AWS Big Data Blog
Tag: Amazon EMR

Introducing Amazon EMR Managed Scaling – Automatically Resize Clusters to Lower Cost
AWS is happy to announce the release of Amazon EMR Managed Scaling—a new feature that automatically resizes your cluster for best performance at the lowest possible cost. With EMR Managed Scaling you specify the minimum and maximum compute limits for your clusters and Amazon EMR automatically resizes them for best performance and resource utilization. EMR Managed Scaling continuously samples key metrics associated with the workloads running on clusters. EMR Managed Scaling is supported for Apache Spark, Apache Hive and YARN-based workloads on Amazon EMR versions 5.30.1 and above.

Access web interfaces securely on Amazon EMR launched in a private subnet using an Application Load Balancer
Amazon EMR web interfaces are hosted on the master node of an EMR cluster. When you launch an EMR cluster in a private subnet, the EMR master node doesn’t have a public DNS record. The web interfaces hosted in a private subnet aren’t easily accessible outside the subnet. You can use an Application Load Balancer (ALB), launched in a public subnet, as an HTTPS proxy to access EMR web interfaces over the internet without requiring SSH tunneling through a bastion host. This approach greatly simplifies accessing EMR web interfaces. This post outlines how to use an ALB to securely access EMR web interfaces over the internet for an EMR cluster launched in a private subnet.
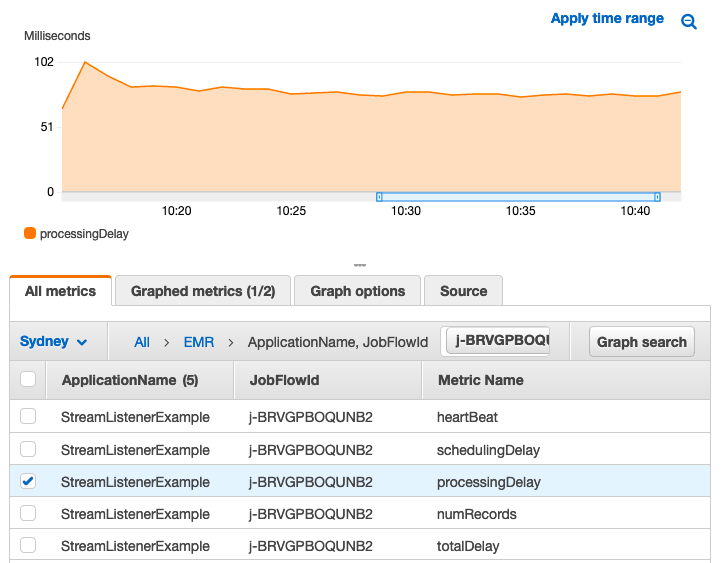
Monitor Spark streaming applications on Amazon EMR
This post demonstrates how to implement a simple SparkListener, monitor and observe Spark streaming applications, and set up some alerts. The post also shows how to use alerts to set up automatic scaling on Amazon EMR clusters, based on your CloudWatch custom metrics.
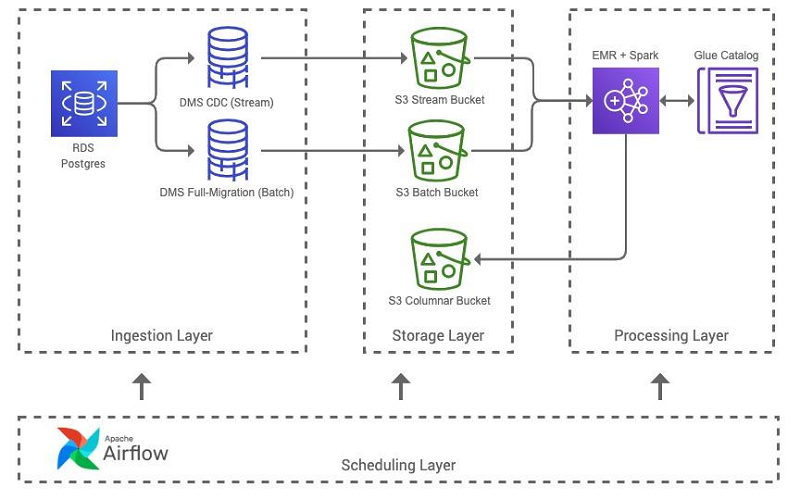
How Drop used the Amazon EMR runtime for Apache Spark to halve costs and get results 5.4 times faster
This post details how we designed and implemented our data lake’s batch ETL pipeline to use Amazon EMR, and the numerous ways we iterated on its architecture to reduce Apache Spark runtimes from hours to minutes and save over 50% on operational costs.
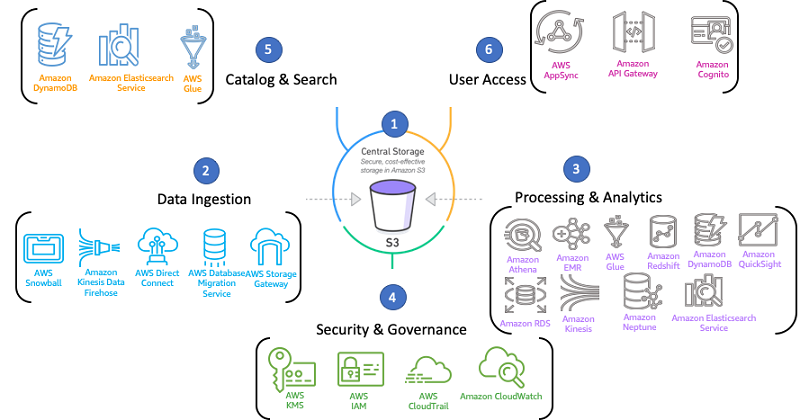
Build an AWS Well-Architected environment with the Analytics Lens
Building a modern data platform on AWS enables you to collect data of all types, store it in a central, secure repository, and analyze it with purpose-built tools. Yet you may be unsure of how to get started and the impact of certain design decisions. To address the need to provide advice tailored to specific technology and application domains, AWS added the concept of well-architected lenses 2017. AWS now is happy to announce the Analytics Lens for the AWS Well-Architected Framework. This post provides an introduction of its purpose, topics covered, common scenarios, and services included.

