AWS Big Data Blog
Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks
Enterprise customers are modernizing their data warehouses and data lakes to provide real-time insights, because having the right insights at the right time is crucial for good business outcomes. To enable near-real-time decision-making, data pipelines need to process real-time or near-real-time data. This data is sourced from IoT devices, change data capture (CDC) services like AWS Data Migration Service (AWS DMS), and streaming services such as Amazon Kinesis, Apache Kafka, and others. These data pipelines need to be robust, able to scale, and able to process large data volumes in near-real time. AWS Glue streaming extract, transform, and load (ETL) jobs process data from data streams, including Kinesis and Apache Kafka, apply complex transformations in-flight, and load it into a target data stores for analytics and machine learning (ML).
Hundreds of customers are using AWS Glue streaming ETL for their near-real-time data processing requirements. These customers required an interactive capability to process streaming jobs. Previously, when developing and running a streaming job, you had to wait for the results to be available in the job logs or persisted into a target data warehouse or data lake to be able to view the results. With this approach, debugging and adjusting code is difficult, resulting in a longer development timeline.
Today, we are launching a new AWS Glue streaming ETL feature to interactively develop streaming ETL jobs in AWS Glue Studio notebooks and interactive sessions.
In this post, we provide a use case and step-by-step instructions to develop and debug your AWS Glue streaming ETL job using a notebook.
Solution overview
To demonstrate the streaming interactive sessions capability, we develop, test, and deploy an AWS Glue streaming ETL job to process Apache Webserver logs. The following high-level diagram represents the flow of events in our job.

Apache Webserver logs are streamed to Amazon Kinesis Data Streams. An AWS Glue streaming ETL job consumes the data in near-real time and runs an aggregation that computes how many times a webpage has been unavailable (status code 500 and above) due to an internal error. The aggregate information is then published to a downstream Amazon DynamoDB table. As part of this post, we develop this job using AWS Glue Studio notebooks.
You can either work with the instructions provided in the notebook, which you download when instructed later in this post, or follow along with this post to author your first streaming interactive session job.
Prerequisites
To get started, click the Launch Stack button below, to run an AWS CloudFormation template on your AWS environment.
![]()
The template provisions a Kinesis data stream, DynamoDB table, AWS Glue job to generate simulated log data, and the necessary AWS Identity and Access Management (IAM) role and polices. After you deploy your resources, you can review the Resources tab on the AWS CloudFormation console for detailed information.
Set up the AWS Glue streaming interactive session job
To set up your AWS Glue streaming job, complete the following steps:
- Download the notebook file and save it to a local directory on your computer.
- On the AWS Glue console, choose Jobs in the navigation pane.
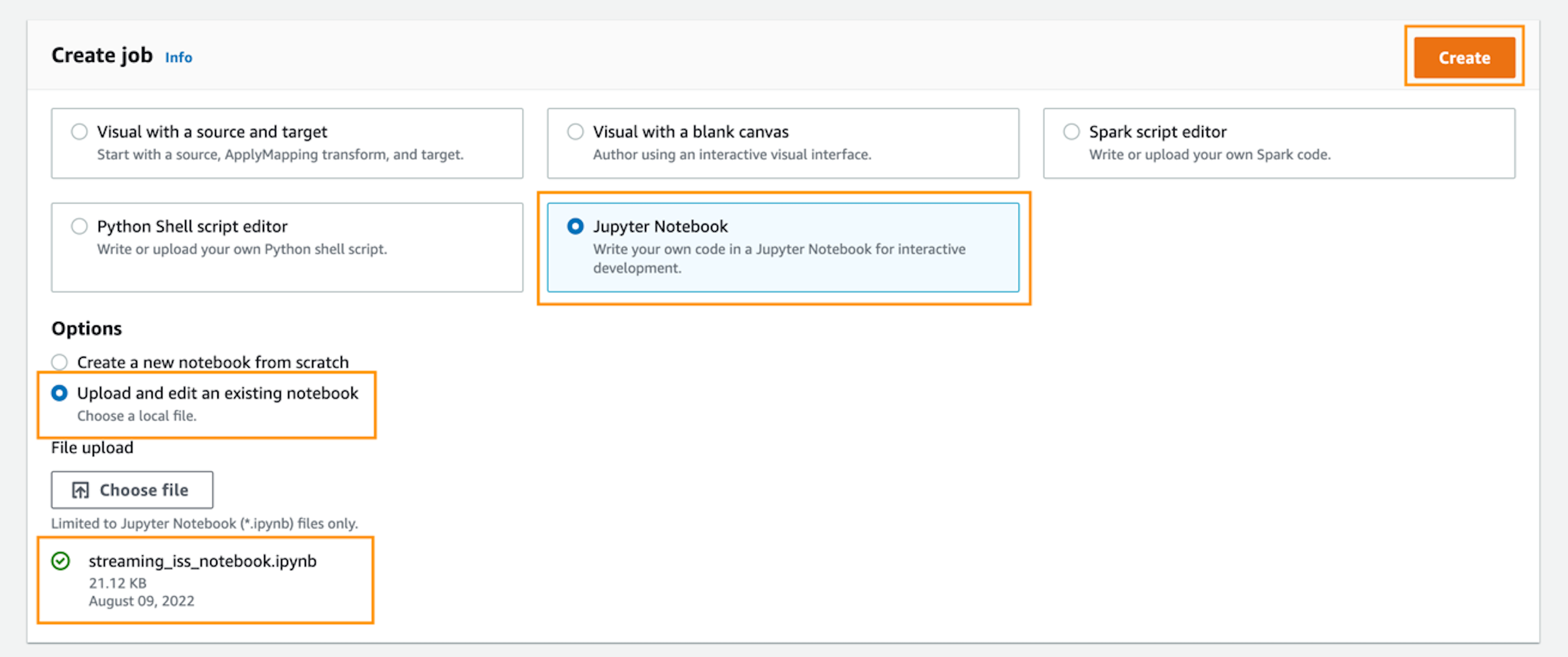
- Choose Create job.
- Select Jupyter Notebook.
- Under Options, select Upload and edit an existing notebook.
- Choose Choose file and browse to the notebook file you downloaded.
- Choose Create.
