AWS Big Data Blog
Tag: Amazon EMR
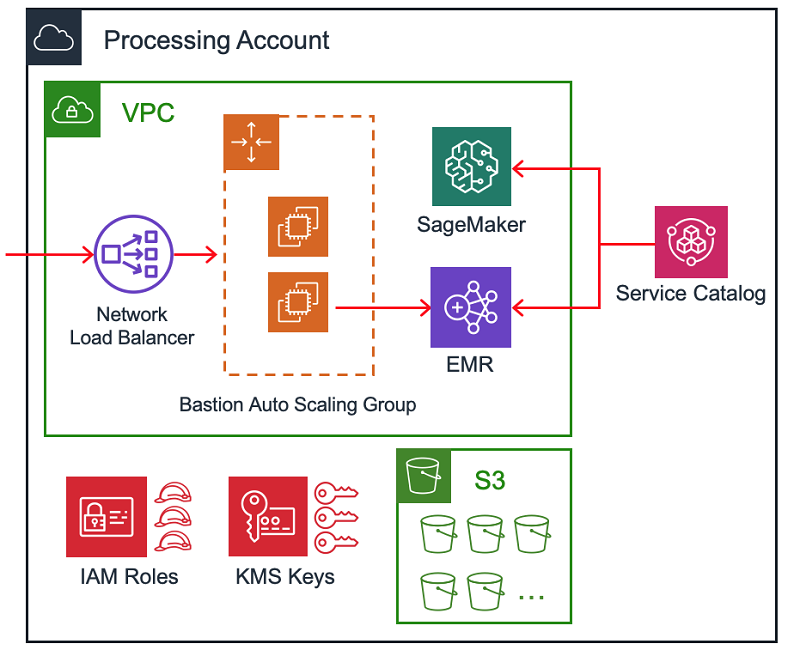
Provisioning the Intuit Data Lake with Amazon EMR, Amazon SageMaker, and AWS Service Catalog
This post outlines the approach taken by Intuit, though it is important to remember that there are many ways to build a data lake (for example, AWS Lake Formation). We’ll cover the technologies and processes involved in creating the Intuit Data Lake at a high level, including the overall structure and the automation used in provisioning accounts and resources. Watch this space in the future for more detailed blog posts on specific aspects of the system, from the other teams and engineers who worked together to build the Intuit Data Lake.

Amazon EMR introduces EMR runtime for Apache Spark
Amazon EMR is happy to announce Amazon EMR runtime for Apache Spark, a performance-optimized runtime environment for Apache Spark that is active by default on Amazon EMR clusters. EMR runtime for Spark is up to 32 times faster than EMR 5.16, with 100% API compatibility with open-source Spark. This means that your workloads run faster, […]
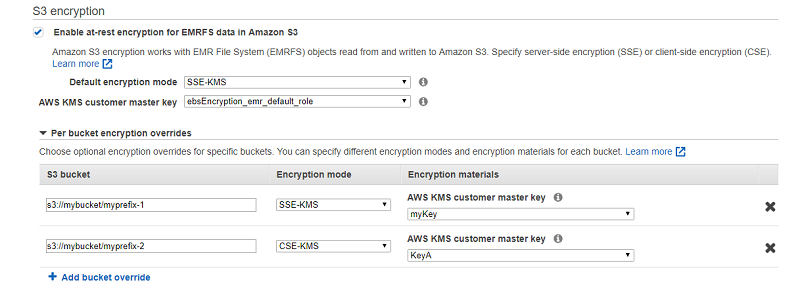
Secure your data on Amazon EMR using native EBS and per bucket S3 encryption options
This post provides a detailed walkthrough of two new encryption options to help you secure your EMR cluster that handles sensitive data. The first option is native EBS encryption to encrypt volumes attached to EMR clusters. The second option is an Amazon S3 encryption that allows you to use different encryption modes and customer master keys (CMKs) for individual S3 buckets with Amazon EMR.

Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 2
In Part 1 of this post series, you learned how to use Apache Airflow, Genie, and Amazon EMR to manage big data workflows. This post guides you through deploying the AWS CloudFormation templates, configuring Genie, and running an example workflow authored in Apache Airflow.
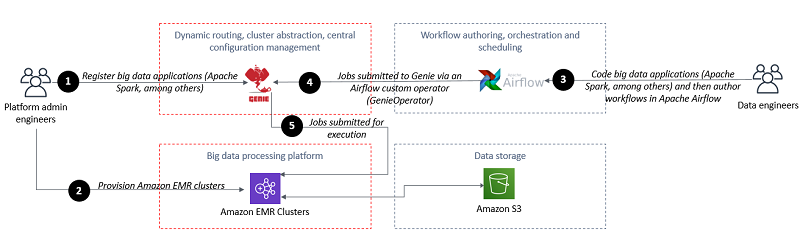
Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 1
This post introduces an architecture that helps centralized platform teams maintain a big data platform to service thousands of concurrent ETL workflows, and simplifies the operational tasks required to accomplish that.
Install Python libraries on a running cluster with EMR Notebooks
This post discusses installing notebook-scoped libraries on a running cluster directly via an EMR Notebook. Before this feature, you had to rely on bootstrap actions or use custom AMI to install additional libraries that are not pre-packaged with the EMR AMI when you provision the cluster. This post also discusses how to use the pre-installed Python libraries available locally within EMR Notebooks to analyze and plot your results. This capability is useful in scenarios in which you don’t have access to a PyPI repository but need to analyze and visualize a dataset.

Secure your Amazon EMR cluster from unintentional network exposure with Block Public Access configuration
This post discusses a new account level feature called Block Public Access (BPA) configuration that helps administrators enforce a common public access rule across all of their EMR clusters in a region.

Implement perimeter security in Amazon EMR using Apache Knox
Perimeter security helps secure Apache Hadoop cluster resources to users accessing from outside the cluster. It enables a single access point for all REST and HTTP interactions with Apache Hadoop clusters and simplifies client interaction with the cluster. For example, client applications must acquire Kerberos tickets using Kinit or SPNEGO before interacting with services on Kerberos enabled clusters. In this post, we walk through setup of Apache Knox to enable perimeter security for EMR clusters.

Run Spark applications with Docker using Amazon EMR 6.0.0 (Beta)
This post shows you how to use Docker with the EMR release 6.0.0 Beta. You’ll learn how to launch an EMR release 6.0.0 Beta cluster and run Spark jobs using Docker containers from both Docker Hub and Amazon ECR.
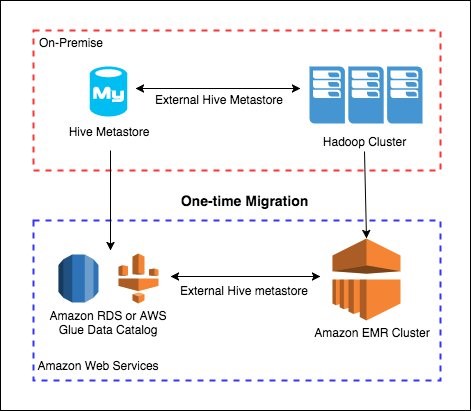
Migrate and deploy your Apache Hive metastore on Amazon EMR
Combining the speed and flexibility of Amazon EMR with the utility and ubiquity of Apache Hive provides you with the best of both worlds. However, getting started with big data projects can feel intimidating. Whether you want to deploy new data on EMR or migrate an existing project, this post provides you with the basics to get started.