AWS Database Blog
Build a dynamic workflow orchestration engine with Amazon DynamoDB and AWS Lambda
Modern applications, especially those using AI capabilities, often require workflows that can adapt their task sequences and execution paths at runtime. Although solutions such as AWS Step Functions excel at orchestrating predefined workflows, some use cases demand more flexibility, such as when the sequence of tasks isn’t known until runtime.
In this post, I show you how to build a serverless workflow orchestration engine that uses Amazon DynamoDB and AWS Lambda. The complete implementation is available in a GitHub repository, which includes two fully functional examples that you can deploy and run immediately to see the orchestration engine in action. The instructions to deploy the solution are available at the end of this post. You’ll learn how to:
- Create dynamic workflows that are defined at runtime.
- Implement flexible task dependencies by using DynamoDB.
- Handle parallel execution with fan-in and fan-out patterns.
- Manage large payloads efficiently with Amazon Simple Storage Service (Amazon S3).
- Build resilient error handling and retry mechanisms.
Using this solution, you can submit dynamically created workflows, run tasks in parallel, and handle complex dependency patterns—all while maintaining a serverless architecture that scales automatically and optimizes costs by paying only for resources used during runtime. This post demonstrates the solution through two practical examples:
- A mathematical workflow that shows the core orchestration capabilities
- A financial analysis workflow that demonstrates how to coordinate multiple AI agents working in parallel
By the end of this post, you’ll have a fully functional workflow engine that you can adapt for your own use cases, whether they involve data processing, AI agent orchestration, or other complex and unpredictable task coordination needs.
Building custom workflow orchestration is complex and resource-intensive. Before implementing this solution, carefully evaluate whether AWS Step Functions or an equivalent workflow offering meets your needs. Step Functions provides managed infrastructure, visual monitoring, built-in error handling, and enterprise features for most workflow use cases, including predefined patterns with dynamic data, parallel processing, and map-reduce operations. This custom solution is only appropriate when you need truly dynamic workflows where the task structure is unknown until runtime (such as AI-generated workflows or adaptive research pipelines) and cannot be predetermined at design time. The operational overhead of this approach includes custom monitoring, error handling, scaling logic, security updates, and long-term maintenance that managed services handle automatically. For most use cases, start with Step Functions and only consider custom orchestration if you encounter specific limitations that managed services cannot address.
When should you use this solution?
This dynamic workflow orchestration solution addresses the following situations in which the workflow structure cannot be known in advance and must adapt to runtime conditions.
AI-powered research and analysis often require workflows that change based on the complexity of user queries. When a user asks to “analyze the electric vehicle market in Southeast Asia,” the system must dynamically deploy specialized agents based on query complexity and available data sources. Some queries might require market data agents, regulatory research agents, and competitive analysis agents working in parallel, but simpler queries need fewer resources. The workflow structure emerges as the system discovers what information is accessible and determines which tasks should run first to optimize the overall analysis time.
Dynamic software testing faces similar challenges when adapting to different types of code changes. The testing workflow must adapt based on code change analysis. Simple bug fixes in isolated functions need only targeted unit tests for the affected components. However, architectural changes that modify database schemas or API contracts trigger comprehensive testing workflows that include integration tests, performance benchmarks, security scans, and compatibility checks across multiple environments. The system analyzes the code changes and constructs the appropriate testing workflow rather than running the same predetermined test suite every time.
Incident response workflows encounter unpredictable system failures that require adaptive responses. When a database performance issue occurs, the workflow might spawn query analysis tasks, index optimization checks, and resource utilization monitoring. Network connectivity problems trigger different diagnostic tasks such as routing analysis, DNS resolution checks, and bandwidth testing. As investigations progress and reveal the scope of the problem, the workflow adds new diagnostic tasks based on real-time findings rather than following a fixed troubleshooting checklist.
Consider this blog post’s solution when your application needs to build workflows on the fly based on user input, system conditions, or data analysis results. It works well when you can’t predict the exact sequence of tasks ahead of time and need the flexibility to adapt your workflow as conditions change.
Solution overview
This solution uses AWS serverless technologies to create a flexible, event-driven workflow orchestration engine. At its core, the architecture uses:
- DynamoDB – To track task dependencies and state.
