AWS Big Data Blog
Tag: AWS Step Functions

Modernize your legacy databases with AWS data lakes, Part 2: Build a data lake using AWS DMS data on Apache Iceberg
This is part two of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake (Apache Iceberg) using AWS Glue. We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. To review the first part of the series, where we load SQL Server data into Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (AWS DMS), see Modernize your legacy databases with AWS data lakes, Part 1: Migrate SQL Server using AWS DMS.

Build an ETL process for Amazon Redshift using Amazon S3 Event Notifications and AWS Step Functions
In this post we discuss how we can build and orchestrate in a few steps an ETL process for Amazon Redshift using Amazon S3 Event Notifications for automatic verification of source data upon arrival and notification in specific cases. And we show how to use AWS Step Functions for the orchestration of the data pipeline. It can be considered as a starting point for teams within organizations willing to create and build an event driven data pipeline from data source to data warehouse that will help in tracking each phase and in responding to failures quickly. Alternatively, you can also use Amazon Redshift auto-copy from Amazon S3 to simplify data loading from Amazon S3 into Amazon Redshift.

Run a data processing job on Amazon EMR Serverless with AWS Step Functions
Update Feb 2023: AWS Step Functions adds direct integration for 35 services including Amazon EMR Serverless. In the current version of this blog, we are able to submit an EMR Serverless job by invoking the APIs directly from a Step Functions workflow. We are using the Lambda only for polling the status of the job […]

Orchestrate Amazon Redshift-Based ETL workflows with AWS Step Functions and AWS Glue
In this post, I show how to use AWS Step Functions and AWS Glue Python Shell to orchestrate tasks for those Amazon Redshift-based ETL workflows in a completely serverless fashion. AWS Glue Python Shell is a Python runtime environment for running small to medium-sized ETL tasks, such as submitting SQL queries and waiting for a response. Step Functions lets you coordinate multiple AWS services into workflows so you can easily run and monitor a series of ETL tasks. Both AWS Glue Python Shell and Step Functions are serverless, allowing you to automatically run and scale them in response to events you define, rather than requiring you to provision, scale, and manage servers.
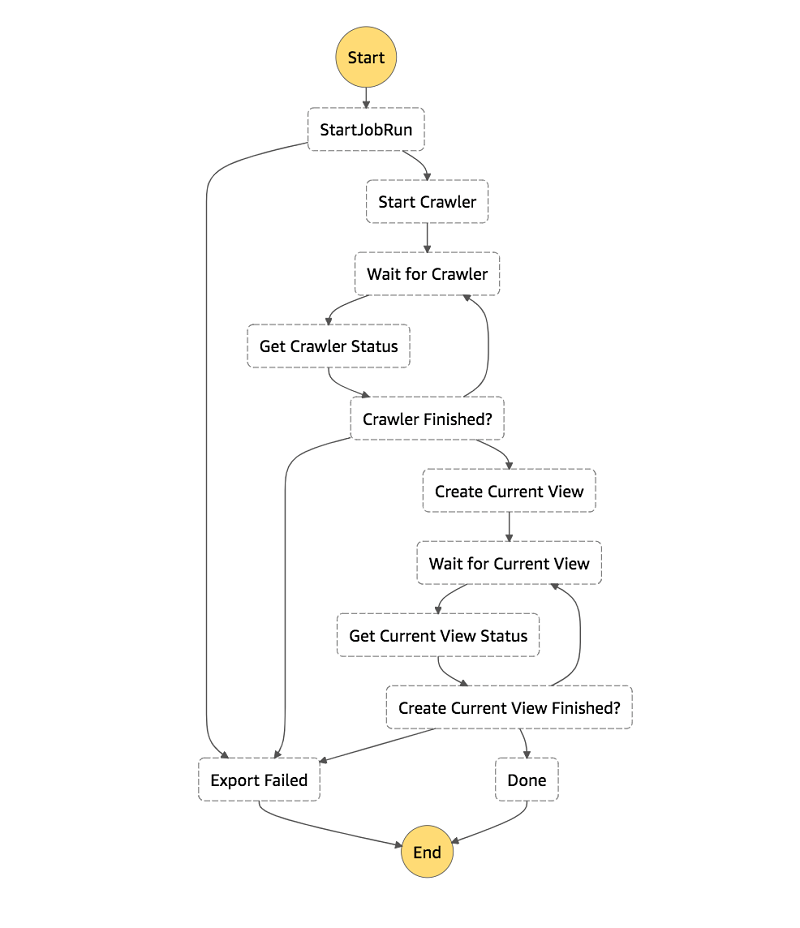
How to export an Amazon DynamoDB table to Amazon S3 using AWS Step Functions and AWS Glue
In this post, I show you how to use AWS Glue’s DynamoDB integration and AWS Step Functions to create a workflow to export your DynamoDB tables to S3 in Parquet. I also show how to create an Athena view for each table’s latest snapshot, giving you a consistent view of your DynamoDB table exports.