. The solution described in this post helps developers gain full control over their code and infrastructure, making it possible to set up local development environments, implement automated CI/CD pipelines, and deploy serverless Spark infrastructure across multiple environments.
DSF supports other patterns, such as streaming governance and data sharing and Amazon Redshift data warehousing. The DSF roadmap is publicly available, and we look forward to your feature requests, contributions, and feedback. You can get started using DSF by following our Quick start guide.