- DynamoDB Streams – To trigger task execution when dependencies are satisfied.
- Lambda – To execute tasks and monitor the workflow state.
- Amazon S3 – To store task payloads and outputs.
- AWS Systems Manager – To store environment variables.
This architecture allows for the processing of dynamically created workflows, with tasks that can have arbitrary dependencies, and the ability to fan out to multiple downstream tasks or fan in from multiple upstream tasks (where one task waits for multiple preceding tasks to complete) as needed. The system is completely serverless, scales automatically, and only incurs costs when workflows are running. Key advantages of this approach include:
- No predefined workflows – Execute transient workflows that are created dynamically at runtime.
- Arbitrary dependencies – Any task can depend on any number of other tasks, enabling complex patterns.
- Automatic cleanup – Time To Live (TTL)-enabled DynamoDB items are automatically deleted after 10 days, and an Amazon S3 lifecycle policy ensures that Amazon S3 objects are also deleted after 10 days.
- Cost-efficiency – Pay only for the resources used during workflow execution.
- Scalability – Handles any number of concurrent workflows without preprovisioning.
Prerequisites
Prerequisites for the solution are available in the README.md of the GitHub repository.
Building the workflow engine
The solution architecture consists of these key components working together:
- Client application – Submits workflow definitions (including tasks, dependencies and initial payloads).
- DynamoDB (Task metadata) – Stores task metadata, including definitions, status, and dependency information.
- DynamoDB Streams – Captures changes to task items and triggers the monitor function.
- AWS Lambda (Monitor function) – Processes stream events and invokes the execute function when tasks are ready.
- AWS Lambda (Execute function) – Invokes the task function (functions containing task-specific processing logic), and manages execution state, response updates, and error handling.
- AWS Lambda (Task function) – Performs task-specific work such as math operations and AI agent execution.
- Amazon S3 (Task payloads) – Stores task payloads and outputs.
The following diagram shows the solution architecture.
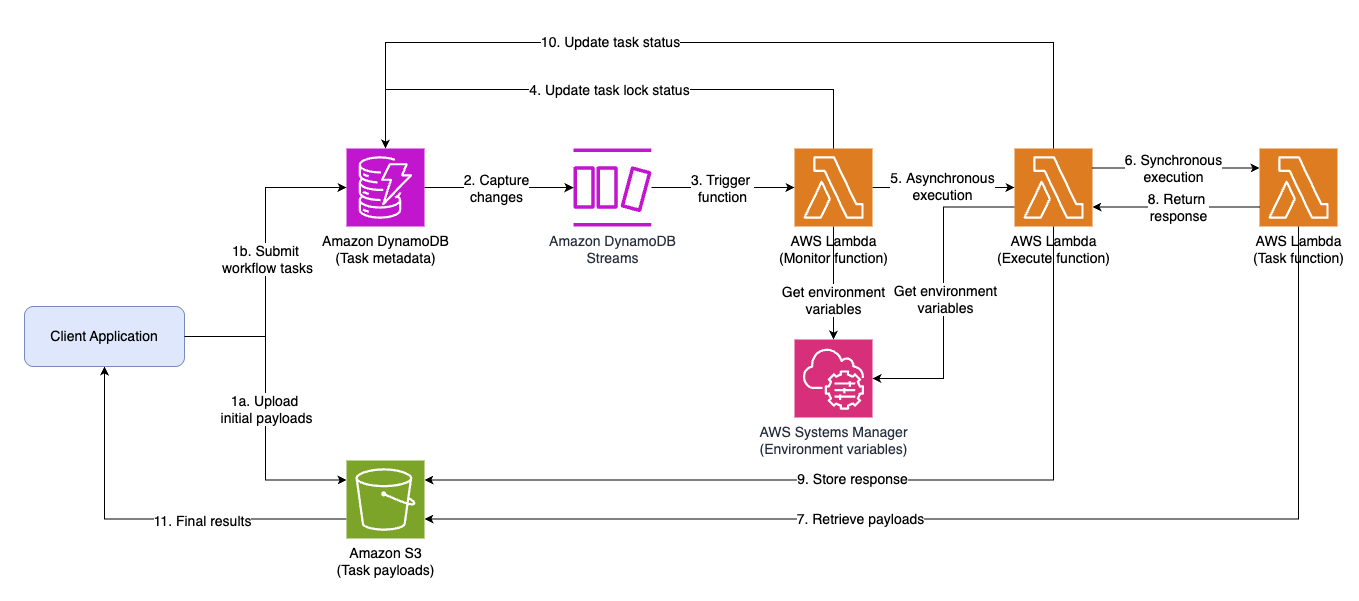
Here is how a workflow executes step by step:
- The client application submits a workflow definition with tasks and their dependencies.
