AWS Big Data Blog
Tag: Amazon EMR

Design considerations for Amazon EMR on EKS in a multi-tenant Amazon EKS environment
Many AWS customers use Amazon Elastic Kubernetes Service (Amazon EKS) in order to take advantage of Kubernetes without the burden of managing the Kubernetes control plane. With Kubernetes, you can centrally manage your workloads and offer administrators a multi-tenant environment where they can create, update, scale, and secure workloads using a single API. Kubernetes also […]

Configure Hadoop YARN CapacityScheduler on Amazon EMR on Amazon EC2 for multi-tenant heterogeneous workloads
Apache Hadoop YARN (Yet Another Resource Negotiator) is a cluster resource manager responsible for assigning computational resources (CPU, memory, I/O), and scheduling and monitoring jobs submitted to a Hadoop cluster. This generic framework allows for effective management of cluster resources for distributed data processing frameworks, such as Apache Spark, Apache MapReduce, and Apache Hive. When […]

Disaster recovery considerations with Amazon EMR on Amazon EC2 for Spark workloads
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR launches all nodes for a given cluster in the same Amazon Elastic Compute Cloud (Amazon EC2) Availability Zone […]

Build a self-service environment for each line of business using Amazon EMR and AWS Service Catalog
Enterprises often want to centralize governance and compliance requirements, and provide a common set of policies on how Amazon EMR instances should be set up. You can use AWS Service Catalog to centrally manage commonly deployed Amazon EMR cluster configurations, and this helps you achieve consistent governance and meet your compliance requirements, while at the […]

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]