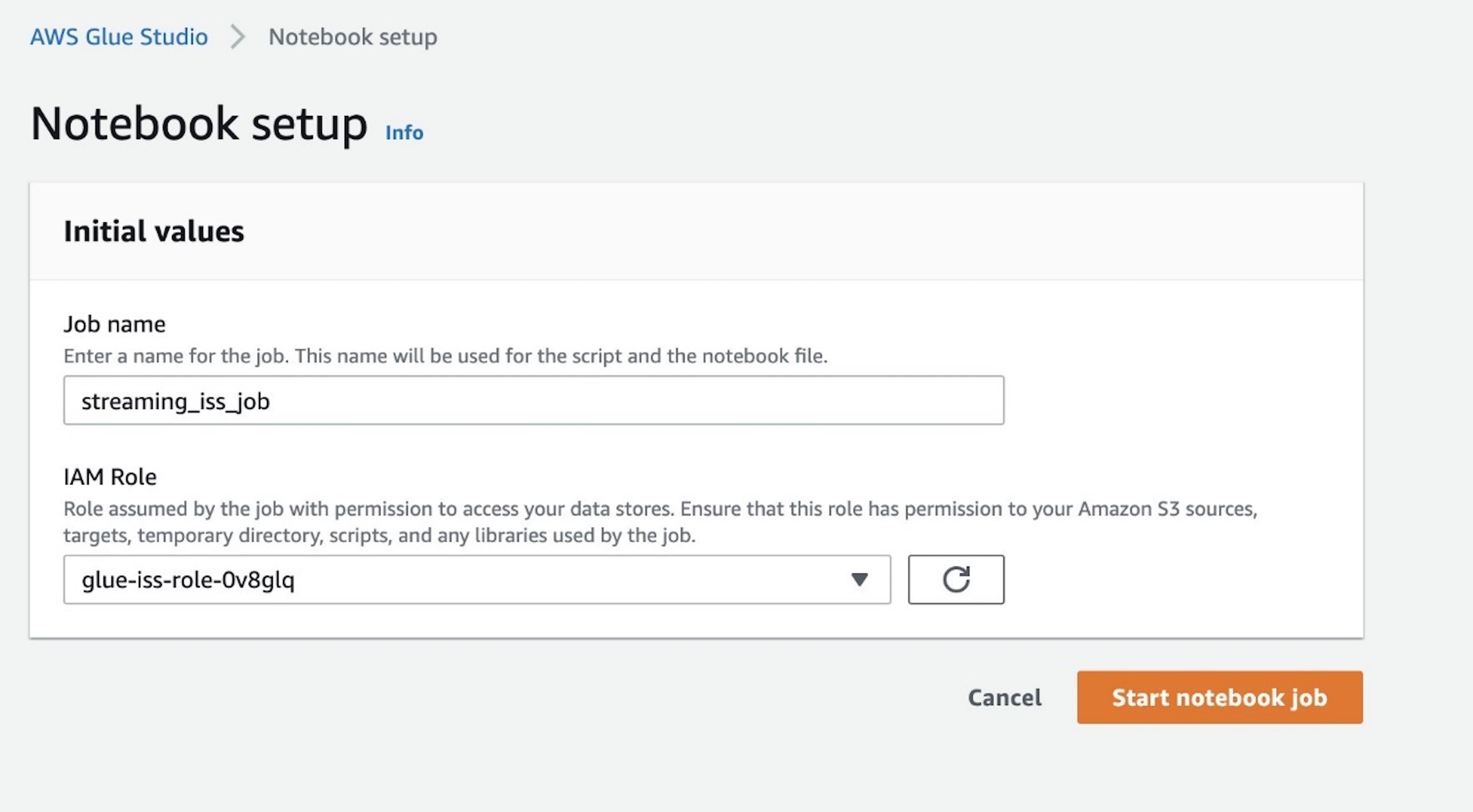
- For Job name¸ enter a name for the job.
- For IAM Role, use the role
glue-iss-role-0v8glq, which is provisioned as part of the CloudFormation template. - Choose Start notebook job.
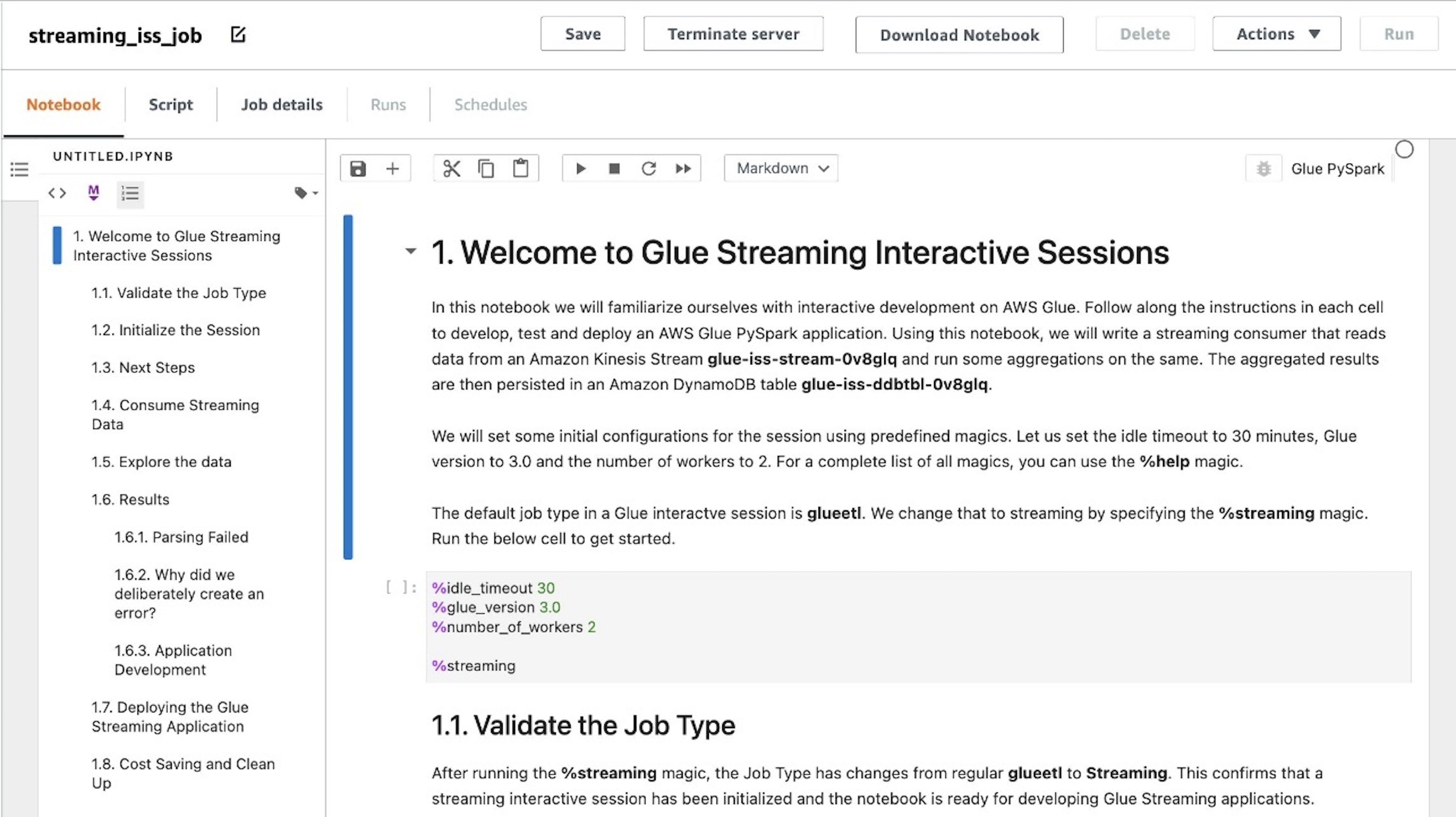
You can see that the notebook is loaded into the UI. There are markdown cells with instructions as well as code blocks that you can run sequentially. You can either run the instructions on the notebook or follow along with this post to continue with the job development.