- Initial task payloads are uploaded to Amazon S3.
- Each task is stored in DynamoDB with status=PENDING.
- Changes to DynamoDB are captured in DynamoDB Streams.
- The monitor function is triggered, and it determines the readiness of the task by checking the status of its dependencies.
- If there are no dependencies or all dependencies have status=COMPLETED, the monitor function updates DynamoDB with locked=YES to stop all other updates to this task.
- The monitor function invokes the appropriate execute function asynchronously.
- The execute function receives the task details and invokes the appropriate task function synchronously.
- The task function receives the task details and converts it to the full-length payload by retrieving it from Amazon S3.
- The task function processes the task and, upon completion, returns its output as response back to the execute function.
- The execute function reviews the Lambda execution response and automatically retries the execution if an error is detected. Otherwise, it stores the response in Amazon S3 for retrieval by dependent tasks.
- The execute function updates DynamoDB with status=COMPLETED, locked=NO and links its Amazon S3 payload location to each dependent task in DynamoDB.
- The process (steps 2–10) iterates until all tasks reach a terminal state (COMPLETED or ERROR), and the final results are retrieved by the client application.
Understanding workflow definitions
Workflow definitions are the core input to this post’s orchestration engine, defining the tasks to be executed and their dependencies. These definitions can be created in two ways:
1. A programmatic approach
You can create workflow definitions programmatically by constructing a JSON array of tasks. This approach is useful when you have predetermined logic for creating workflows based on specific conditions or patterns.
2. An LLM-based approach
You can use a workflow agent that uses large language models (LLMs) to dynamically generate workflow definitions based on natural language requirements. This agent analyzes the user’s request and creates an appropriate workflow structure, determining which specialized agents to use and how to organize their dependencies for optimal parallel execution. Read agents.py in the GitHub repository for details about how to use LLMs to generate workflow definitions.
Workflow definition format
A workflow definition is a JSON array in which each task contains the following structure:
Each task object contains:
- task_id – A unique identifier for the task within the workflow
- payload – The input data for the task
- retry_enabled – Whether the task should automatically retry during failures
- in_dependencies – An array of tasks that must complete before this task can execute
- out_dependencies – An array of tasks that will receive this task’s output as input
For AI agent workflows, the payload would include the agent to route the task to, and the corresponding message for the agent to process. An example would be:
This format allows for complex dependency patterns including parallel execution, fan-in/fan-out patterns, and sequential processing chains.
DynamoDB schema design
The DynamoDB table uses a composite primary key:
- Partition key – run_id – A unique identifier for each workflow execution
- Sort key – task_id – A unique identifier for each task within a workflow
Each task item contains:
- status – The task’s status (PENDING, COMPLETED, ERROR)
- version – For optimistic locking to handle concurrent updates
- locked – Indicates if a task is currently being processed
- payload – The task’s input data (or an Amazon S3 path to it)
- retry_enabled – Whether the task should automatically retry during failures
- task_output – The task’s output data (or an Amazon S3 path to it)
- in_dependencies – A list of tasks that must be completed before this task can run
- out_dependencies – A list of tasks that depend on this task’s completion
- function_name – The Lambda function to execute for this task
- ttl – TTL for automatic cleanup of completed workflows
- task_duration – Optional field to track execution time for performance monitoring
- error_message – Detailed error information if the task fails
Here’s an example of a task item in DynamoDB:
Using this schema design, you can efficiently query all tasks for a specific workflow run and track the complex dependency relationships between tasks.
Using DynamoDB Streams to trigger task execution
DynamoDB Streams captures item-level changes in the table and triggers the monitor function. When a task is created or updated, the monitor function:
- Checks if the task’s status is PENDING.