Monitor and Optimize Analytic Workloads on Amazon EMR with Prometheus and Grafana
This post discusses installing and configuring Prometheus and Grafana on an Amazon Elastic Compute Cloud (Amazon EC2) instance, configuring an EMR cluster to emit metrics that Prometheus can scrape from the cluster, and using the Grafana dashboards to analyze the metrics for a workload on the EMR cluster and optimize it. Additionally, we also cover how Prometheus can push alerts to the Alertmanager, and configuring Amazon SNS to send email notifications.
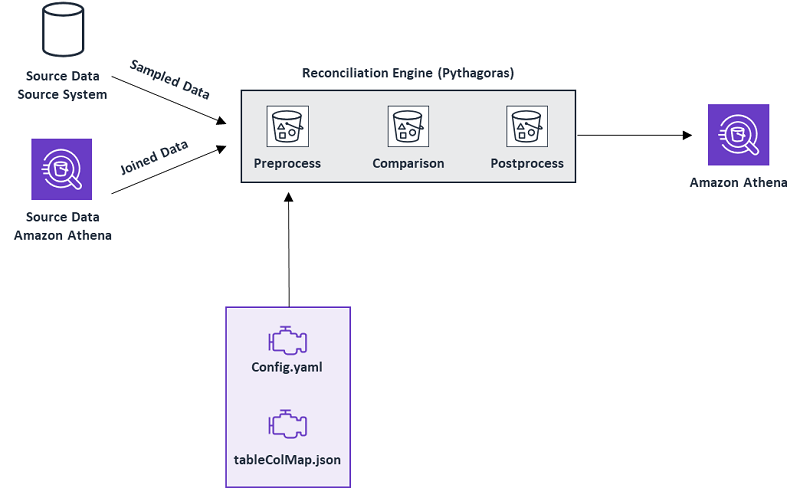
Build a distributed big data reconciliation engine using Amazon EMR and Amazon Athena
This is a guest post by Sara Miller, Head of Data Management and Data Lake, Direct Energy; and Zhouyi Liu, Senior AWS Developer, Direct Energy. Enterprise companies like Direct Energy migrate on-premises data warehouses and services to AWS to achieve fully manageable digital transformation of their organization. Freedom from traditional data warehouse constraints frees up […]
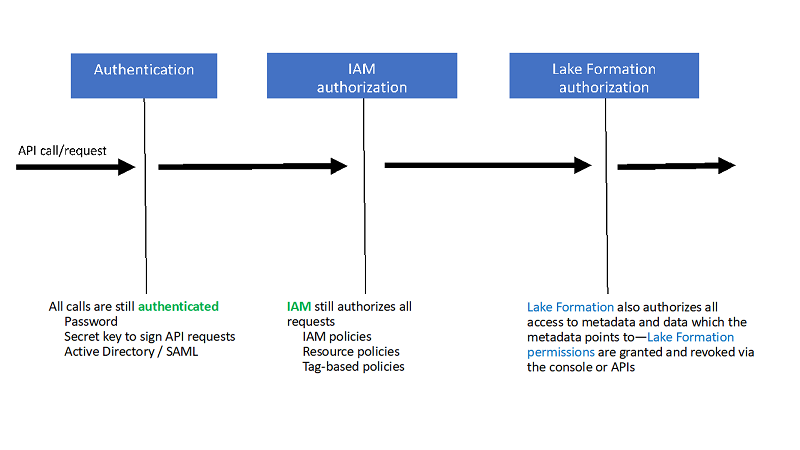
Enable fine-grained data access in Zeppelin Notebook with AWS Lake Formation
This post explores how you can use AWS Lake Formation integration with Amazon EMR (still in beta) to implement fine-grained column-level access controls while using Spark in a Zeppelin Notebook. My previous post Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena showed you a simple use case for extracting any Salesforce object data using AWS Glue and Apache Spark, saving it to Amazon Simple Storage Service (Amazon S3), cataloging the data using the Data Catalog in Glue, and querying it using Amazon Athena.
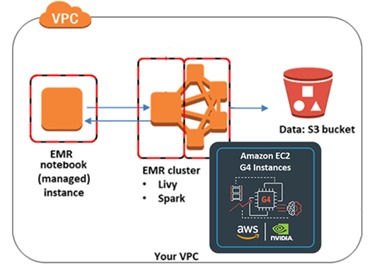
Improving RAPIDS XGBoost performance and reducing costs with Amazon EMR running Amazon EC2 G4 instances
This is a guest post by Kong Zhao, Solution Architect at NVIDIA Corporation This post shares how NVIDIA sped up RAPIDS XGBoost performance up to 4.5 times faster and reduced costs up to 5.4 times less by using Amazon EMR running Amazon Elastic Compute Cloud (Amazon EC2) G4 instances. Gradient boosting is a powerful machine […]
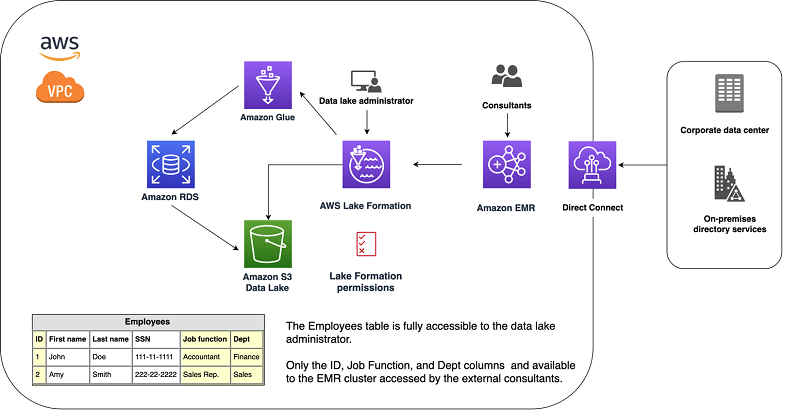
Control data access and permissions with AWS Lake Formation and Amazon EMR
What if you could control the access to your data lake centrally? Would it be more convenient to share specific data securely with internal and external customers? With AWS Lake Formation and its integration with Amazon EMR, you can easily perform these administrative tasks. This post goes through a use case and reviews the steps to control the data access and permissions of your existing data lake.