Run notebook cells
Let’s run the code block that has the magics. The notebook has notes on what each magic does.
- Run the first cell.
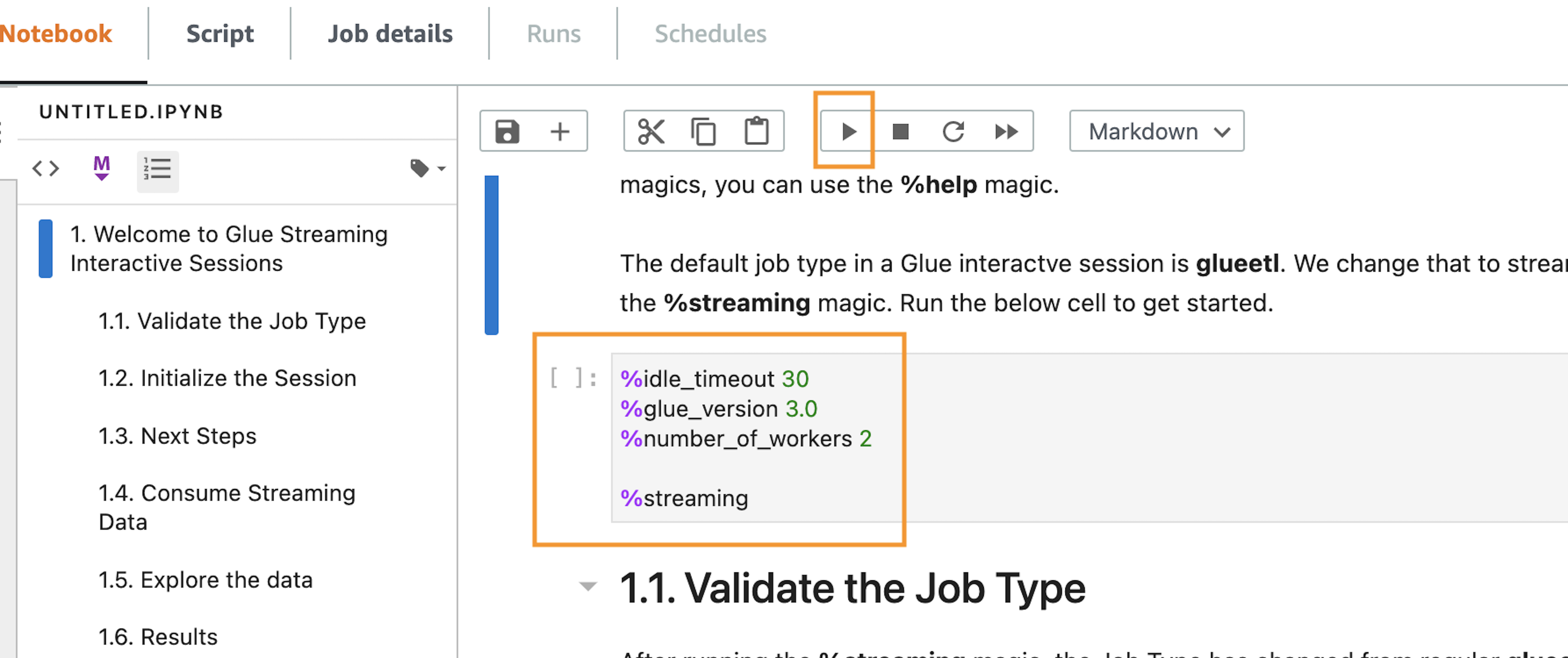
After running the cell, you can see in the output section that the defaults have been reconfigured.
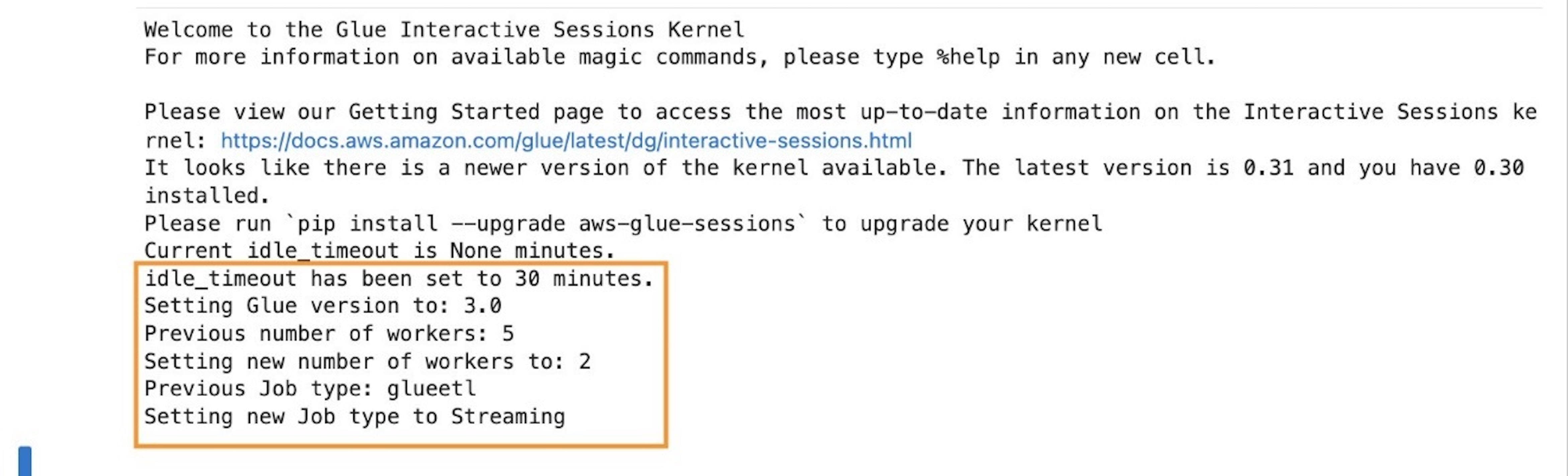
In the context of streaming interactive sessions, an important configuration is job type, which is set to streaming. Additionally, to minimize costs, the number of workers is set to 2 (default 5), which is sufficient for our use case that deals with a low-volume simulated dataset.