- Verifies if all input dependencies are satisfied (COMPLETED).
- If ready, invokes the execute function.
This event-driven approach eliminates the need for polling and helps to ensure that tasks start as soon as their dependencies are met. In this post’s implementation, the Lambda function is configured with the DynamoDB stream as an event source and configure the event source with a batch size of 1 and a parallelization factor of 10 to optimize for low latency and high throughput. You can view the implementation of the stream processing function on GitHub.
Implementing optimistic locking for concurrency control
During the execution of the workflow, multiple tasks might be running and completing in parallel. Upon completion, these tasks would trigger the updating of the dependency statuses of downstream tasks. If these tasks share the same downstream task, it could result in multiple attempts to update the same task record in DynamoDB. To handle such concurrent updates, implement optimistic locking by using a version attribute:
- When reading a task, capture its current version.
- When updating a task, include a condition that the version hasn’t changed.
- If the condition fails, retry the operation.
This approach prevents race conditions when multiple Lambda functions attempt to update the same task simultaneously. In this implementation, a custom version attribute and conditional updates are used rather than the @DynamoDBVersionAttribute annotation because you’re working directly with the DynamoDB API rather than an object mapper. You can view the implementation of optimistic locking when updating the lock state of a task on GitHub.
This pattern means that if two Lambda functions try to update the same task simultaneously, only one will succeed. The other function must retry with the updated version.
Managing task payloads with Amazon S3
To handle tasks that might have payloads or outputs that exceed the DynamoDB 400 KB item size limit, store the data in Amazon S3:
- When submitting a workflow, payloads are automatically stored in Amazon S3.
- The DynamoDB item stores the Amazon S3 path instead of the actual payload.
- When executing a task, the task function retrieves the payload from Amazon S3.
- Task outputs are stored in Amazon S3 and referenced in DynamoDB.
This approach means that you can handle payloads and outputs of any size while keeping the DynamoDB items small and efficient. You can view the implementation of how to automatically upload payloads on GitHub.
Error-handling strategies
The workflow engine is designed with robust error-handling capabilities. It automatically retries operations when transient errors occur by default, ensuring that temporary issues do not disrupt the workflow. For non-idempotent operations where retries could cause unintended side effects, the auto-retry behavior can be disabled on a per-task basis. The engine publishes detailed error logs to Amazon CloudWatch to facilitate efficient troubleshooting and root cause analysis. Additionally, it provides clear task status updates in DynamoDB to indicate any failures, allowing for prompt attention and resolution. To address concurrency issues, optimistic locking is employed to maintain data integrity even in high-traffic environments. You can view the error-handling implementation in the execute function on GitHub.
Performance considerations
To provide low latency and high throughput for the workflow engine, this solution uses several key optimizations:
- DynamoDB capacity planning – Use the DynamoDB on-demand capacity mode to automatically scale read and write throughput based on workflow volume. This eliminates the need to preprovision capacity and maintains cost efficiency.
- DynamoDB Streams configuration – DynamoDB Streams is configured with a batch size of 1 to minimize latency between task completion and dependent task execution. Although this increases the number of Lambda invocations, it helps workflows progress as quickly as possible.
- Parallel execution – The architecture naturally enables parallel execution of independent tasks with a parallelization factor of 10, configurable via Lambda event source mapping. The monitor function can invoke multiple execute functions simultaneously in an asynchronous manner, allowing workflows to take advantage of parallelism for faster completion.
Examples
The following two examples demonstrate how the orchestration engine works in practice: a simple mathematical workflow and a complex financial analysis workflow.
Example 1: Mathematical workflow
To demonstrate the core functionality of the orchestration engine, I’ve implemented a mathematical workflow that calculates the following expression using a series of tasks with dependencies:
The orchestration begins by first executing two mathematical operations simultaneously: one operation adds 5 and 3, and the other subtracts 3 from 6. These independent operations are dispatched simultaneously because neither relies on the result of the other. When both results are available—8 from the addition operation and 3 from the subtraction operation—the next operation divides the sum by the difference: 8 / 3 = 2.67. After the quotient is produced, the next operation subtracts 2 from 2.67, which equals .67. Finally, the multiplication operation takes the result of the previous step (.67) and multiplies it by 40, resulting in the final output of 26.8.
