AWS Big Data Blog
Tag: Amazon EMR
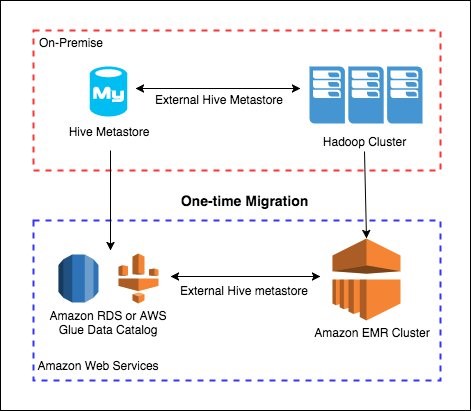
Migrate and deploy your Apache Hive metastore on Amazon EMR
Combining the speed and flexibility of Amazon EMR with the utility and ubiquity of Apache Hive provides you with the best of both worlds. However, getting started with big data projects can feel intimidating. Whether you want to deploy new data on EMR or migrate an existing project, this post provides you with the basics to get started.

Modify your cluster on the fly with Amazon EMR reconfiguration
April 2024: This post was reviewed for accuracy. If you are a developer or data scientist using long-running Amazon EMR clusters, you face fast-changing workloads. These changes often require different application configurations to run optimally on your cluster. With the reconfiguration feature, you can now change configurations on running EMR clusters. Starting with EMR release […]

Performance updates to Apache Spark in Amazon EMR 5.24 – Up to 13x better performance compared to Amazon EMR 5.16
Amazon EMR release 5.24.0 includes several optimizations in Spark that improve query performance. To evaluate the performance improvements, we used TPC-DS benchmark queries with 3-TB scale and ran them on a 6-node c4.8xlarge EMR cluster with data in Amazon S3. We observed up to 13X better query performance on EMR 5.24 compared to EMR 5.16 when operating with a similar configuration.
Amazon EMR Migration Guide
Today, we’re introducing the Amazon EMR Migrations Guide (first published June 2019.) This paper is a comprehensive guide to offer sound technical advice to help customers in planning how to move from on-premises big data deployments to EMR.

Optimize downstream data processing with Amazon Data Firehose and Amazon EMR running Apache Spark
This blog post shows how to use Amazon Kinesis Data Firehose to merge many small messages into larger messages for delivery to Amazon S3, which results in faster processing with Amazon EMR running Spark. This post also shows how to read the compressed files using Apache Spark that are in Amazon S3, which does not have a proper file name extension and store back in Amazon S3 in parquet format.

Trigger cross-region replication of pre-existing objects using Amazon S3 inventory, Amazon EMR, and Amazon Athena
In Amazon Simple Storage Service (Amazon S3), you can use cross-region replication (CRR) to copy objects automatically and asynchronously across buckets in different AWS Regions. CRR is a bucket-level configuration, and it can help you meet compliance requirements and minimize latency by keeping copies of your data in different Regions. CRR replicates all objects in […]

EMR Notebooks: A managed analytics environment based on Jupyter notebooks
Notebooks are increasingly becoming the standard tool for interactively developing big data applications. It’s easy to see why. Their flexible architecture allows you to experiment with data in multiple languages, test code interactively, and visualize large datasets. To help scientists and developers easily access notebook tools, we launched Amazon EMR Notebooks, a managed notebook environment […]

Test data quality at scale with Deequ
In this blog post, we introduce Deequ, an open source tool developed and used at Amazon. Deequ allows you to calculate data quality metrics on your dataset, define and verify data quality constraints, and be informed about changes in the data distribution. Instead of implementing checks and verification algorithms on your own, you can focus on describing how your data should look.

Optimize Amazon EMR costs with idle checks and automatic resource termination using advanced Amazon CloudWatch metrics and AWS Lambda
Many customers use Amazon EMR to run big data workloads, such as Apache Spark and Apache Hive queries, in their development environment. Data analysts and data scientists frequently use these types of clusters, known as analytics EMR clusters. Users often forget to terminate the clusters after their work is done. This leads to idle running […]
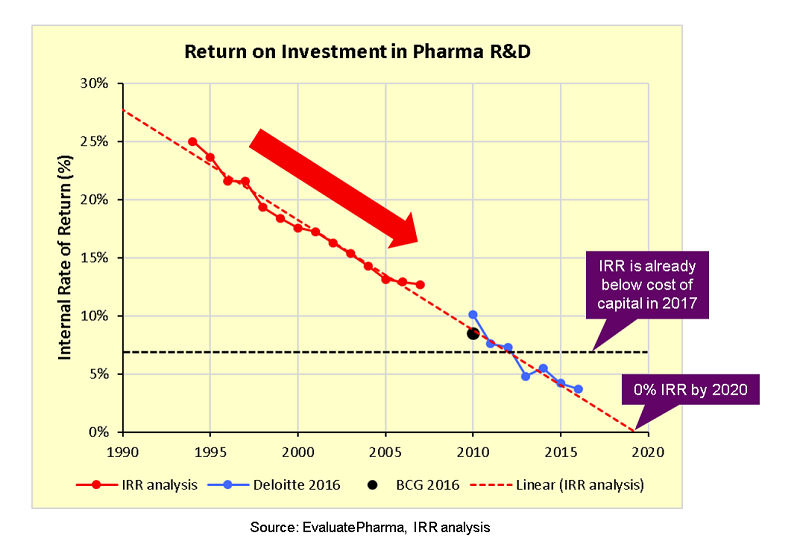
Improve clinical trial outcomes by using AWS technologies
We are living in a golden age of innovation, where personalized medicine is making it possible to cure diseases that we never thought curable. Digital medicine is helping people with diseases get healthier, and we are constantly discovering how to use the body’s immune system to target and eradicate cancer cells. According to a report […]