Our next step is to initialize an AWS Glue streaming session.
- Run the next code cell.
After we run this cell, we can see that a session has been initialized and a session ID is created.
A Kinesis data stream and AWS Glue data generator job that feeds into this stream have already been provisioned and triggered by the CloudFormation template. With the next cell, we consume this data as an Apache Spark DataFrame.
- Run the next cell.
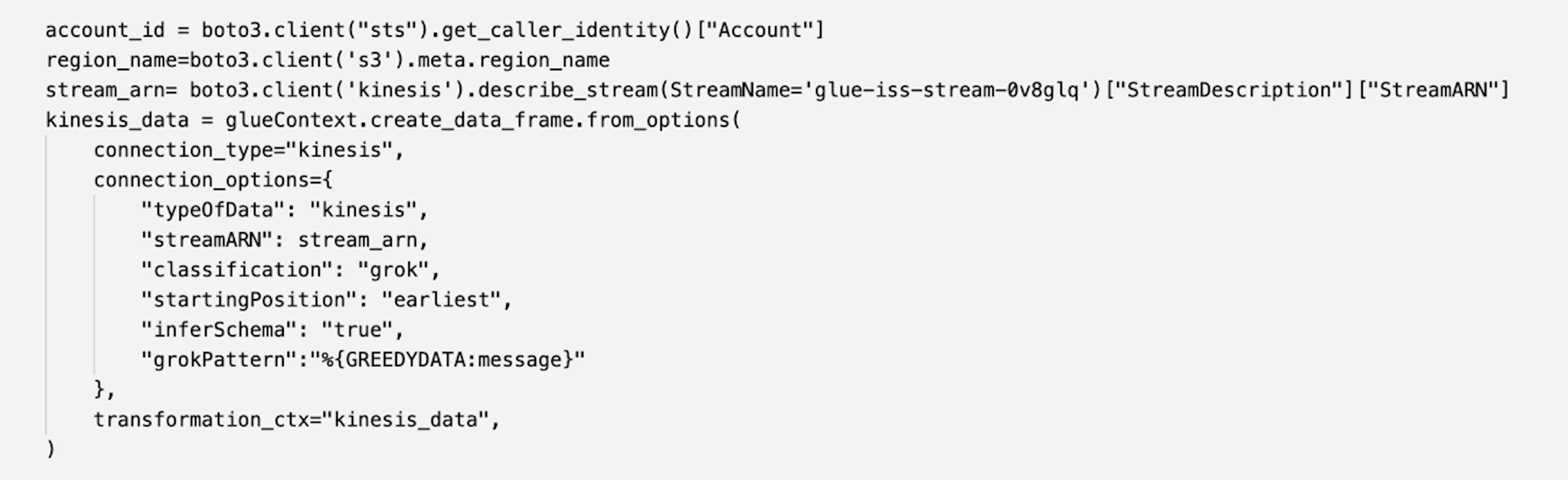
Because there are no print statements, the cells don’t show any output. You can proceed to run the following cells.
Explore the data stream
To help enhance the interactive experience in AWS Glue interactive sessions, GlueContext provides the method getSampleStreamingDynamicFrame. It provides a snapshot of the stream in a static DynamicFrame. It takes three arguments:
- The Spark streaming DataFrame
- An options map
- A
writeStreamFunctionto apply a function to every sampled record
Available options are as follows:
- windowSize – Also known as the micro-batch duration, this parameter determines how long a streaming query will wait after the previous batch was triggered.
- pollingTimeInMs – This is the total length of time the method will run. It starts at least one micro-batch to obtain sample records from the input stream. The time unit is milliseconds, and the value should be greater than the
windowSize. - recordPollingLimit – This is defaulted to 100, and helps you set an upper bound on the number of records that is retrieved from the stream.
Run the next code cell and explore the output.
We see that the sample consists of 100 records (the default record limit), and we have successfully displayed the first 10 records from the sample.
Work with the data
Now that we know what our data looks like, we can write the logic to clean and format it for our analytics.
Run the code cell containing the reformat function.
Note that Python UDFs aren’t the recommended way to handle data transformations in a Spark application. We use reformat() to exemplify troubleshooting. When working with a real-world production application, we recommend using native APIs wherever possible.
We see that the code cell failed to run. The failure was on purpose. We deliberately created a division by zero exception in our parser.