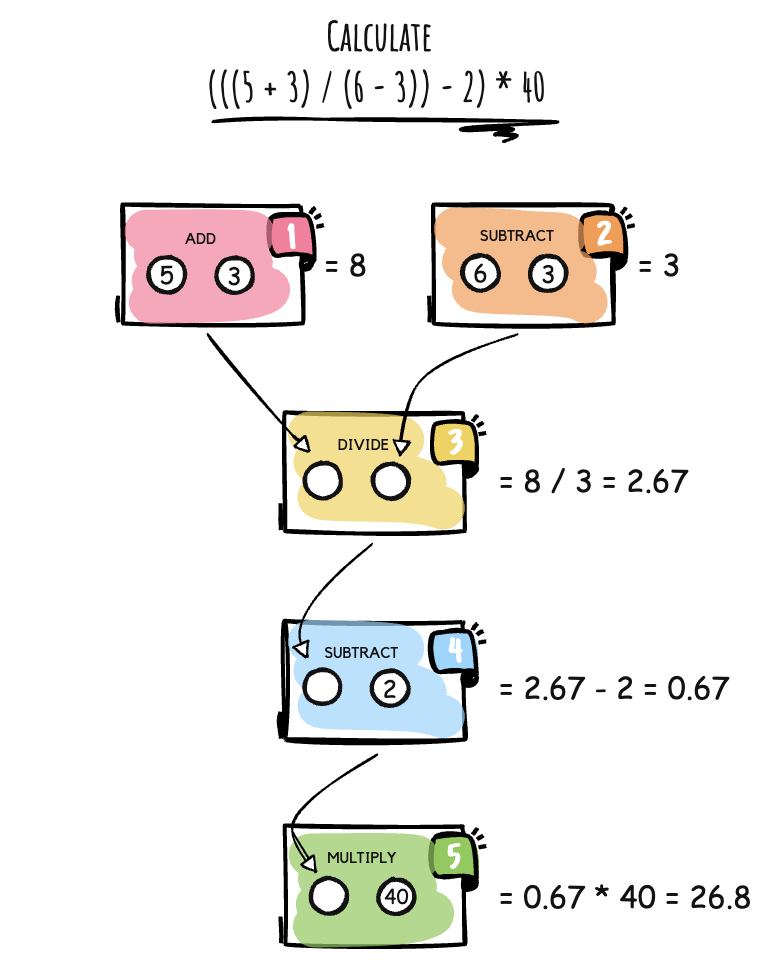
This mathematical workflow demonstrates:
- Parallel execution – Mathematical operations 1 and 2 execute in parallel.
- Dependency resolution – Operation 3 waits for both operations 1 and 2 to complete.
- Sequential processing – Operations 3, 4, and 5 execute in sequence.
- Dynamic inputs – Operations 3, 4, and 5 use the outputs of the previous tasks as inputs.
The result of 26.8 is returned as the workflow output.
Example 2: Stock analysis
To demonstrate the capabilities of the dynamic workflow orchestration engine, I developed a financial research AI agent designed to conduct sophisticated stock analysis. This financial research AI agent begins by accepting a natural language query from the user. Based on the specifics of the query, it dynamically constructs a tailored workflow. It then deploys specialized subagents to operate in parallel, each responsible for gathering distinct types of data. After these subagents complete their tasks, the financial research AI agent synthesizes their findings to deliver comprehensive and insightful analysis.