Build an automatic data profiling and reporting solution with Amazon EMR, AWS Glue, and Amazon QuickSight
This post demonstrates how to extend the metadata contained in the Data Catalog with profiling information calculated with an Apache Spark application based on the Amazon Deequ library running on an EMR cluster. You can query the Data Catalog using the AWS CLI. You can also build a reporting system with Athena and Amazon QuickSight to query and visualize the data stored in Amazon S3.

Simplify your Spark dependency management with Docker in EMR 6.0.0
Apache Spark is a powerful data processing engine that gives data analyst and engineering teams easy to use APIs and tools to analyze their data, but it can be challenging for teams to manage their Python and R library dependencies. Installing every dependency that a job may need before it runs and dealing with library […]

Apache Hive is 2x faster with Hive LLAP on EMR 6.0.0
Customers use Apache Hive with Amazon EMR to provide SQL-based access to petabytes of data stored on Amazon S3. Amazon EMR 6.0.0 adds support for Hive LLAP, providing an average performance speedup of 2x over EMR 5.29, with up to 10x improvement on individual Hive TPC-DS queries. This post shows you how to enable Hive […]

Tune Hadoop and Spark performance with Dr. Elephant and Sparklens on Amazon EMR
This post demonstrates how to install Dr. Elephant and Sparklens on an Amazon EMR cluster and run workloads to demonstrate these tools’ capabilities. Amazon EMR is a managed Hadoop service offered by AWS to easily and cost-effectively run Hadoop and other open-source frameworks on AWS.
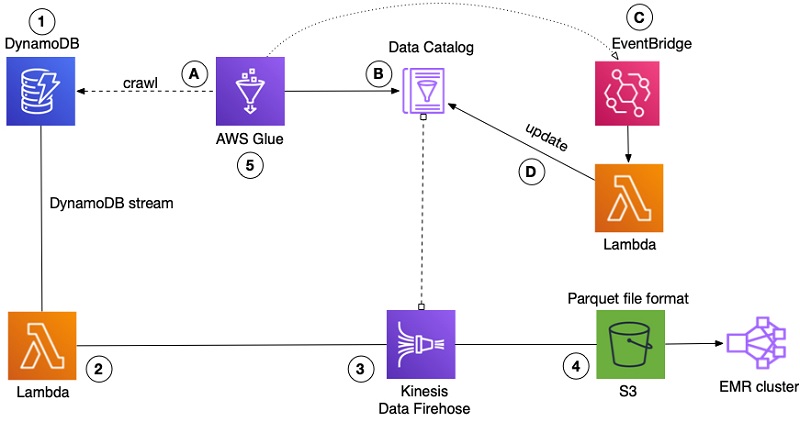
How FactSet automated exporting data from Amazon DynamoDB to Amazon S3 Parquet to build a data analytics platform
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest post by Arvind Godbole, Lead Software Engineer with FactSet and Tarik Makota, AWS Principal Solutions Architect. In their own words “FactSet creates flexible, open data and software solutions […]