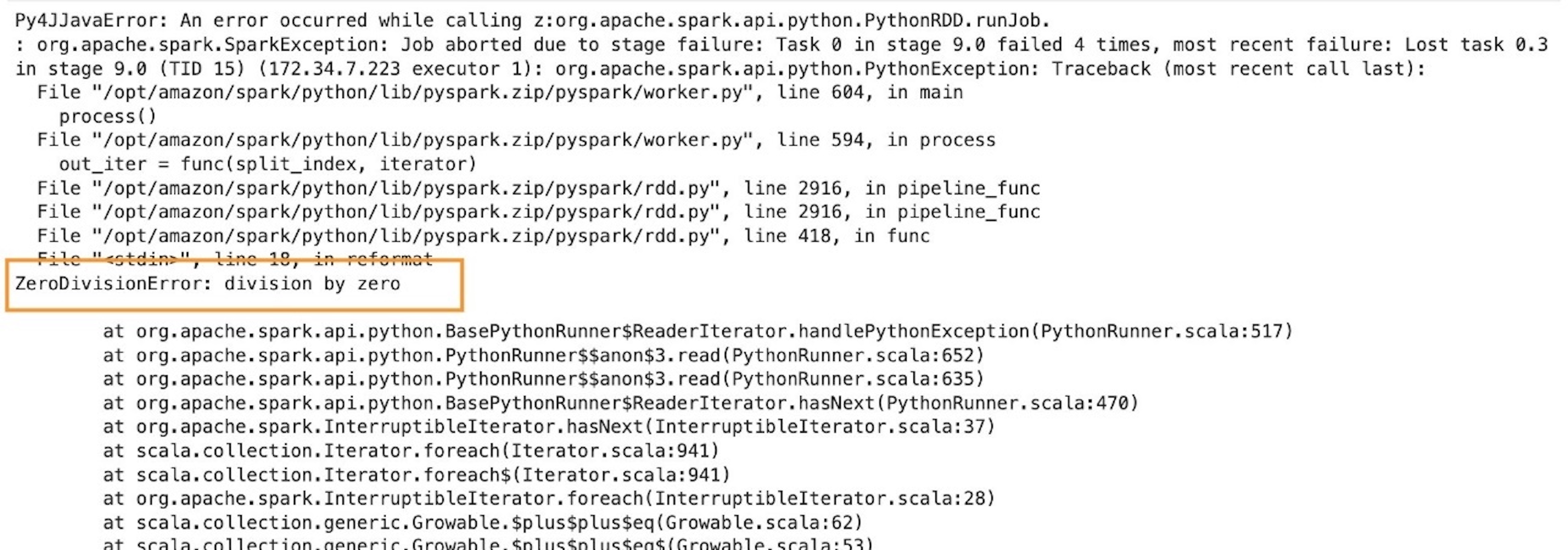
Failure and recovery
In case of a regular AWS Glue job, for any error, the whole application exits, and you have to make code changes and resubmit the application. However, in case of interactive sessions, the coding context and definitions are fully preserved and the session is still operational. There is no need to bootstrap a new cluster and rerun all the preceding transformation. This allows you to focus on quickly iterating your batch function implementation to obtain the desired outcome. You can fix the defects and run them in a matter of seconds.
To test this out, go back to the code and comment or delete the erroneous line error_line=1/0 and rerun the cell.
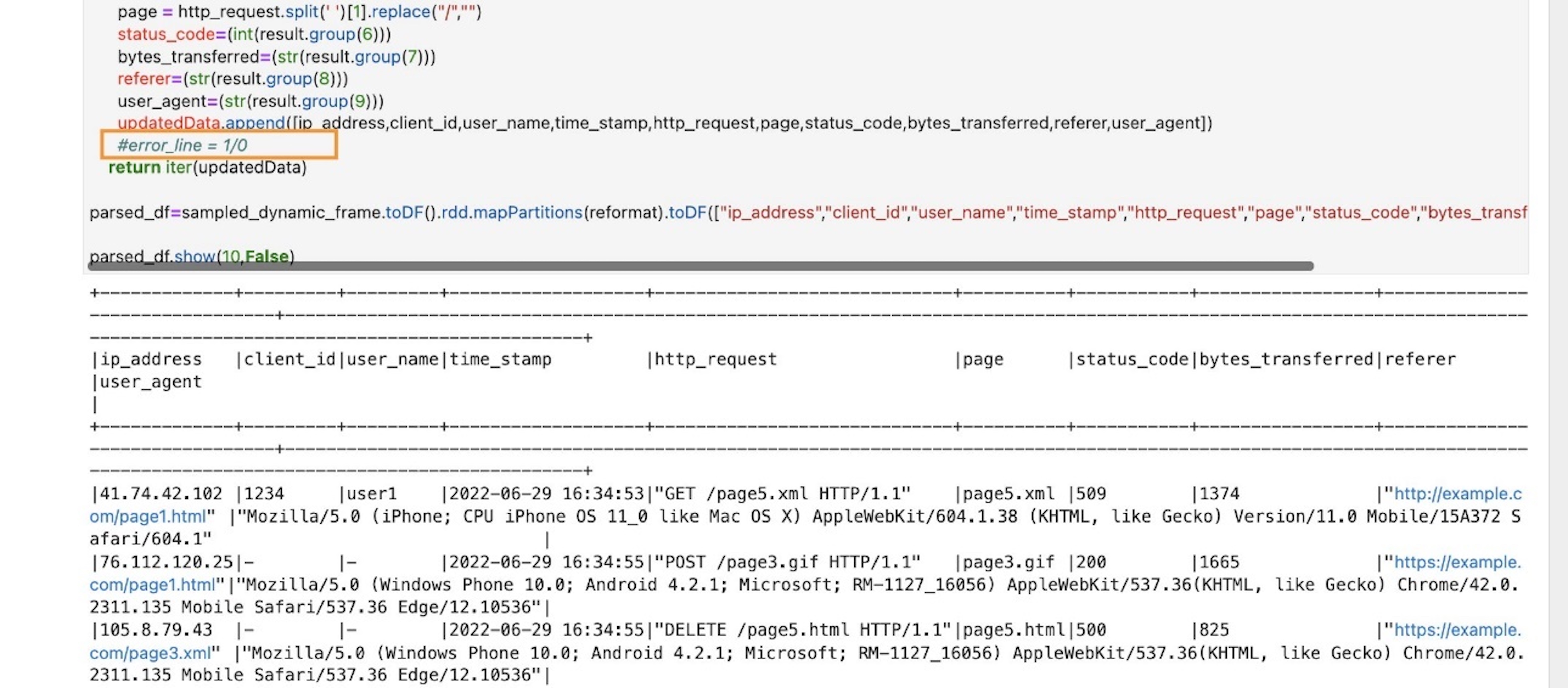
Implement business logic
Now that we have successfully tested our parsing logic on the sample stream, let’s implement the actual business logic. The logics are implemented in the processBatch method within the next code cell. In this method, we do the following:
- Pass the streaming DataFrame in micro-batches
- Parse the input stream
- Filter messages with status code >=500
- Over a 1-minute interval, get the count of failures per webpage
- Persist the preceding metric to a DynamoDB table (
glue-iss-ddbtbl-0v8glq)
- Run the next code cell to trigger the stream processing.

