AWS Big Data Blog
Tag: jupyternotebook

Accelerate your data exploration and experimentation with the AWS Analytics Reference Architecture library
Organizations use their data to solve complex problems by starting small, running iterative experiments, and refining the solution. Although the power of experiments can’t be ignored, organizations have to be cautious about the cost-effectiveness of such experiments. If time is spent creating the underlying infrastructure for enabling experiments, it further adds to the cost. Developers […]

Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks
Enterprise customers are modernizing their data warehouses and data lakes to provide real-time insights, because having the right insights at the right time is crucial for good business outcomes. To enable near-real-time decision-making, data pipelines need to process real-time or near-real-time data. This data is sourced from IoT devices, change data capture (CDC) services like […]
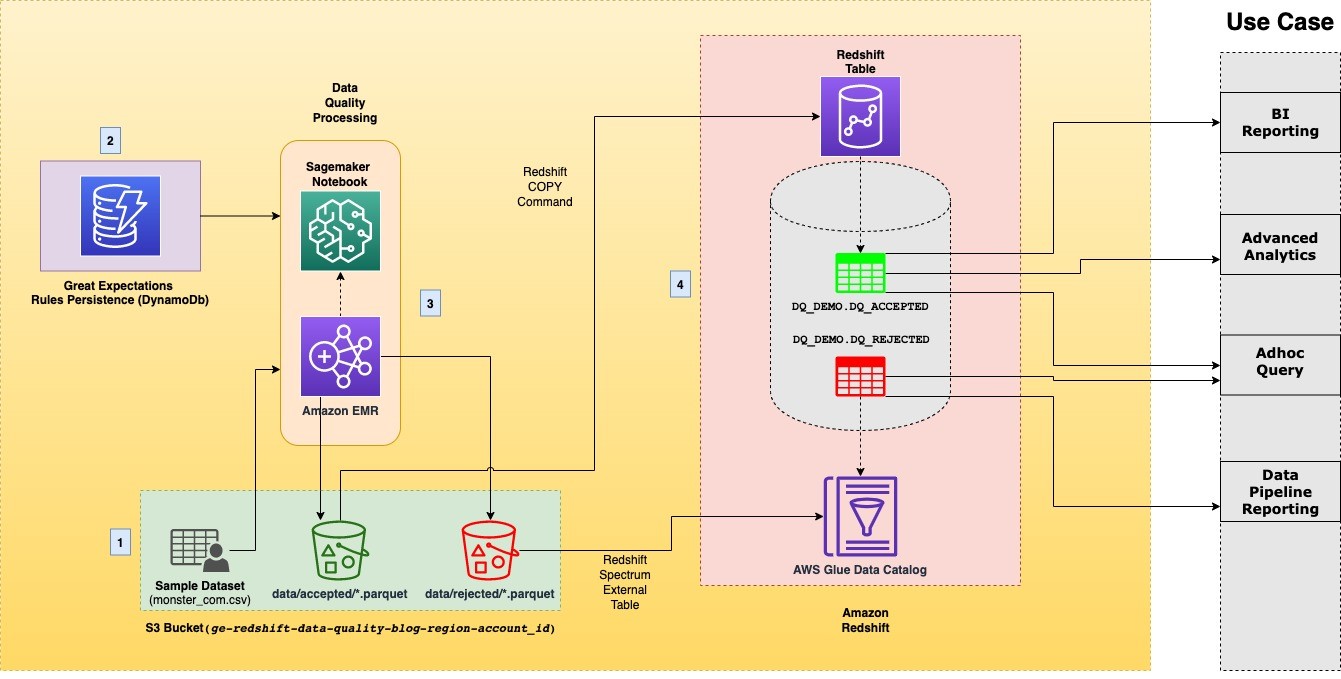
Provide data reliability in Amazon Redshift at scale using Great Expectations library
Ensuring data reliability is one of the key objectives of maintaining data integrity and is crucial for building data trust across an organization. Data reliability means that the data is complete and accurate. It’s the catalyst for delivering trusted data analytics and insights. Incomplete or inaccurate data leads business leaders and data analysts to make […]