How the financial research agent works
This implementation uses Amazon Bedrock and the Strands Agents SDK to create specialized AI agents that can perform different types of financial analysis:
- General stock agent – Retrieves basic stock information and news
- Stock analyst agent – Gathers analyst recommendations, price targets, and revenue estimates
- Financial statements agent – Analyzes balance sheets, income statements, and cash flow statements
- Generic agent – Handles reasoning and response preparation without specialized tools
Workflow orchestration
When asked to “perform an analysis of AMZN,” the workflow agent initiates several tasks in parallel right from the start. The general stock agent is responsible for gathering detailed stock ticker information for Amazon (ticker symbol: AMZN), including the current price, market capitalization, price-to-earnings (P/E) ratio, and other key financial metrics. Simultaneously, the financial statements agent undertakes three parallel tasks: retrieving and analyzing the latest Amazon balance sheet (focusing on assets, liabilities, debt levels, and financial position), income statement (examining revenue growth, profit margins, and earnings), and cash flow statement (evaluating operating cash flow, free cash flow, and capital expenditures). At the same time, the stock analyst agent collects analyst price targets and recommendations, including consensus ratings and price targets, as well as revenue and earnings estimates for upcoming quarters and fiscal years. Meanwhile, the general stock agent monitors and gathers the most recent news articles about Amazon that could impact its stock performance. After the financial statements agent completes its three analyses, the generic agent consolidates these findings, analyzing Amazon’s financial statements collectively to identify key trends, assess financial health, and highlight any potential concerns. Finally, the generic agent compiles a comprehensive analysis of Amazon. This analysis draws upon the initial ticker data from the general stock agent, analyst insights and projections from the stock analyst agent, news from the general stock agent, and the consolidated financial statement review.
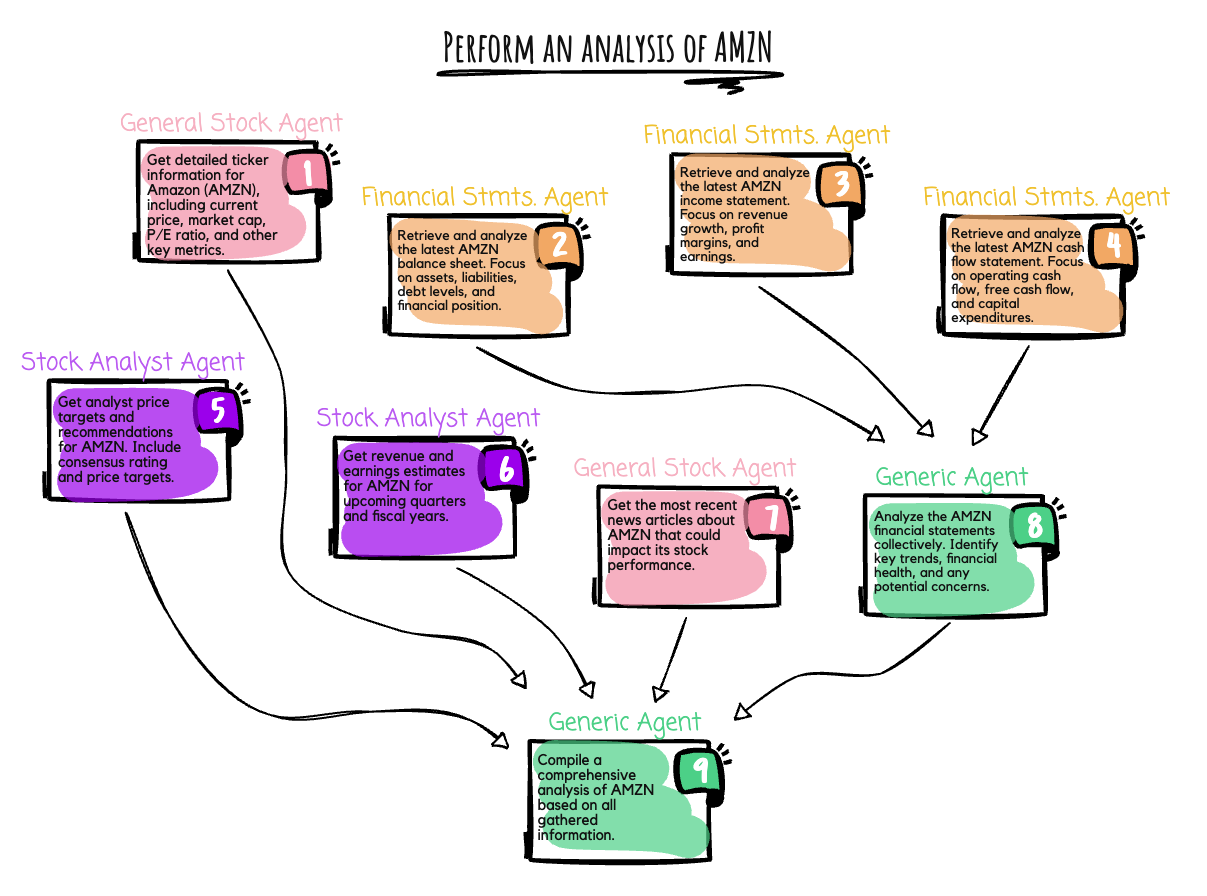
This workflow demonstrates several key capabilities of this post’s orchestration engine:
- Parallel execution – Tasks 1, 2, 3, 4, 5, 6, and 7 all execute in parallel.