- Wait a few minutes for the cell to complete.
- On the DynamoDB console, navigate to the Items page and select the
glue-iss-ddbtbl-0v8glqtable.
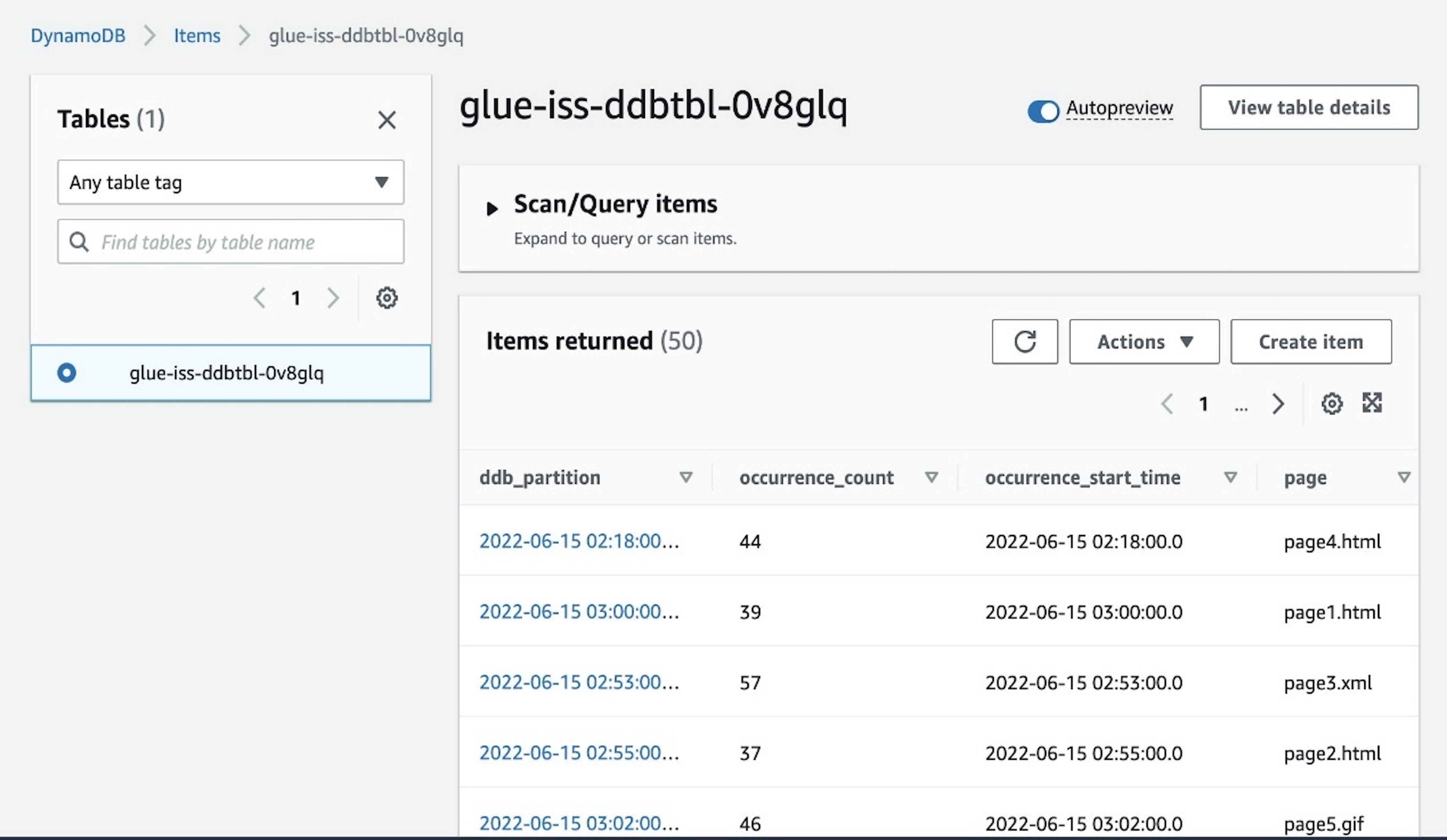
The page displays the aggregated results that have been written by our interactive session job.
Deploy the streaming job
So far, we have been developing and testing our application using the streaming interactive sessions. Now that we’re confident of the job, let’s convert this into an AWS Glue job. We have seen that the majority of code cells are doing exploratory analysis and sampling, and aren’t required to be a part of the main job.
A commented code cell that represents the whole application is provided to you. You can uncomment the cell and delete all other cells. Another option would be to not use the commented cell, but delete just the two cells from the notebook that do the sampling or debugging and print statements.
To delete a cell, choose the cell and then choose the delete icon.
Now that you have the final application code ready, save and deploy the AWS Glue job by choosing Save.

A banner message appears when the job is updated.

Explore the AWS Glue job
After you save the notebook, you should be able to access the job like any regular AWS Glue job on the Jobs page of the AWS Glue console.
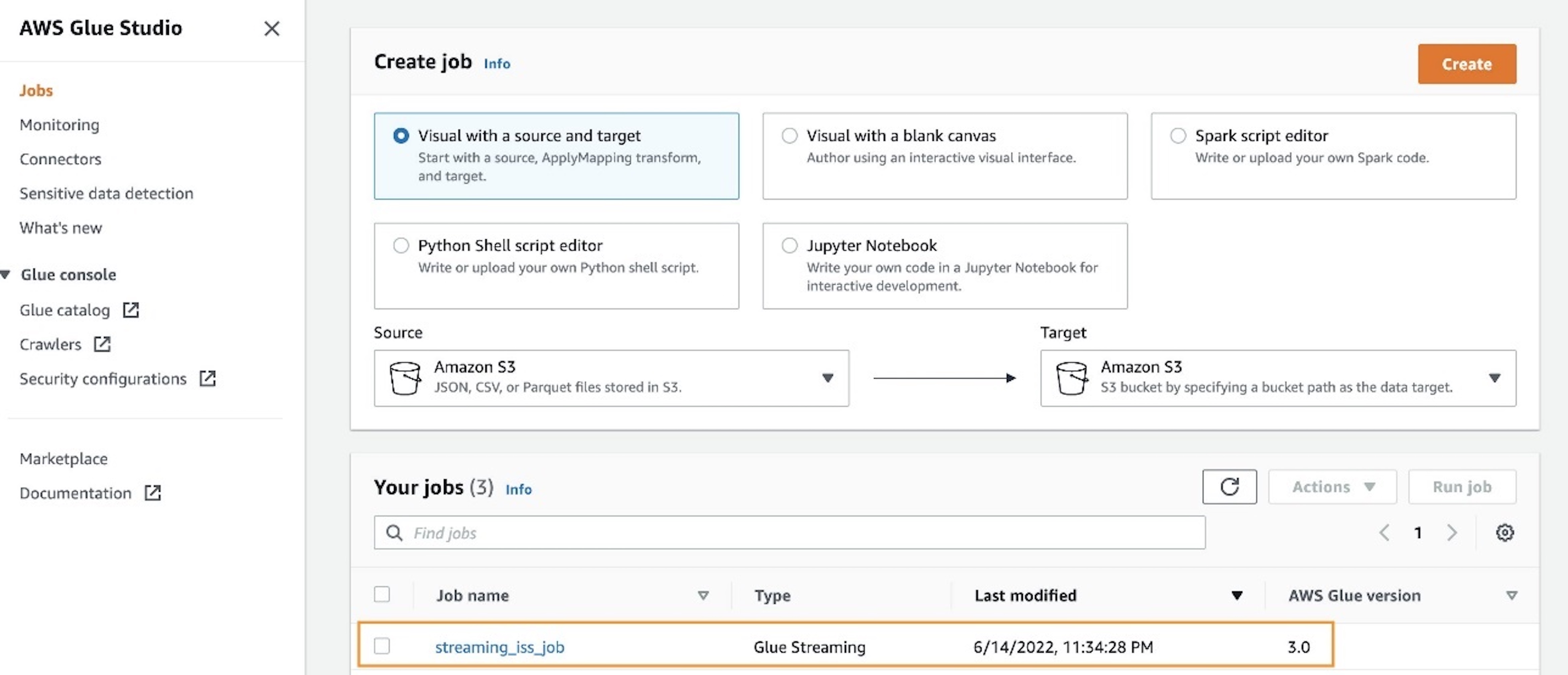
Additionally, you can look at the Job details tab to confirm the initial configurations, such as number of workers, have taken effect after deploying the job.
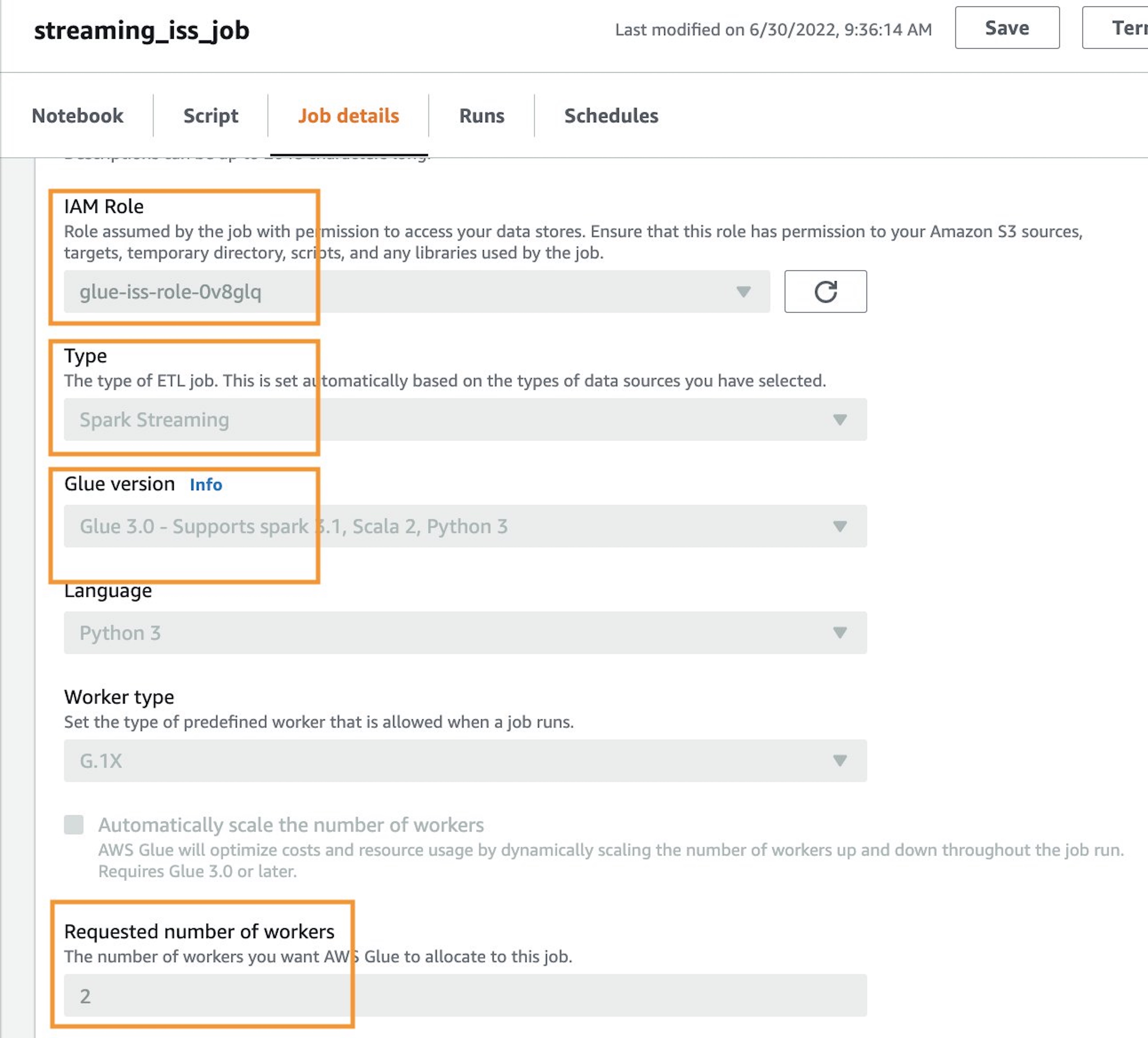
Run the AWS Glue job
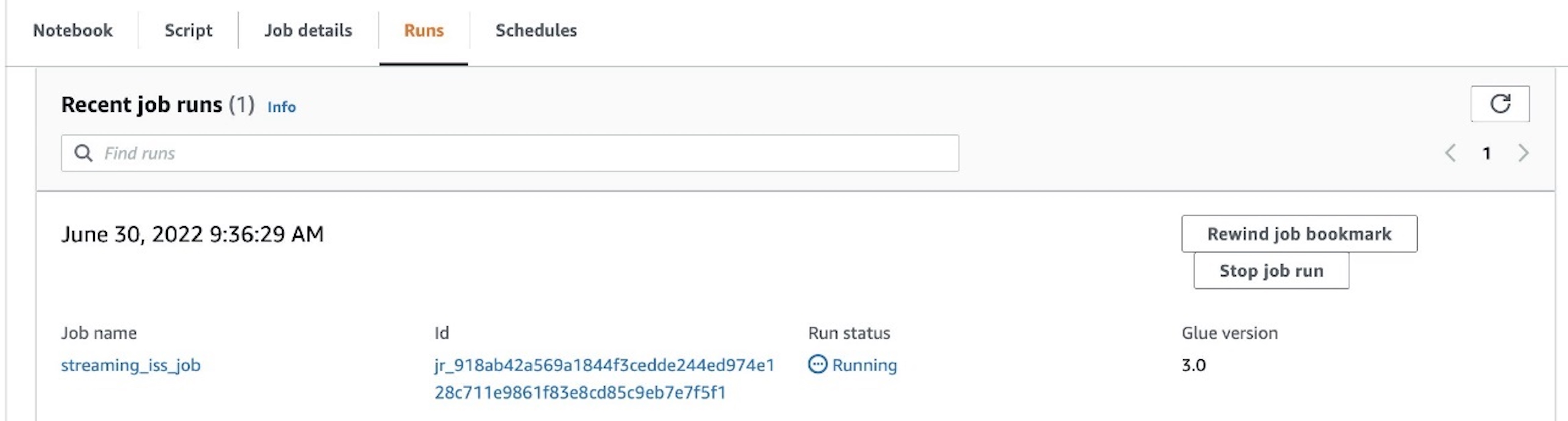
If needed, you can choose Run to run the job as an AWS Glue streaming job.
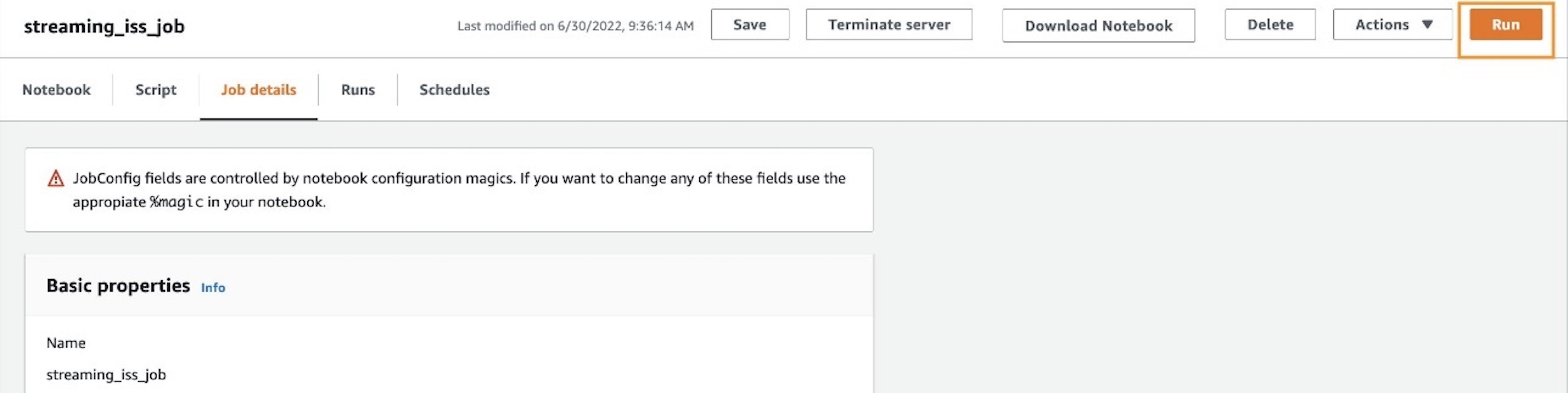
To track progress, you can access the run details on the Runs tab.
Clean up
To avoid incurring additional charges to your account, stop the streaming job that you started as part of the instructions. Also, on the AWS CloudFormation console, select the stack that you provisioned and delete it.
Conclusion
In this post, we demonstrated how to do the following:
- Author a job using notebooks
- Preview incoming data streams
- Code and fix issues without having to publish AWS Glue jobs
- Review the end-to-end working code, remove any debugging, and print statements or cells from the notebook
- Publish the code as an AWS Glue job
We did all of this via a notebook interface.
With these improvements in the overall development timelines of AWS Glue jobs, it’s easier to author jobs using the streaming interactive sessions. We encourage you to use the prescribed use case, CloudFormation stack, and notebook to jumpstart your individual use cases to adopt AWS Glue streaming workloads.
The goal of this post was to give you hands-on experience working with AWS Glue streaming and interactive sessions. When onboarding a productionized workload onto your AWS environment, based on the data sensitivity and security requirements, ensure you implement and enforce tighter security controls.
About the authors
 Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
 Linan Zheng is a Software Development Engineer at AWS Glue Streaming Team, helping building the serverless data platform. His works involve large scale optimization engine for transactional data formats and streaming interactive sessions.
Linan Zheng is a Software Development Engineer at AWS Glue Streaming Team, helping building the serverless data platform. His works involve large scale optimization engine for transactional data formats and streaming interactive sessions.
 Roman Gavrilov is an Engineering Manager at AWS Glue. He has over a decade of experience building scalable Big Data and Event-Driven solutions. His team works on Glue Streaming ETL to allow near real time data preparation and enrichment for machine learning and analytics.
Roman Gavrilov is an Engineering Manager at AWS Glue. He has over a decade of experience building scalable Big Data and Event-Driven solutions. His team works on Glue Streaming ETL to allow near real time data preparation and enrichment for machine learning and analytics.
 Shiv Narayanan is a Senior Technical Product Manager on the AWS Glue team. He works with AWS customers across the globe to strategize, build, develop, and deploy modern data platforms.
Shiv Narayanan is a Senior Technical Product Manager on the AWS Glue team. He works with AWS customers across the globe to strategize, build, develop, and deploy modern data platforms.