- Sequential dependencies – Task 8 waits for tasks 2, 3, and 4.
- Fan-in pattern – Task 8 waits for three inputs (tasks 2, 3, and 4), and task 9 waits for five inputs (tasks 1, 5, 6, 7, and 8).
- Final aggregation – Task 9 combines all results into a final report.
The workflow is created dynamically at runtime, with dependencies defined for data gathering to happen in parallel before the final analysis.The following table shows the execution duration of each task (as mentioned in the preceding diagram).
| Task number | Task | Duration (in seconds) |
| 1 | Get detailed ticker information for AMZN including current price, market capitalization, P/E ratio, and other key financial metrics. | 64 |
| 2 | Retrieve and analyze the latest AMZN balance sheet. Focus on assets, liabilities, debt levels, and financial position. | 18 |
| 3 | Retrieve and analyze the latest AMZN income statement. Focus on revenue growth, profit margins, and earnings. | 102 |
| 4 | Retrieve and analyze the latest AMZN cash flow statement. Focus on operating cash flow, free cash flow, and capital expenditures. | 77 |
| 5 | Get analyst price targets and recommendations for AMZN. Include consensus rating and price targets. | 98 |
| 6 | Get revenue and earnings estimates for AMZN for upcoming quarters and fiscal years | 58 |
| 7 | Get the most recent news articles about AMZN that could impact its stock performance. | 29 |
| 8 | Analyze the AMZN financial statements collectively. Identify key trends, financial health, and any potential concerns. | 27 |
| 9 | Compile a comprehensive analysis of AMZN based on all gathered information. | 57 |
Without an orchestrator, the entire workflow would be executed in a sequential manner, and the total duration would be 530 seconds (8 minutes and 50 seconds). With the orchestrator, the total duration includes only the duration of task 3 (because it runs the longest among tasks 1–7), task 8, and task 9, amounting to a total of 186 seconds (3 minutes and 6 seconds). This is a reduction of 5 minutes and 44 seconds—a 65% improvement over sequential execution.
Deploy the solution
This blog post’s solution is available in the GitHub repository. To deploy it, navigate to the README.md of the repository to find the instructions to deploy the solution. Follow the steps to complete deployment.
The deployment process creates a DynamoDB table for workflow tasks, an Amazon S3 bucket for payloads and outputs, Lambda functions for task execution and monitoring, IAM roles with least-privilege permissions, and AWS Systems Manager Agent (SSM Agent) parameters for resource discovery.
Testing the deployment
After you deploy the solution, you can test it with the included examples:
- Run the mathematical workflow example:
- Run the AI agent workflow example:
These examples demonstrate the core functionality of the workflow engine and provide a starting point for building your own workflows.
Clean up
You will incur charges when you consume the services used in this solution. Instructions to clean up the resources are available in the README.md of the GitHub repository.
Conclusion
The dynamic workflow orchestration engine in this blog post demonstrates the power of combining DynamoDB and Lambda for flexible, event-driven workflow processing. By using these serverless technologies, this solution can handle complex, unpredictable workflows with minimal infrastructure overhead. The financial research agent example shows how this architecture can power sophisticated AI agent workflows, enabling parallel data gathering and sequential analysis in a flexible, scalable way.
I encourage you to explore the code in the GitHub repository, deploy the solution, and adapt it to your own use cases. This serverless, event-driven approach provides a foundation for building complex workflow applications that can evolve with your business needs.
If you’re interested in implementing this solution in your organization or have questions about the solution architecture used in this post, contact your AWS account manager or an AWS sales specialist.